There are many types of users using Social Networks, and we are not talking small numbers here. Everything from end-users like you and I, to administrators, and all way through to advertisers. With millions of users using these platforms, you can easily imagine how they can become very demanding from a software and hardware perspective. It’s not an easy system to get in place and maintain. This makes the subject of social networks quite intriguing. Let’s dig a little deeper into the requirements and explore them further.
1. Requirements
Constant change – Change is the only constant, and social networks are not immune from the innovation storm that we all operate in. If any software doesn’t change, renewing itself in some way, it’s users simply lose interest. Social networking platforms are very demanding in this area; they need to adapt and change all the time. They steal ideas from one another alongside innovating with new ones. They constantly experiment, trying out ideas, applying them to small populations of users or user groups. Sometimes it creates desirable results, where the design is taken forward and published to the world.
High performance – Ten years ago, if you made some requests on an application, and the results returned within five seconds, that would have been acceptable1. Granted that some users would get impatient and annoyed, but not everybody. Nowadays, if requests last longer than a second, people will lose interest in using the application2. Having good performance is crucial with the modern human’s attention span, especially for social networking platforms. Simply put, high performance is all-important.
Easy UX – The next important requirement is being able to navigate the platform with ease. Being able to find your way around within the application is an essential aspect of user experience3. Not being able to see where you are, how you can continue, and how you can do the things you want to do, is something that will push users away from this site.
There are many types of users with their unique requirements and ways of using the platforms. Firstly there is the end-user. Like most of us reading this, we are end-users of social networks, and we expect everything already discussed above to happen. Next, there are advertisers. Advertisers are a crucial part of these platforms. They are the main revenue engine for social networks, so they are not easily ignored by the business. Finally, there are the page admins. A case in point is Facebook, where you have pages that you want to administer. For this, you need some special credentials and rules and whatnot. There are also some other features regarding the usage, but focusing on the abovementioned is enough for now.
2. Change and evolve
Social networking platforms are fine as they are. Still, we, the architects, are expected to do the architecture at the very beginning and have that same architecture remain as long as the social network remains alive. For example, Facebook has been live for more than 15 years, designing something at the beginning to withstand the changes of time is practically impossible.
If we make some analogy between Waterfall and Agile as project management types, we can say that, under the Waterfall approach, you are asking for all the requirements to be set at the beginning. Once you get all the requirements, once you have all the documentation, etc., it’s easy for you to follow the project and do what needs to be done4.
In the Agile world, it’s very different. You cannot simply require all those things upfront. You must adapt to never-ending changes every iteration. So, if the requirements are constantly changing, should the architecture also change? Can we make it possible for the architecture to evolve together with the requirements5?
Before we dive into that, to create context around what we are discussing, we will cover some important information to help the discussion.
2.1 Architectural types
Let’s discuss what architectural types there are.
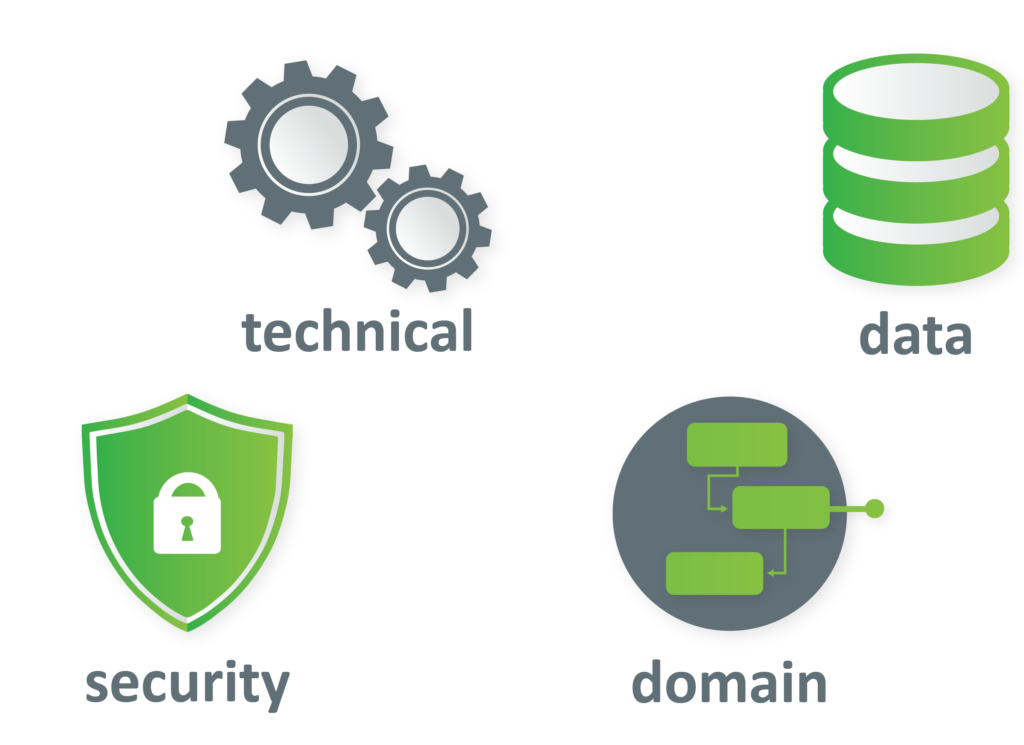
Technical architecture type – What does this mean? This is in the realm of software engineers and developers. It includes frameworks, different libraries, connection types between classes, and all things technical related to the platform.
Data architecture type – This architecture focuses on everything that’s related to data. It can be database schemas, table layouts, any kind of data redundancies, replica servers, etc.
Security architecture type – When we discuss the security architecture, we are thinking about security measures, legal compliance, any guidelines that need to be taken care of.
Domain-Driven architecture – Probably one of the most recently discussed architecture types. Domain-Driven architecture focuses on the bounded context. A bounded context is a group of functionalities that work together, and only a few of those properties are exposed to the outside world. The idea behind the bounded context is that everything that is done inside this context remains the same and doesn’t break the logic of anything else outside of that context.
So we have covered the architectural types. Let’s now build up the picture further with architectural models.
2.2 Architectural models
N-tier monolith – The first well-known architectural model is the layered, or monolith-architectural model. Some call it the n-tier architectural model.
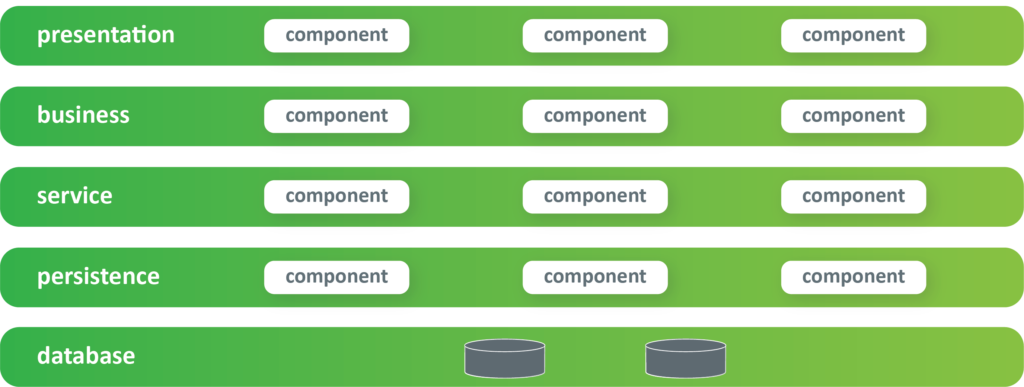
In the layered architectural model illustrated above, we have five different layers. In the ideal world, you should be able to change anything in any of those layers, and everything will work perfectly without affecting the behaviour of the others. For example, changes in the service layer have no impact outside оf itself. In a perfect world, you don’t need to touch any of the outside layers, and the application would continue to work correctly. However, experienced developers of this type of architecture are aware that this is not quite true, if at all.
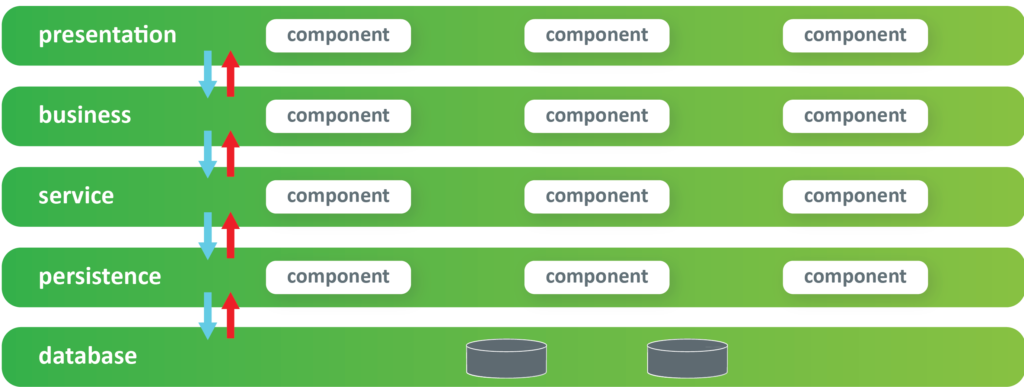
The second important thing about this architecture is that we have constant flow through the layers, up and down. The requests go from the topmost layer to the bottommost layer, and the responses go back from the bottommost layer to the uppermost layer. However, from time to time, some of these layers are not relevant for every request6 (even not needed in most cases). For example, in the illustration below, the service layer is not required and is therefore skipped.
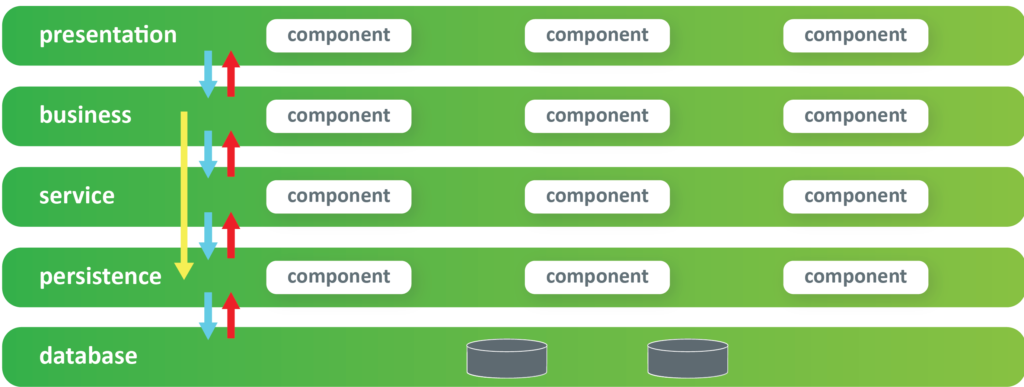
This notion is known as sinkhole anti-pattern architecture, where one of those layers is not required in most requests7. In this case, we simply skip this layer. Skipping layers, and by accepting this type of work, we have a notion of creating as many connections as necessary, and as tighter of coupling as needed, which is generally very bad for the architecture.
The next thing for consideration is the architecture. Let’s assume that we would like to change some of the domains in the application. For example, “feeds” feature that most of the social networks have nowadays. If we want to change a “feed” feature, we need to make the changes in all of these layers. That being said, the domain aspect of this application is not very well defined. This type of architecture is something that we don’t want to use if we are concerned about Domain-Driven Design. If this is not okay, the next thing that we do is to try to separate all these functionalities into separate domain models.
Let’s discuss models through an example. We have one functionality for the “feeds” in the first domain model. We have another functionality for the “ads”, in the second domain model, and everything else in the third domain model. This is okay as a concept. The only thing that is problematic here is the database. Let’s imagine that we have a 10+-year-old solution; it still lives and is being maintained and expanded. The database itself has vast amounts of tables and connections, are holding millions of records. It’s not easy to go to the database designer (or anybody that cares about the database and its data) and ask of them to simply split the database in a way the new architecture would prefer it to be divided. In practice, this is very hard, and in many examples, close to impossible when we take into consideration the time and budget needed. So, even though the Domain-Driven design is a good approach, we still have tight coupling when it comes to the database.
Next, a similar approach to this is microkernel architecture. In the context of this article, when we speak of microkernel architectures, we are referring to plugins8. An important point here is that these plugins are not focused on domains, but services. For example, browsers have microkernel architectures. You can put all different plugins in a certain browser, but all those plugins are service-based. They are rarely grouped regarding the domain.
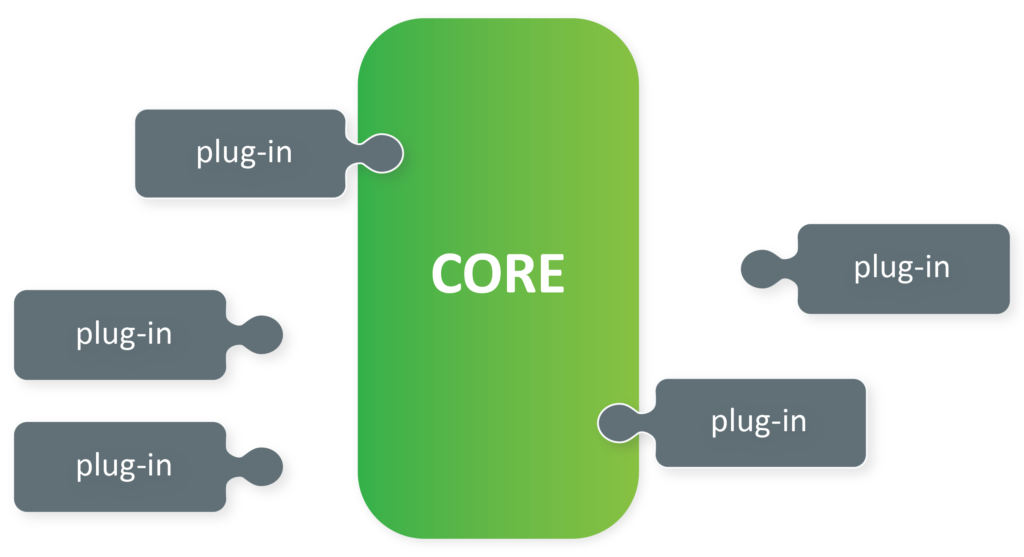
Let us discuss a very well-known micro-services architecture. Many of us are aware of this architecture. It represents the ability to separate the domains as much as we need. With all domains being separated, it allows us to expand this architecture in multiple domains9. This is a good architecture to take as a Domain-Driven (Design) architecture.
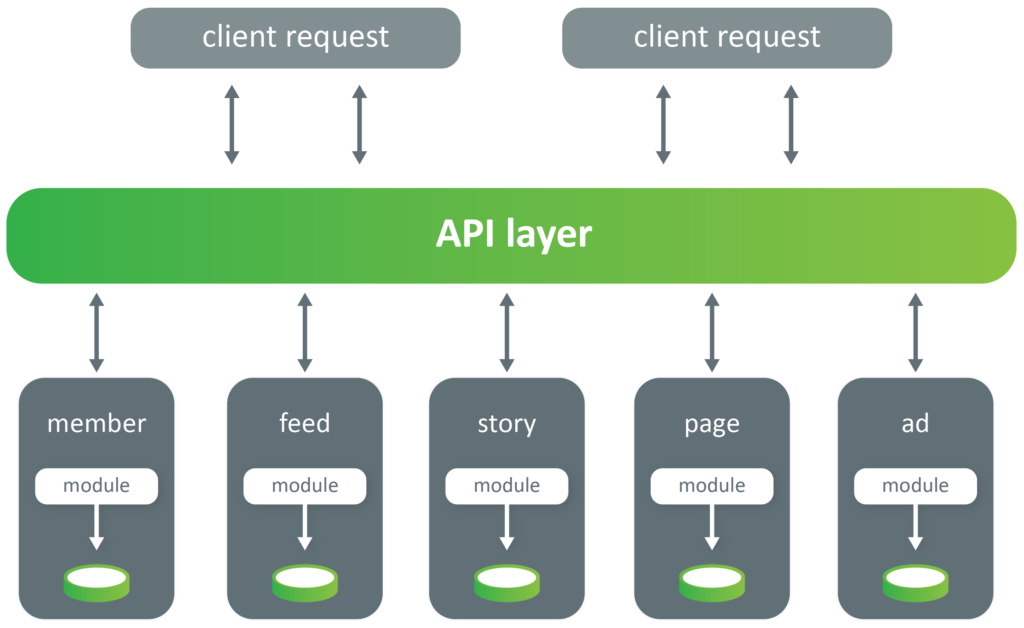
Now, on top of the microservices approach, we can build something similar to HATEOAS architecture. It stands for “Hypermedia as the Engine of Application State”, where each response carries within itself other hyperlinks that will guide you further through the application10. This application can be built using microservices architecture, but it’s more of conceptual architecture rather than a technical one.
3. Practical Aspects
Let’s discuss a little bit about the practical aspects of architecture. When we consider social networks, as previously mentioned, we need to be able to change, adapt, and upgrade the architecture constantly. For this, we need to take care of several things.
3.1 Dimensions
We need to identify and prioritize the dimensions that are important to the outcome we are trying to achieve. There are many dimensions to any architecture, and it’s imperative we prioritize what is most important to the platform. Examples of dimensions are audit-ability, performance, security, data, legality11, and scalability12. By determining these dimensions, we can focus on what is necessary for our application. Once we have determined priority, we can then focus on how to measure and constantly improve these dimensions. We do this by using so-called “fitness functions”.
3.2 Fitness functions
Fitness functions are tests for non-functional requirements in the application13. Implementing these fitness functions will help us determine the cost of maintenance. Let’s initially discuss some possibilities for fitness functions.
If performance is important to us, we need to implement functions that, with each delivery, will test our application for its performance. If, for example, a page request takes longer than one second (and one second is our limit), we become aware that there is a problem. We do not push the release live; instead, we resolve the issue there and then.
The second fitness function might be about environmental elasticity. Most of us are using Cloud environments, and we are aware that in a Cloud environment, there are possibilities to extend your fleet of servers in an elastic way. Whenever there is a huge amount of requests, the Cloud can, by itself, raise new servers, new instances, or maybe new docker instances (whatever is necessary). That way, it manages to service all requests. The question arises, are those instances raised when we need them? How can we test that? A very simple way to test the elasticity of a cloud environment is to establish a test environment on the Cloud, prepare load tests, and run them as many times as we need. This allows us to monitor and measure the instances of how they behave in specific scenarios and conditions. If, for example, we have 4,000 requests, and we are expecting a new instance to be raised, you can see if things transpire as planned. If the application doesn’t behave correctly, we can act to remedy the issue accordingly. The same goes for bringing down instances. When we reduce the number of requests, we observe to see if the application behaves as it should. If it doesn’t, then we know we need to make changes.
The next type of fitness function is to create a listener inside your application. The listener indicates what functions and methods are used in an application. If we are building code for 10+ years, we have lots of legacy code that most probably doesn’t even need to be there anymore. If we have any type of fitness functions that test what methods are executed and those that are not, and we have a report of that, we can easily clean our code of unnecessary items14.
Another example could be around accessibility for people with disabilities. Each time we push a release to the public, we can run the accessibility tests15. If there are any incorrect pages displayed which don’t fully support what our user needs, we can simply roll back the deployment and correct those issues.
The last one we will discuss here is the ability for all services to fail gracefully. We all know what this means. There are tons of services in our microservice application, and we must be aware of how those services function. Some of those services will most likely break16. When this happens, we need to be prepared so that we know what’s going on in our architecture and how our application is behaving.
3.3 Feature toggles
The article so far has discussed that we need to be aware that our architecture will evolve and change constantly. So, how do we get prepared to welcome the changes? How do we present small types of deployments to certain parts of the solution, and to test them?
This is where feature toggles come into play. The feature toggle set is a kind of functionality where we can switch on and off different features depending upon when we need them, how we need them, etc. These feature toggles are quite good for several things that we need to do17.
One feature toggle is A/B tests. We have tons of services, and we should be able to do A/B tests for all those services. A/B test allows us to make a comparison between two or more different implementations on a single service or functionality. Ones we are satisfied with one of the implementations, we should be able to toggle off the other ones or just simply remove them if needed.
Another one is canary releases. Canary releases are small chunks of releases for only a certain group of users. For example, when we have new functionality in our application, and we don’t know whether the end-user will accept this functionality. Using the approach of the canary releases, we can create a new service and toggle this functionality only a specific set of users. A few examples to illustrate this could be employees in our office alone, or maybe for only one geographical state. This way, this user group can be testers for our new functionality. Since these functionalities will be tested on a production environment, with the testing group being the actual test users, this can be described as the best testing group an application can ever have ?, although I don’t recommend doing this too often18.
Another possibility where we can use this fitness function is in experimentation. Again, if there is something new that we would like to experiment with, and see how it is received, or will it work correctly, then we can use fitness functions to toggle the functionalities of the code.
3.4 Maintenance
One important thing besides monitoring the services is that we must be able to track the routes between them. Why is this routing important? The monitoring of them is important because we will know when one of the services stops, which implicitly means that no other services are routing to it. If any are no longer being routed to, they should automatically be removed from the ecosystem. The business needs should determine the conditions and resulting response to whether a service is being routed to or not. This is another example of a fitness function.
4. Conclusion
All of what we have discussed in this article helps us manage changing requirements better. Thus, allowing architects to modify and change our architectures in unison with changing conditions. We should be able to evaluate the impact of any modifications quickly, and decide whether to push changes forward, fine-tune them, or roll them back. As you can see, all these approaches allow for an evolutionary architecture for our software.
So, to do a little recap… To be able to embrace the future of our architecture so it can change and evolve, initially, we need to design it in the Domain-Driven fashion. The second thing is that we should identify our priorities. We cannot test and monitor everything. Based on our priorities, we should be able to create fitness functions, at least for the most important cases. Besides other things, being able to develop fitness functions will also allow us to measure the cost of maintenance more easily. The price of maintenance in terms of effort, time, and money is one of the most important things for a software architect. Feature toggles are a good tool to deploy small parts and to test them, see how the application behaves and how the end-users receive them, and then depending on needs, turning the functionality or the service on or off. As for maintenance, being able to know how services are performing and which are no longer used will allow us to keep the solution clean and neat, thus enabling more efficient maintenance.
By: Ilija Mishov, Co-Founder of IT Labs
Co-author: Erin Traeger, Business Analyst at IT Labs
_____________________________
1 In 2011 perhaps 35% abandon by the time it’s 10 seconds, 25% at 4 seconds, which indicates a higher tolerance. https://royal.pingdom.com/the-software-behind-facebook/
2 In 2016, some sites had an INCREASE in load time whilst trying to offer a more immersive experience. This hurt their sales. Included is a statistic “Split second” for Nordstrom, which says, “Nordstrom saw online sales fall 11% when its website response time slowed by just half a second.” Note that at that time, they believed 2.5 second load time was ideal. https://www.bbc.com/news/business-37100091
As of 2018, the bounce rate was 32% for 1-3 second load time – see infographic at https://www.thinkwithgoogle.com/marketing-resources/data-measurement/mobile-page-speed-new-industry-benchmarks/
3 Overall, UX is very important. But interestingly enough, in 2018, research conducted amongst mobile users indicates millennials not only “are more likely to blame a slow learning curve on the app itself. They won’t keep using an app if it frustrates them or doesn’t fulfill their needs.”, but also “Suprisingly, millennials may be attracted to Snapchat because its design is more complicated and less intuitive than other apps.” Further within, it argues that Snapchat is an example of “shareable design”, which “requires users to learn by watching others.” – https://themanifest.com/mobile-apps/what-makes-social-media-apps-successful
4 NGuru99 – Waterfall can have phases, though, so changes do occur. https://www.guru99.com/waterfall-vs-agile.html
5 “On an agile project you assume that you cannot fix the requirements of the system up-front. As a result having a detailed design phase at the beginning of a project becomes impractical The architecture of the system has to evolve through the various iterations of the software. Agile methods, in particular extreme programming (XP), have a number of practices that make this evolutionary architecture practical.” – https://www.martinfowler.com/articles/evodb.html
6 “Challenges” section backs up Ile’s statements about layers that aren’t needed for every request, “It’s easy to end up with a middle tier that just does CRUD operations on the database, adding extra latency without doing any useful work.” – https://docs.microsoft.com/en-us/azure/architecture/guide/architecture-styles/n-tier
7 What architecture sinkhole anti-pattern is – see 2nd and 3rd paras under “Considerations”. It recommends that if 80 percent (from the 80-20 rule) are simple pass-through processing, then you may want to consider making some of the architecture layers open. https://www.oreilly.com/library/view/software-architecture-patterns/9781491971437/ch01.html.
Another mention of sinkhole antipattern – https://medium.com/@priyalwalpita/software-architecture-patterns-layered-architecture-a3b89b71a057
8 The article https://medium.com/@priyalwalpita/software-architecture-patterns-microkernel-architecture-97cee200264e in the “Pros” and “cons” sections gives reasons this wouldn’t be ideal for a high-traffic social network. Explains that there is the core and then plugins, with core containing minimal functionality needed to run the system. Also explains that generally not the ideal pattern to be used in high-performance applications, not highly scalable, and requires a thorough analysis of the design before implementation.
9“Microservices” section –Also discusses advantages that correlate with what you’d want on a social network – “ability to scale only microservices needing to be scaled.” “Easier to rewrite pieces of the application because they’re smaller and less coupled to other parts.” As well, it says it’s ideal for “applications that would become very complex if combined into one monolith.”, which for social networks always needing to push out new features, this would happen. – https://dzone.com/articles/software-architecture-the-5-patterns-you-need-to-k
10 Good explanation of what HATEOAS is, why you’d want it, such as under the section “Why do we need HATEOAS?”: “The single most important reason for HATEOAS is loose coupling. If a consumer of a REST service needs to hard-code all the resource URLs, then it is tightly coupled with your service implementation. Instead, if you return the URLs it could use for the actions, then it is loosely coupled. There is no tight dependency on the URI structure, as it is specified and used from the response.” – https://dzone.com/articles/rest-api-what-is-hateoas
11“Chapter 4. Scalability and Performance” – “A production-ready microservice is scalable and performant.” “Efficiency is of the utmost importance in real-world, large-scale distributed systems architecture, and microservices ecosystems are no exception to this rule. Scalability and performance are uniquely intertwined because of the effects they have on the efficiency of each microservice and the ecosystem as a whole…So, while scalability is related to how we divide and conquer the processing of tasks, performance is the measure of how efficiently the application processes those tasks.” – https://www.oreilly.com/library/view/production-ready-microservices/9781491965962/ch04.html
12 Mentions how to handle data management and questions you should ask before implementing a microservice solution. The questions touch on data, auditability, security, legality…(see very start of article) – https://www.ibm.com/garage/method/practices/code/data-management-for-microservices?lnk=hm
13 Section “What is a Fitness Function?” – “…real-world architecture consists of many different dimensions, including requirements around performance, reliability, security, operability, coding standards, and integration, to name a few. We want a fitness function to represent each requirement for the architecture….Performance requirements make good use of fitness functions…Performance testing should be conducted early and frequently, in particular to pick up inflection points when performance changes radically (usually in the wrong direction) because of an update to code.” – https://books.google.com/books?id=pYI2DwAAQBAJ&pg=PA18&dq=%22fitness+functions%22+for+testing+non-functional+requirements&hl=mk&sa=X&ved=0ahUKEwiPtpD-nO3oAhWCLc0KHWKgC74Q6AEIJjAA#v=onepage&q=%22fitness%20functions%22%20for%20testing%20non-functional%20requirements&f=false
14 Interesting article arguing that fitness functions can be used to determine best method of refactoring and save money – https://deepblue.lib.umich.edu/bitstream/handle/2027.42/147343/papertse.pdf?sequence=1&isAllowed=y
15 Lists accessibility as a non-functional requirement that can be tested by reviewing the application code à fitness functions can be used. (Note that there were some discussions elsewhere which indicated some consider this functional, others a combination of functional and non-functional.) – https://www.batimes.com/articles/non-functional-requirements-why-do-we-need-them.html
16 “Design for Failure” (pg26 pdf) and “Support for failure” (pg 26 pdf) – “The more microservices there are, the higher the likelihood at least one is currently failing”, “Key: design every service assuming that at some point, everything it depends on might disappear – must fail “gracefully”, “Goal: Support graceful degradation with service failures” – https://cs.gmu.edu/~tlatoza/teaching/swe432f17/Lecture%2011%20-%20Microservices.pdf
17 This article covers the toggles mentioned and backs up reasons for using them. – https://martinfowler.com/articles/feature-toggles.html
18 On pp34-35, “By implementing new features hidden underneath feature toggles, developers can safely deploy the feature to production without worrying about users seeing it prematurely.”, “One beneficial side effect of habitually building new features using feature toggles is the ability to perform QA tasks in production.” https://books.google.com/books?id=pYI2DwAAQBAJ&pg=PA170&lpg=PA170&dq=%22fitness+functions%22+feature+toggles&source=bl&ots=jGsuqTS4Sb&sig=ACfU3U2BRB1l810ouLVMeoUmqSNTqtvk4g&hl=mk&sa=X&ved=2ahUKEwi70_jQru3oAhUKCc0KHbOLBscQ6AEwAXoECAsQJw#v=onepage&q=%22fitness%20functions%22%20feature%20toggles&f=false