In the previous article, we talked about E2E development challenges and overview of the E2E testing frameworks. Here we will talk about E2E Test Components, and we will cover:
- Specifications, Gherkin
- Runners
- Test data (volumes, import data with tests)
- Automation testing rules – more specifically FE rules
Specifications, Gherkin
Gherkin is a plain text language designed to be easily learned by non-programmers. It is a line-oriented language where each line is called a step. Each line starts with the keyword and end of the terminals with a stop.
Gherkin’s scenarios and requirements are called feature files. Those feature files can be automated by many tools, such as Test Complete, HipTest, Specflow, Cucumber, to name a few.
Cucumber is a BDD (behavior-driven development) tool that offers a way of writing tests that anybody can understand.
Cucumber supports the automation of Gherkin feature files as a format for writing tests, which can be written in 37+ spoken languages. Gherkin uses the following syntax (keywords):
- Feature → descriptive text of the tested functionality (example “Home Page”)
- Rule → illustrates a business rule. It consists of a list of steps. A scenario inside a Rule is defined with the keyword Example.
- Scenario → descriptive text of the scenario being tested (example “Verify the home page logo”)
- Scenario Outline → similar scenarios grouped into one, just with different test data
- Background→ adds context to the scenarios that follow it. It can contain one or more Given steps, which are run before each scenario. Only one background step per feature or rules is supported.
- Given → used for preconditions inside a Scenario or Background
- When → Used to describe an event or an action. If there are multiple When clauses in a single Scenario, it’s usually a sign to split the Scenario.
- Then → Used to describe an expected outcome or result.
- And → Used for successive Given actions
- But → Used for successive actions
- Comment → Comments start with the sign “#”→ These are only permitted at the start of a new line, anywhere in the feature file.
- Tags “@”→ Usually placed above the Feature, to group related Features
- Data tables“|”→ Used to test the scenarios with various data
- Examples → Scenario inside a rule
- Doc Strings– “”→ To specify information in a scenario that won’t fit on a single line
The most common keywords are “Given”, “When,” and “Then”, which QAs use in their everyday work when writing test cases, so they are familiar with the terminology. Here is an example of a simple scenario written in the Gherkin file:
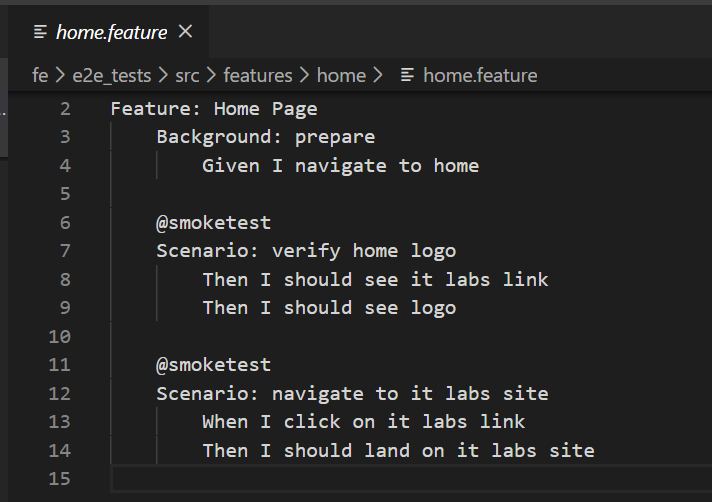
Once the QAs define the scenarios, developers, or more skilled QAs are ready to convert those scenarios into executable code:
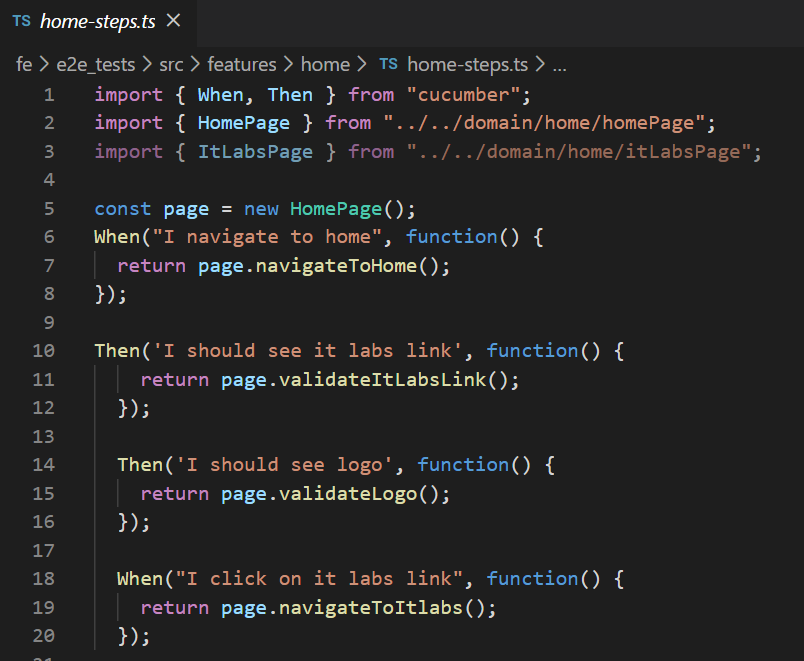
Using this approach of writing this type of test, teams can stay focused on the system’s user experience. The team will become more familiar with the product, better understand all the product pieces, and how the users will use it daily.
More examples can be found here https://github.com/IT-Labs/backyard/tree/master/fe/e2e_tests/src/features
Best practices
Several best practices can be taken into consideration when working with Gherkin (feature files):
- Each scenario should be able to be executed separately.
- Common scenarios should be combined in a data table.
- Steps should be easily understandable.
- Gherkin (feature files) should be simple and business-oriented.
- Scenarios ideally should not have too many steps. It is better if it’s less than ten.
- Titles names, steps names, or feature names should not be extremely large. The best case is 80-120 characters.
- Tests should use proper grammar and spelling.
- Gherkin keywords should be capitalized.
- The first word in titles should be capitalized.
- Proper indentation should be used, as well as proper spacing.
- Separation of features and scenarios by two blank lines.
- Separate example tables by one blank line.
- Do not separate steps within a scenario by blank lines.
Runners
Cucumber.js enables the writing of robust automated acceptance tests in plain language (Gherkin) so that every project stakeholder can read and understand the test definitions.
Implementation of those tests can be done using:
- Selenium
- Selenium + Nighwatch.js
- Cypress
Test Data
Test data is one of the main parts of the test environment, and it takes time to design the solution. In the following section, we will cover the options we have during the design phase and present an example solution.
The design of the solution needs to implement the following points:
- The test environment should support data versions.
- The test environment can be quickly restored to its original state.
- The test environment can be run on any operating system.
- Each user can change the data and promote it simply into the test environment.
Data Versions
Data versioning is a very important part of the test solution because it is how we will support data transition from one software version to the next one. The following section contains some of the options which we can use in our test solution.
Scripts
“Scripts” as an option can be used as part of maintaining the test data or test execution steps. Scripts can be of different types, for example, SQL, JavaScript, Shell, bash, etc… For example, maintaining database data can be done by adding a new script or incrementing a new database version script. JavaScript can be used when we want to enter data into the system via HTTP because JavaScript enables communication with the software API interface. Due to the dependency of the API interface, scripts should be maintained as the platform evolves.
Tests
E2E tests can be used as an option to fill data in the system, the same as scripts, before test execution or as part of maintaining test data. Using them as fill options before execution should be avoided because they are time-consuming to create, the complexity of maintaining them, and the possibilities they can fail, leading to false test results. However, they can be a good candidate for maintaining data for complex systems. For example, when we have a big team collectively working on the same data set, manual test data preparation can be done via text during the development phase, which can be repeated with small interventions depending on features overlapping functionalities.
Manual Data Changes
This option should be avoided as much as possible because it’s time-consuming, and there is no warranty that data is the same between two inserts.
Data Location
Data location is very important information during designing the test solution because data can be stored in various locations, such as database, file system, memory, or external system such as IDP, search service, to name a few.
Database
A database in software solutions can be a standalone or managed service. Each of these options gives us the pros and cons of writing, executing, and maintaining the tests.
Here are some of the challenges with a standalone database which we should solve:
- Advance knowledge of the tools to automate the processes of backup/restore data.
- Tools for these processes require appropriate versions. Example: backup made from a newer database version cannot be restored to an older database version.
- Tools may have conflicts with other tools or applications on the operating system itself.
Managed service as an option is solving version and tools issues, but from another side, they introduce new challenges such as:
- Snapshot/restore is a complex process; it requires scripts and appropriate knowledge to access the service
- They are more expensive if we have a different service per environment (to name a few environments: test; staging; production)
File System
Data can also be found on the file system where the software is hosted. Managing this can be challenging because of:
- The particular hosting Operating System, and simulating the same on each environment
- Variation of Operating System versions
- Tools used for managing the files
- Tools access rights
- (to name a few)
External Systems (Third-party systems)
External systems as Identity Provides (IDPs), search services, etc .. are more difficult to be maintained because they have a complex structure and are async. Once configured, these systems should not be part of test cases but only used as prepared data. The data usually is prepared by manual process. Example: The signup process, which requires an email or another type of verification, should be avoided because many systems are included through that test path. Thus, we don’t know how long it will take to be sent, received, and verified. Additionally, those systems can be upgraded and include other user flows, which potentially will break our tests.
Docker Volume
Docker volume is one of the options for storing data used by Docker containers. As part of the testing environment, volumes must satisfy all the requirements mentioned above because they are portable.
The E2E test environment has two variables, docker version and operating system where tests are run or maintained. We should provide scripts and steps for each target operating system setup. Then provide info on what is the minimum Docker version for commands to work.
Volume portability requires the following steps for maintaining data inside:
• Volume restore from latest test data version
• Volume must be attached to a running container
• Developers perform data changes
After data changes or container version upgrades, volume exports should generate a new version and be shared in a central place.
This process of maintaining data must be synchronous, which means only one version can be upgraded at a time due to the inability to merge volumes. If this rule isn’t followed, we will incur data loss.
Example – Docker compose with volume:
api-postgres:
image: postgres:12.2
container_name: api-postgres
environment:
– “POSTGRES_PASSWORD=deV123*”
– “POSTGRES_USER=dev”
– “POSTGRES_DB=sample”
volumes:
– api-postgres:/var/lib/postgresql/data:z
ports:
– “5444:5432”
networks:
– sample
networks:
sample:
name: sample-network
driver: bridge
volumes:
api-postgres:
external: true
Git: https://github.com/IT-Labs/backyard/blob/master/api/docker-compose.yml
Docker volume central location: https://github.com/IT-Labs/backyard/tree/master/backup Note: Git should not be used because the volume file is big , and GIT complains about that.
Volume backup command:
docker run –rm –volumes-from api-postgres -v \/${PWD}\/backup:\/backup postgres:12.2 bash -c “cd \/var\/lib\/postgresql\/data && tar cvf \/backup\/api_postgres_volume.tar .”
Git: https://github.com/IT-Labs/backyard/blob/master/volume_backup.sh
Volume restore :
docker container stop api-postgres
docker container rm api-postgres
docker volume rm api-postgres
docker volume create –name=api-postgres
docker run –rm -v api-postgres:\/recover -v \/${PWD}\/backup:\/backup postgres:12.2 bash -c “cd \/recover && tar xvf \/backup\/api_postgres_volume.tar”
Git: https://github.com/IT-Labs/backyard/blob/master/volume_restore.sh
Automation Rules
• Test Architecture and code must follow the same coding standards and quality as tested code. Without having this in mind, tests will not be a success story in the project.
• Place your test closer to FE code, ideally in the same repository. This way, the IDE can help with refactors.
• Follow the same naming convention ex: classes, attributes as your FE code is using. Find element usage will be easier.
• Introduce testing selectors or use existing with following order id > name > cssSelector > element text> > … > xPath . If your selector is less affected by design or content changes, test stability is greater.
• Optimize your test time by manipulating the thread using framework utilities such as wait.until instead of pause test execution.
• Use central configurations for your browser behavior, enabled plugins, etc. This is to avoid differences in UI when it is executed in different environments or browser versions.
• The test should not depend on other test execution.
• Pick wisely what you will cover with E2E tests and what is cover with other types of testing. E2E Test should not test what is already tested by other tests, for example, unit test, integration test, to name a few.
• The test should be run regularly and maintained.
Conclusion
There is no general rule on what components you should choose to guarantee E2E testing success. Careful consideration, investigation, and measures to create the right solution should be engaged.
It depends on your unique situation. For example, the cases you have, the environment you are using, and the problem you want to solve. In some cases, you can go with one test runner; in others, you can use another test runner, and all of that depends on the supported browsers for your application. Do you need support for multi-tabs in your tests or to drive two browsers simultaneously (a considering factor in this is Cypress does not support multi-tabs and two browsers at the same time)? Or do you need parallel testing? These are just a few factors and situational conditions that may come up in consideration.
When it comes to using Specifications (should we use them or not), Gherkin and Cucumber are more or less the same. Writing feature files using Gherkin seems simple at first, but writing them well can be difficult. Many questions pop up and need to be considered, for example:
• Who should write the Gherkin specification? BA or QA?
• How much into detail should we go, and how much coverage we should have?
o Note: If you need high test coverage, it’s better not to use Gherkin and Cucumber
• Yes, scenarios can be easily read by non-programmers, but how much time does it take to write them?
• How easily maintainable are your tests?
When it comes to test data, you can go with data volumes in some cases, but how will you solve the data volume if you use a serverless application?
On the other hand, if you are using AWS, how will you solve the test environment’s problem and test data?
Usually, if you are using an on-premise or local environment, you can go with data volumes since it is more feasible and easier to maintain. If you are on the cloud, we should go with something like scripting – tests, snapshots, database duplication, database scripting, to name a few.
And finally, on top of all mentioned above, you must measure your team’s capabilities that will work on those tests.
E2E testing helps ensure the high quality of what’s delivered. It’s an important approach to reduce disappointment to the end-user, reduces bugs being released, and creates a high-quality development environment. The ROI will speak for itself.
Aleksandra Angelovska
QA Lead at IT Labs
Jovica Krstevski
Technical Lead at IT Labs