Introduction
With the rise of Large Language Models (LLMs), the idea of building intelligent chatbot solutions is very popular, both for internal and external usage. The idea behind these intelligent chatbots is to use certain data (privately or publicly available) to answer questions and assist people in finding relevant information and answers more efficiently.
In this article, we will discuss the architecture and development process behind our Intelligent Chatbot Solution. We will explain its use cases, the technology stack used for building the Chatbot, the different approaches that were considered, the architecture, and the challenges faced along the way.
Use Cases
The Intelligent Chatbot is a solution whose main objective is to provide relevant information and answer questions about knowledge, policies and intelligence that are widely available to all users. To be more specific, the Chatbot can assist users with various processes documented within the user’s knowledge base. This can range from providing basic information to assisting in the procedures available in the users’ knowledge base data.
Technology Stack
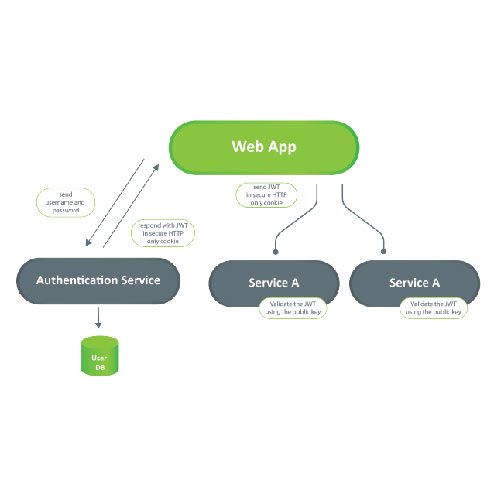
The Intelligent Chatbot Solution follows the REST API architectural style. It consists of a backend module, written in Python FastAPI, and a user interface module, written in React JS. The backend module has various connectors for data storage and is also connected to an LLM instance and an Embeddings model.
On a high level, the user uses the user interface to ask a question, which is sent as a HTTP request to the backend module. The backend module processes the request, sends it through the LLM and returns the answer to the user. The whole question-answer processing procedure through the LLM is done with LangChain (we will talk more about this later).
Adapting an LLM to our needs
The most crucial part of this solution is adapting a given LLM to its specific needs. The idea behind the Intelligent Chatbot Solution is to be able to provide clear and correct answers to questions from the available data based on a given context. Moreover, to improve the user experience, we wanted to tweak the tone of the generated texts to be friendlier while still providing factually correct answers. To accomplish all this, we investigated several different options, but the focus was on Fine Tuning and Retrieval Augmented Generation.


Retrieval Augmented Generation (RAG)
One approach when developing an Intelligent Chatbot is to add your data to an already existing model, a process famously known as fine tuning. The problem with this approach is that fine tuning is not a one-time thing. As your document base grows you need to keep retraining the model, and that part can be very costly and time-consuming.
On the other hand, Retriever-Augmented Generation (RAG) stands out as a revolutionary approach when your application requires seamless integration with external data sources and offers a lot of advantages over traditional fine-tuning methods. This approach dynamically retrieves information, ensuring that responses are always up-to-date and reflect the latest insights.
In practice, RAG operates by formulating a user’s query, scouring large databases to retrieve pertinent information, selecting the most relevant data, and finally generating a response informed by this external knowledge. This makes RAG particularly effective for question-answering systems where current and reliable facts are paramount, ensuring the responses are plausible and factually accurate.
With its retrieval-before-response architecture, RAG significantly mitigates the risk of “hallucinations” by prioritizing factual content from external sources, thereby enhancing reliability and trustworthiness.
It is very flexible, as its reliance on real-time data retrieval diminishes the need for extensive training data, making it an ideal choice for applications with limited or evolving datasets.
In dynamic data environments where information undergoes frequent updates, RAG, with its real-time data retrieval mechanism, seamlessly adapts to changing data dynamics, ensuring continuous relevance and accuracy.
Regarding transparency, RAG offers a prominent level of transparency and accountability by tracing responses back to specific data sources.
In conclusion, the choice between RAG and fine-tuning hinges on the specific requirements of your LLM application. While fine-tuning excels in certain scenarios, such as stylistic alignment and domain-specific nuances, RAG offers unparalleled advantages in applications requiring dynamic access to external data and enhanced transparency. By carefully evaluating factors like scalability, latency, maintenance, and ethical considerations, businesses can effectively leverage either approach to optimize their LLMs for maximum efficacy.

LangChain
In this solution, LangChain is used as a framework for the whole RAG process. LangChain is new but has various integrations with different cloud services and is constantly updated with new features.
For the retrieval process of RAG, we use LangChain to create an in-memory vector store. LangChain provides the data that we want to include in the knowledge base. Depending on the type of document the user offers, it can be loaded by different document loaders. Some examples include TextLoader, CSVLoader, PyPDFLoader, AzureBlobStorageFileLoader, and others. After loading the documents, Text Splitters are used to break large documents into smaller chunks. This is useful for both indexing data and passing it to a model since large chunks are more challenging to search over and will not fit in a model’s finite context window. An important part of the quality of the answers is the quality of the data and whether it is preprocessed.
After that, the chunks of each document are passed through the embeddings model (Azure OpenAI Embeddings in our case) and the vector embeddings are saved in a vector store (FAISS, Chroma, Lance). The good thing is that each chunk is connected to a document, so when a certain chunk is used as context for answering a question, it can be traced back from which document that chunk comes.
For the whole question-answering process, we use LangChain to create a Conversational Retrieval Chain that processes all user questions to generate the Chatbot’s response. The prompt is an important part of the generation process, which defines the Chatbot’s behavior. In the prompt, we define the response tone and the Chatbot’s restrictions. In our case, we restrict the chatbot to answering only questions related to our data. Moreover, if there is no relevant data available for the given question, we return a predefined answer (we restrict the chatbot from returning a randomly generated answer based on some loosely connected context).
The Conversational Retrieval Chain’s temperature hyper parameter (a floating-point value between 0 and 2) is closely related to the quality of the answers that the chatbot provides. The temperature defines the level of creativeness that the chatbot will use to generate the answers. If the value is very low, the answers will sound very artificial, without any human tone. If the value is very high, the Chatbot may generate answers that do not correspond with the information provided in the context. So, it is essential to tune the temperature of the chatbot based on the needs of the use case. Usually, this is done by experimenting with different values and picking out the one that suits the most.
For the Chatbot to be able to keep the conversation going, it needs to keep track of previous questions and answers. To accomplish that, we use LangChain’s Conversational Retrieval Chain, which is fed the incoming question, the chat history connected to that user (via session), and the predefined prompt. The chain processes the data and formulates one standalone question based on the prompt, the new question, and the previous conversation.
This standalone question is embedded using the same embeddings model and a vector similarity search is run on the vector store. Based on the selected metrics (top N similar documents or similarity threshold), the vector store acts as a retriever and returns the relevant documents. If no relevant documents are found, the Chatbot answers with a predefined message explaining that no data regarding the specific question is available.
After the relevant documents are retrieved, along with the standalone question, they are sent to the LLM (Azure OpenAI GPT 3.5 Turbo in our case). The LLM simply looks at the question, the prompt and all relevant context and formulates the final answer. In the end, we customize the answer a bit by providing a list of the relevant documents used to answer that question so that the user can find more information if needed. Finally, the initial question and the generated answer are stored in the chat history so that they can be used in the upcoming questions asked by the given end user.

BE Architecture
As we mentioned before, the backend module is created as a REST API service. The API has endpoints, which are grouped into routers. Each endpoint processes a different type of request through the services, which encapsulates the project’s business logic.
It is important to mention that these services are initialized upon starting the backend module. During this initialization process, the module creates the Conversational Retrieval Chain and the in-memory vector store necessary for the question-answering process to work. The module uses an in-memory FAISS vector store. For faster startup, we keep an up-to-date instance of the vector store. Every time the module is started, it first looks up an existing instance and loads the data from that instance. If there is no existing instance, it creates the vector store using the knowledge base provided.
Once the vector store is initialized, it is used as a retriever in the Conversational Retrieval Chain, built around a customizable prompt in which the Chatbot’s tone and other capabilities are configured.
After the Conversational Retrieval Chain is initialized, the API is ready to accept incoming requests. Besides the question answering request, the API has endpoints for providing feedback regarding a given answer from the Chatbot, uploading new files to the knowledge base, and removing files from the knowledge base.
Another important point to mention is that when the vector store is created, or when a document is inserted/deleted those changes are reflected both on the in-memory vector store and on the vector store instance that is used for faster startup.

Testing and Hyper Parameters Tuning
For RAGAS testing (framework for evaluating RAG pipelines) to be performed on the chatbot, a dataset with questions and their corresponding correct answers is required. In our implementation, we have a functionality that allows the end users to rate a specific answer as either good or bad. That rating, along with the question and the answer are stored in a database. Once a large amount of data is collected in the database, it can be used for testing the Chatbot’s performance and tweaking its hyper parameters to improve its accuracy and reliability.
Several hyper parameters are important to look at. First, the Conversational Retrieval Chain’s temperature parameter mentioned earlier. By tweaking the temperature, we can make the answers creative, which could improve or worsen the Chatbot’s performance for the specific use case.
Next, the chunk size and chunk overlap parameters should be fine-tuned based on the quality of the data available in the knowledge base. Based on the data, we may either need chunks of bigger size, containing more information in a single chunk, with overlapping words between the chunks, or smaller chunks, with less to no overlap between them. Again, there are no strict rules, and the best way to fine-tune these parameters is to experiment with different values and evaluate the Chatbot’s performance.
Lastly, there are several ways of determining which documents are relevant to the given question. We can use a Top N similarity search method, which does not consider the similarity level between the question and the document. It just takes the N documents with the highest similarity score to the given question. In this case, the number of documents used (N) is the hyper parameter.
However, this way, we can end up providing irrelevant context to a given question. To avoid this problem, we use a Similarity Score Threshold, which filters the documents based on the level of similarity to the given question. This way, if there are no documents similar to a given question, the Chatbot will return a predefined response instead of trying to answer a question based on irrelevant context.
Challenges
One challenge that we had was the compatibility issues between LangChain and different Python libraries and modules. Trying to find out which LangChain version would work the best for us and updating our code that used deprecated functions was an ongoing process throughout the development of this solution.
Another challenge was the security issues and the possibility of sensitive data leakage through the LLMs. Luckily, Azure OpenAI provides confidentiality by starting up a private LLM instance that encapsulates the knowledge base data from unauthorized access.
The most interesting challenge was finding a way to deploy the whole solution. There were issues with containerizing the BE module because it uses many dependencies and modules that had compatibility problems. In the end, we created one stable base docker image that included all the dependencies and modules, and we used that image as the base on which the BE module image is built.
Conclusion
An intelligent chatbot solution can be an extremely helpful tool that can provide accurate and useful information to users. It can improve the efficiency of sharing resources, documents, information, and policies without manually searching through them. Although this solution is built around RAG architecture, it is essential to thoroughly research all available options and pick the most suitable for the specific use case. Moreover, since generative AI is developing quickly, it is crucial to follow the latest trends and experiment with different approaches.