
Multi-Tenant Architecture
MULTI-TENANT ARCHITECTURE DATABASE APPROACH

Ilija Mishov
Founding Partner | Technology track at IT Labs
How to implement
The purpose of this document is to define and describe the multi-tenant implementation approach. Included are the main characteristics of the proposed approach, commonly known as “multi-tenant application with database per tenant” pattern.
Multi-tenant app with database per tenant
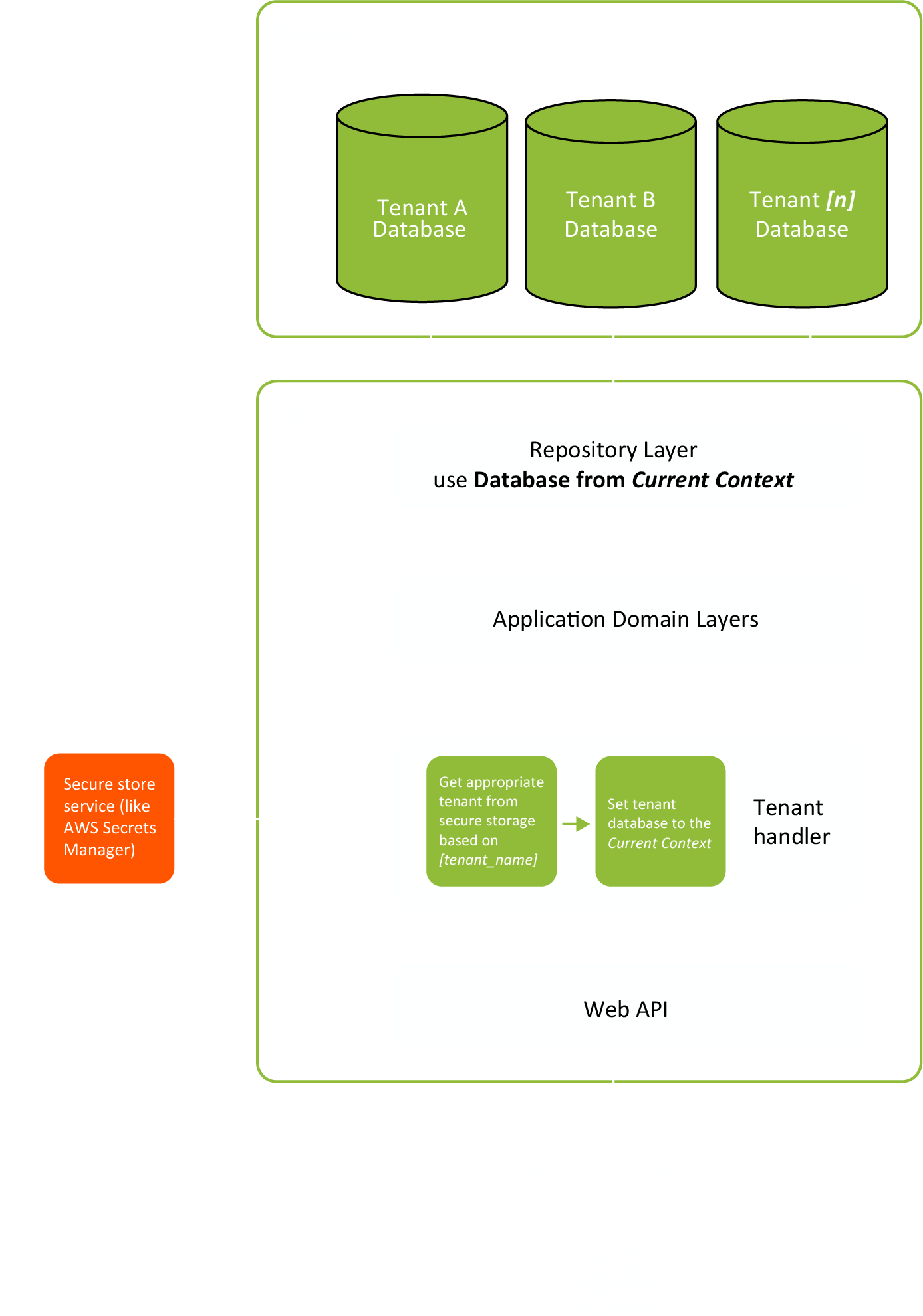
With the multi-tenant application with a database per tenant approach, there is one secure store that will hold the tenants secure data (like the connection string to their database, or file storage etc.). Tenant separation is achieved at the “Tenant handler” layer, where the application resolves which tenant data to use.
Client
The client application is not aware of multi-tenant implementation. This application will only use the tenant’s name when accessing the server application. This is usually achieved by defining the server application’s subdomain for each tenant, and the client application communicates with [tenant_name].app-domain/api.
Server Application
With database per tenant implementation, there is one application instance for all tenants. The application is aware of the client’s tenant and knows what database to use for the client’s tenant. Tenant information is usually part of the client’s request.
A separate layer in the application is responsible for reading the tenant-specific data (tenant_handler layer.) This layer is using the secure store service (like AWS secrets manager) to read the tenant-specific database connection string and database credentials, storing that information in the current context. All other parts of the application are tenant unaware, and tenant separation is achieved at the database access (database repository) layer. The repository layer is using the information from the current context to access the tenant’s specific database instance.
Secure store service
The Secure store service is used to store and serve the tenant information. This service typically stores id, unique-name, database address, and database credentials for the tenants, etc.
Tenant database
Each tenant database is responsible for storing and serving the tenant-specific applications. The application’s repository layer is aware of the tenant-specific database, and it is using the information from the current context to help the application’s domain layers.
Depending upon the requirements, the tenant’s database can be hosted on either a shared or a separate location.
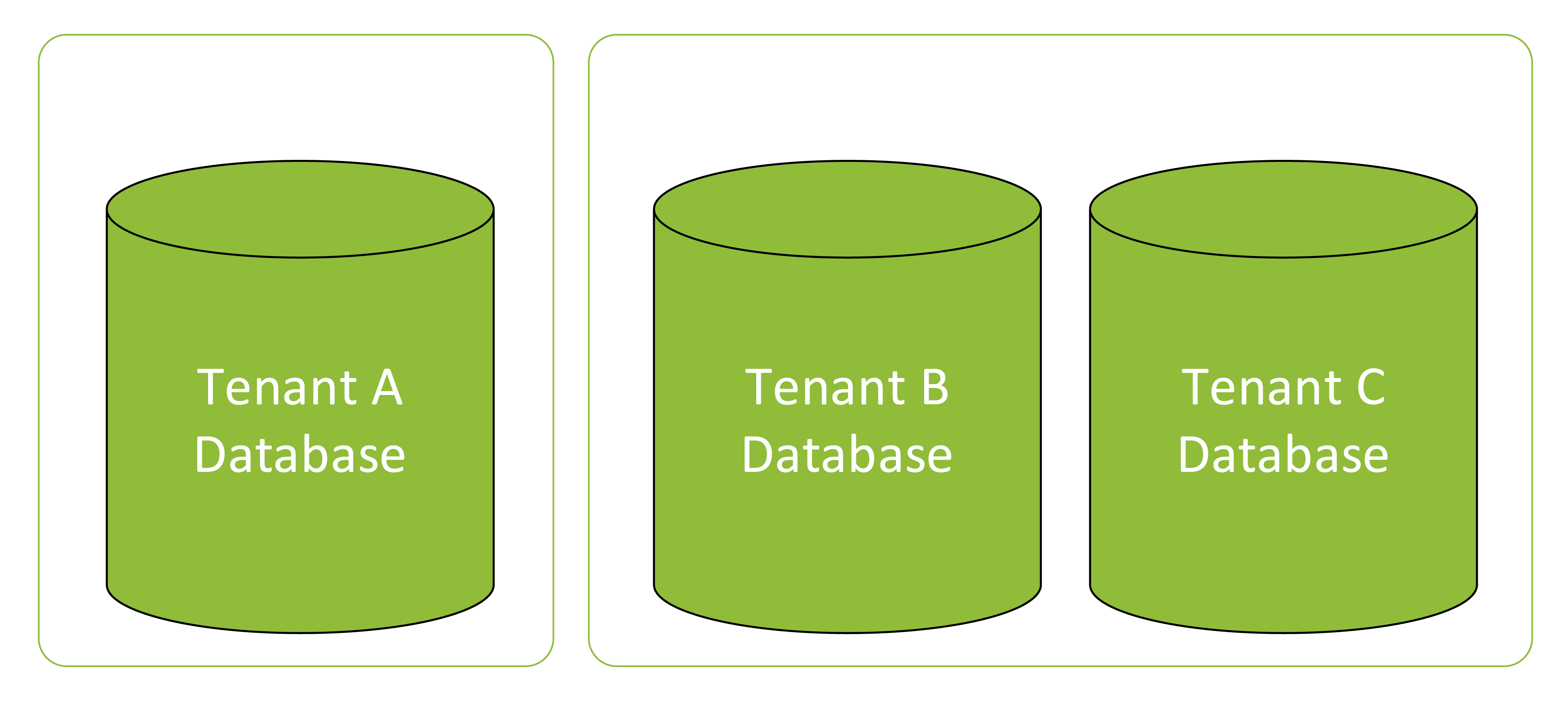
Figure 2: Example – Tenant A database is on Database Server 1. Tenant B and Tenant C databases are sharing Database Server 2.
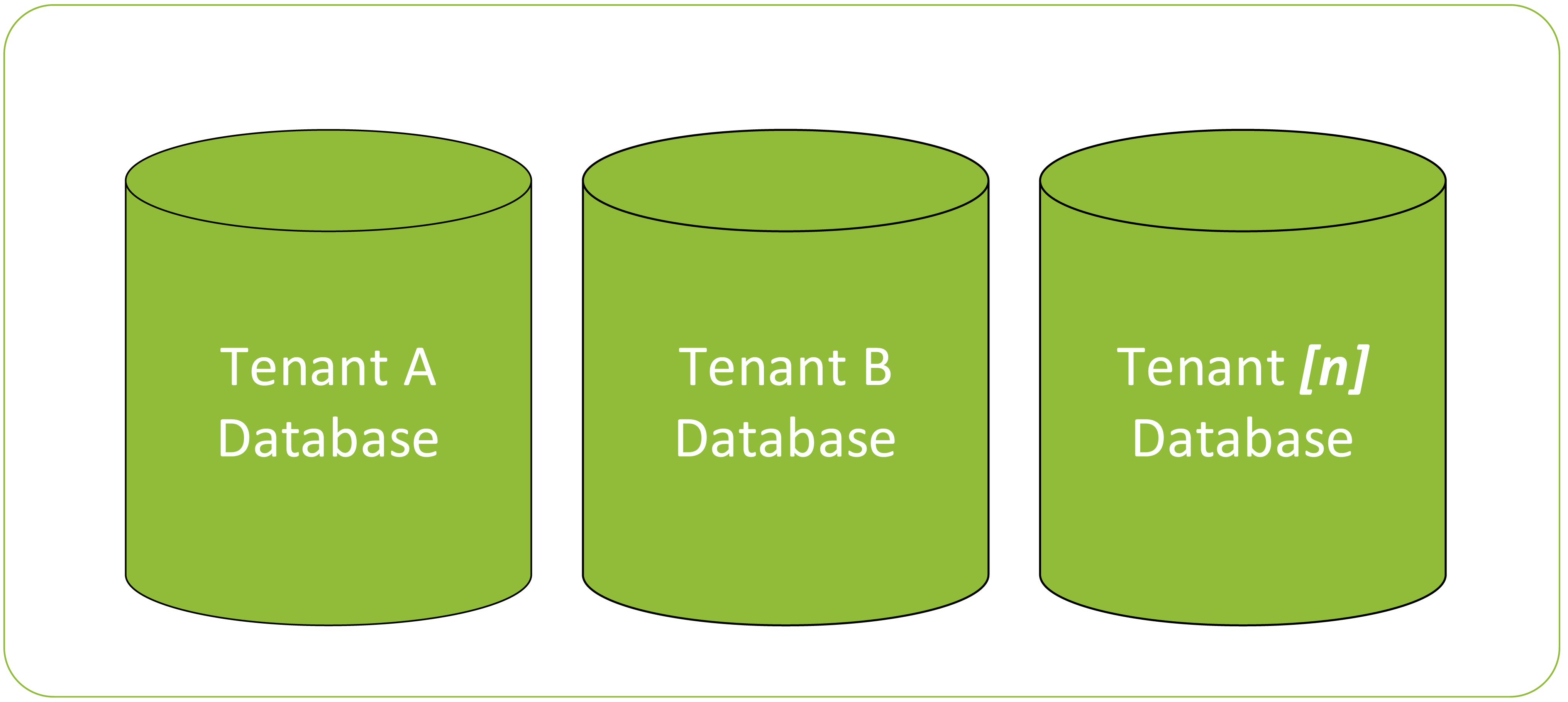
Figure 3: Example – All tenant databases are sharing Database Server 1
Characteristics
Data separation
There are a couple of items which must be considered regarding data separation:
- For good cross-tenant data separation, data is separated in the specific tenant’s database, and there is no mixing of data for different tenants.
In the case of added complexity, where report(s) need to summarize data from all tenants, usually, some additional reporting approach is implemented on top of the implementation.
Database performance and reliability
The database per tenant approach ensures better database performance. With this approach, data partitioning is implemented from the highest level (the tenants.) Also, since data is separated per tenant, one indexing level is avoided. With a multi-tenant database approach, all collections/tables will generate an index for the tenant specification field.
Because the tenant’s instances are separated, if some issue arises with one tenant’s database, the application will continue working for all the other tenants.
Implementation complexity
Most of the application is tenant unaware. Tenant specific functionality is isolated in the tenant-handler layer, and this information is used in the data access (data repository) layer of the application. This ensures that there will be no tenant-specific functionality across the different application domain layers.
Database scalability
For small databases, all tenants can share one database server resource. As database size and usage increase, the hardware of the database server resource can be scaled up, or a specific tenant’s database can be separated onto a new instance.
SQL vs No-SQL databases
For No-SQL database engines, the process of creating a database and maintaining the database schema is generally easier and more automated. With the correct database user permissions, as data comes into the system, the application code can create both the database and the collections. Meaning that when defining a new tenant in the system, the only thing that must be done is to define the tenant’s information in the main database. Then the application will know how to start working for that tenant. For generating indexes and functions on the database level, the solution will need to include procedure(s) for handling new tenants.
For SQL database engines, the process of defining a new tenant in the system will involve creating a database for the tenant. This includes having database schema scripts for generating the tenant’s database schema, creating the new database for the tenant, and executing the schema scripts on the new database.
Deployment and maintenance
The deployment procedure should cover all tenant databases. To avoid any future complications, all databases must always be on the same schema version. When a new application version is released, databases changes will affect all tenant instances.
In the process of defining maintenance functions and procedures, all tenant instances will be covered. It should be noted that many tenants can result in extra work to maintain all the databases.
Backup and restore
A backup process should be defined for all tenant databases, which will result in additional work for the DB Admin and/or DevOps team. However, by having well-defined procedures for backup and restoration, these procedures can be performed on one tenant’s instance at a time without affecting all the other tenants.
Need help with Multi-Tenant approach?
CONTACT US

E2E Test Components
In the previous article, we talked about E2E development challenges and overview of the E2E testing frameworks. Here we will talk about E2E Test Components, and we will cover:
- Specifications, Gherkin
- Runners
- Test data (volumes, import data with tests)
- Automation testing rules – more specifically FE rules
Specifications, Gherkin
Gherkin is a plain text language designed to be easily learned by non-programmers. It is a line-oriented language where each line is called a step. Each line starts with the keyword and end of the terminals with a stop.
Gherkin's scenarios and requirements are called feature files. Those feature files can be automated by many tools, such as Test Complete, HipTest, Specflow, Cucumber, to name a few.
Cucumber is a BDD (behavior-driven development) tool that offers a way of writing tests that anybody can understand.
Cucumber supports the automation of Gherkin feature files as a format for writing tests, which can be written in 37+ spoken languages. Gherkin uses the following syntax (keywords):
- Feature → descriptive text of the tested functionality (example "Home Page")
- Rule → illustrates a business rule. It consists of a list of steps. A scenario inside a Rule is defined with the keyword Example.
- Scenario → descriptive text of the scenario being tested (example "Verify the home page logo")
- Scenario Outline → similar scenarios grouped into one, just with different test data
- Background→ adds context to the scenarios that follow it. It can contain one or more Given steps, which are run before each scenario. Only one background step per feature or rules is supported.
- Given → used for preconditions inside a Scenario or Background
- When → Used to describe an event or an action. If there are multiple When clauses in a single Scenario, it's usually a sign to split the Scenario.
- Then → Used to describe an expected outcome or result.
- And → Used for successive Given actions
- But → Used for successive actions
- Comment → Comments start with the sign "#"→ These are only permitted at the start of a new line, anywhere in the feature file.
- Tags "@"→ Usually placed above the Feature, to group related Features
- Data tables"|"→ Used to test the scenarios with various data
- Examples → Scenario inside a rule
- Doc Strings– ""→ To specify information in a scenario that won't fit on a single line
The most common keywords are "Given", "When," and "Then", which QAs use in their everyday work when writing test cases, so they are familiar with the terminology. Here is an example of a simple scenario written in the Gherkin file:
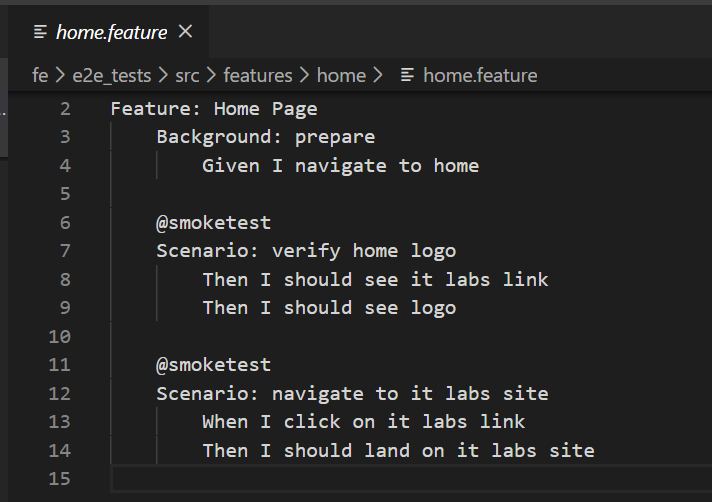
Once the QAs define the scenarios, developers, or more skilled QAs are ready to convert those scenarios into executable code:
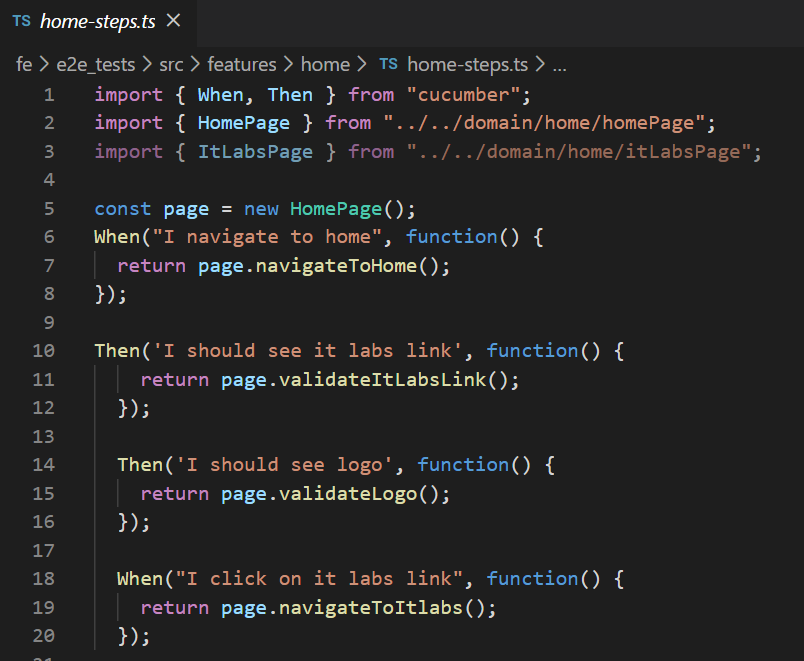
Using this approach of writing this type of test, teams can stay focused on the system's user experience. The team will become more familiar with the product, better understand all the product pieces, and how the users will use it daily.
More examples can be found here https://github.com/IT-Labs/backyard/tree/master/fe/e2e_tests/src/features
Best practices
Several best practices can be taken into consideration when working with Gherkin (feature files):
- Each scenario should be able to be executed separately.
- Common scenarios should be combined in a data table.
- Steps should be easily understandable.
- Gherkin (feature files) should be simple and business-oriented.
- Scenarios ideally should not have too many steps. It is better if it's less than ten.
- Titles names, steps names, or feature names should not be extremely large. The best case is 80-120 characters.
- Tests should use proper grammar and spelling.
- Gherkin keywords should be capitalized.
- The first word in titles should be capitalized.
- Proper indentation should be used, as well as proper spacing.
- Separation of features and scenarios by two blank lines.
- Separate example tables by one blank line.
- Do not separate steps within a scenario by blank lines.
Runners
Cucumber.js enables the writing of robust automated acceptance tests in plain language (Gherkin) so that every project stakeholder can read and understand the test definitions.
Implementation of those tests can be done using:
- Selenium
- Selenium + Nighwatch.js
- Cypress
Test Data
Test data is one of the main parts of the test environment, and it takes time to design the solution. In the following section, we will cover the options we have during the design phase and present an example solution.
The design of the solution needs to implement the following points:
- The test environment should support data versions.
- The test environment can be quickly restored to its original state.
- The test environment can be run on any operating system.
- Each user can change the data and promote it simply into the test environment.
Data Versions
Data versioning is a very important part of the test solution because it is how we will support data transition from one software version to the next one. The following section contains some of the options which we can use in our test solution.
Scripts
"Scripts" as an option can be used as part of maintaining the test data or test execution steps. Scripts can be of different types, for example, SQL, JavaScript, Shell, bash, etc... For example, maintaining database data can be done by adding a new script or incrementing a new database version script. JavaScript can be used when we want to enter data into the system via HTTP because JavaScript enables communication with the software API interface. Due to the dependency of the API interface, scripts should be maintained as the platform evolves.
Tests
E2E tests can be used as an option to fill data in the system, the same as scripts, before test execution or as part of maintaining test data. Using them as fill options before execution should be avoided because they are time-consuming to create, the complexity of maintaining them, and the possibilities they can fail, leading to false test results. However, they can be a good candidate for maintaining data for complex systems. For example, when we have a big team collectively working on the same data set, manual test data preparation can be done via text during the development phase, which can be repeated with small interventions depending on features overlapping functionalities.
Manual Data Changes
This option should be avoided as much as possible because it's time-consuming, and there is no warranty that data is the same between two inserts.
Data Location
Data location is very important information during designing the test solution because data can be stored in various locations, such as database, file system, memory, or external system such as IDP, search service, to name a few.
Database
A database in software solutions can be a standalone or managed service. Each of these options gives us the pros and cons of writing, executing, and maintaining the tests.
Here are some of the challenges with a standalone database which we should solve:
- Advance knowledge of the tools to automate the processes of backup/restore data.
- Tools for these processes require appropriate versions. Example: backup made from a newer database version cannot be restored to an older database version.
- Tools may have conflicts with other tools or applications on the operating system itself.
Managed service as an option is solving version and tools issues, but from another side, they introduce new challenges such as:
- Snapshot/restore is a complex process; it requires scripts and appropriate knowledge to access the service
- They are more expensive if we have a different service per environment (to name a few environments: test; staging; production)
File System
Data can also be found on the file system where the software is hosted. Managing this can be challenging because of:
- The particular hosting Operating System, and simulating the same on each environment
- Variation of Operating System versions
- Tools used for managing the files
- Tools access rights
- (to name a few)
External Systems (Third-party systems)
External systems as Identity Provides (IDPs), search services, etc .. are more difficult to be maintained because they have a complex structure and are async. Once configured, these systems should not be part of test cases but only used as prepared data. The data usually is prepared by manual process. Example: The signup process, which requires an email or another type of verification, should be avoided because many systems are included through that test path. Thus, we don't know how long it will take to be sent, received, and verified. Additionally, those systems can be upgraded and include other user flows, which potentially will break our tests.
Docker Volume
Docker volume is one of the options for storing data used by Docker containers. As part of the testing environment, volumes must satisfy all the requirements mentioned above because they are portable.
The E2E test environment has two variables, docker version and operating system where tests are run or maintained. We should provide scripts and steps for each target operating system setup. Then provide info on what is the minimum Docker version for commands to work.
Volume portability requires the following steps for maintaining data inside:
• Volume restore from latest test data version
• Volume must be attached to a running container
• Developers perform data changes
After data changes or container version upgrades, volume exports should generate a new version and be shared in a central place.
This process of maintaining data must be synchronous, which means only one version can be upgraded at a time due to the inability to merge volumes. If this rule isn't followed, we will incur data loss.
Example - Docker compose with volume:
api-postgres:
image: postgres:12.2
container_name: api-postgres
environment:
- "POSTGRES_PASSWORD=deV123*"
- "POSTGRES_USER=dev"
- "POSTGRES_DB=sample"
volumes:
- api-postgres:/var/lib/postgresql/data:z
ports:
- "5444:5432"
networks:
- sample
networks:
sample:
name: sample-network
driver: bridge
volumes:
api-postgres:
external: true
Git: https://github.com/IT-Labs/backyard/blob/master/api/docker-compose.yml
Docker volume central location: https://github.com/IT-Labs/backyard/tree/master/backup Note: Git should not be used because the volume file is big , and GIT complains about that.
Volume backup command:
docker run --rm --volumes-from api-postgres -v \/${PWD}\/backup:\/backup postgres:12.2 bash -c "cd \/var\/lib\/postgresql\/data && tar cvf \/backup\/api_postgres_volume.tar ."
Git: https://github.com/IT-Labs/backyard/blob/master/volume_backup.sh
Volume restore :
docker container stop api-postgres
docker container rm api-postgres
docker volume rm api-postgres
docker volume create --name=api-postgres
docker run --rm -v api-postgres:\/recover -v \/${PWD}\/backup:\/backup postgres:12.2 bash -c "cd \/recover && tar xvf \/backup\/api_postgres_volume.tar"
Git: https://github.com/IT-Labs/backyard/blob/master/volume_restore.sh
Automation Rules
• Test Architecture and code must follow the same coding standards and quality as tested code. Without having this in mind, tests will not be a success story in the project.
• Place your test closer to FE code, ideally in the same repository. This way, the IDE can help with refactors.
• Follow the same naming convention ex: classes, attributes as your FE code is using. Find element usage will be easier.
• Introduce testing selectors or use existing with following order id > name > cssSelector > element text> > … > xPath . If your selector is less affected by design or content changes, test stability is greater.
• Optimize your test time by manipulating the thread using framework utilities such as wait.until instead of pause test execution.
• Use central configurations for your browser behavior, enabled plugins, etc. This is to avoid differences in UI when it is executed in different environments or browser versions.
• The test should not depend on other test execution.
• Pick wisely what you will cover with E2E tests and what is cover with other types of testing. E2E Test should not test what is already tested by other tests, for example, unit test, integration test, to name a few.
• The test should be run regularly and maintained.
Conclusion
There is no general rule on what components you should choose to guarantee E2E testing success. Careful consideration, investigation, and measures to create the right solution should be engaged.
It depends on your unique situation. For example, the cases you have, the environment you are using, and the problem you want to solve. In some cases, you can go with one test runner; in others, you can use another test runner, and all of that depends on the supported browsers for your application. Do you need support for multi-tabs in your tests or to drive two browsers simultaneously (a considering factor in this is Cypress does not support multi-tabs and two browsers at the same time)? Or do you need parallel testing? These are just a few factors and situational conditions that may come up in consideration.
When it comes to using Specifications (should we use them or not), Gherkin and Cucumber are more or less the same. Writing feature files using Gherkin seems simple at first, but writing them well can be difficult. Many questions pop up and need to be considered, for example:
• Who should write the Gherkin specification? BA or QA?
• How much into detail should we go, and how much coverage we should have?
o Note: If you need high test coverage, it's better not to use Gherkin and Cucumber
• Yes, scenarios can be easily read by non-programmers, but how much time does it take to write them?
• How easily maintainable are your tests?
When it comes to test data, you can go with data volumes in some cases, but how will you solve the data volume if you use a serverless application?
On the other hand, if you are using AWS, how will you solve the test environment's problem and test data?
Usually, if you are using an on-premise or local environment, you can go with data volumes since it is more feasible and easier to maintain. If you are on the cloud, we should go with something like scripting – tests, snapshots, database duplication, database scripting, to name a few.
And finally, on top of all mentioned above, you must measure your team's capabilities that will work on those tests.
E2E testing helps ensure the high quality of what's delivered. It's an important approach to reduce disappointment to the end-user, reduces bugs being released, and creates a high-quality development environment. The ROI will speak for itself.
Aleksandra Angelovska
QA Lead at IT Labs
Jovica Krstevski
Technical Lead at IT Labs
In this article, we will dig into a little more detail into what Business Agility is. It’s partnered up with the IT Labs services page, which provides a service to help its clients create fast adapting, agile organizations (see: Business Agility). After reading this article, the outcomes we intend are:
- You will know what the HELL Business Agility is!
- Why it is important
- Why it’s not another fad
- How you can spark a transformation fire in your organization to start to become more Agile
- Understand the meaning of life and the universe
The article is written from the perspective of a conversation with the author (TC Gill, IT Labs Co-Active® Business Agility Transformation Lead). It’s not far off a real conversation that happened in a London pub (bar) not too many years ago. Profanities and conversational tangents have been removed in service of keeping this professional and getting to the point.
Is it Yoga?
Sounds like Yoga, right!?! It made me laugh when I first thought that up. Don‘t worry. It‘s not about getting all employees to wear leotards and gather every morning for a ritual ceremony of stretching those hamstrings, acquiring bodily awareness and mindful reflection. Though I personally think that would be a good idea. Being someone that‘s pretty open–minded, I‘d be up for it. Would you?
Anyway, enough ramblings. I suppose we can think of it as Yoga for the Business. It‘s the down dog stretch (and much more) for businesses‘ wellbeing, including a kind of meditation for the organizational System. i.e., Self–reflection and choosing the next best steps. Like Yoga, It reduces blood pressure, stress, gets the whole working in unison, makes the body more supple, and generally makes the System more thoughtful. I think that‘s a great analogy. If you are still reading and not been frightened off about this becoming any more woo-woo, I love to engage in some questions I get asked as one of the Business Agility warriors at IT Labs. These questions and answers will fill–out your understanding and, in turn, generate thinking to get you and your teams to start considering Business Agility for your selves.
So here goes.
What the hell is Business Agility?
So this is the definition from the Business Agility Institute:
“Business agility is the capacity and willingness of an organization to adapt to, create, and leverage change for their customer’s benefit!”
(Business Agility Institute)
Pretty simple, right!?! In fact, obvious. The caveat in all this is up until recently; this was not always the case. The good news is, forward–thinking, innovative, and disruptive businesses have been living this definition for a while. To add, profiting, and thriving from it.
Coming back to the definition. How does the sentence read for you? Does it resonate? Is this what you want? I do hope so. Otherwise, the innovation storm we all live in now will be the proverbial meteor that wipes out all Jurassic era businesses (Dinosaurs). Industrial aged businesses with Cretaceous mindsets won‘t be able to evolve fast enough to stay relevant. They really need to shift the thinking and to operate away from the old paradigms.
Subsequently, Business Agility allows companies to evolve in the innovation storm we live in. The ultimate goal is to create truly customer–centric organizations that have:
- Clear and progressive outcomes for the end customer
- A resilient and adaptive organization that can shift its way of thinking and operating when changes occur not only externally to the organization but also internally
- Create financial benefits for the organization so it can thrive alongside the people who work in it. And yes, that includes the leadership, not just the people that work on the coal face, which seems to be a common focus in lots of places (#LeadersMatterToo)
Is this relevant to all organizations?
I certainly think so. After all, all organizations have people, have processes, and end customers. Well, at least I hope so. This concept of ‘customers’ also goes for non-profit charitable organizations. At the end of the organization’s flow, the outcomes serve people (or groups of people) that need or are helped by the organization’s outcomes, i.e., customers. In short, all businesses need to be able to adapt to changes internally and externally.
Though I need to add, the challenge of embracing change in larger organizations becomes even more pronounced. Large businesses generally turn into dirty great big tankers. The rusty mega-ship image with filthy cargo sloshing about in it, seems quite fitting. They’re unable to adapt, stuck pretty much on the path they’ve been taking, and carry all kinds of baggage that people want to move away from (apologies to all people reading this that live and work on tankers (#TankerPeopleMatterToo).

In the here-and-now, with many organizations that have/are implementing Agile, Agility’s relevance becomes more pronounced. After all, today, all companies are interwoven into the world’s digital fabric; hence all companies are tech companies.
“Today, all companies are interwoven into the world’s digital fabric; hence all companies are tech companies.”
(TC Gill)
So having the edge in your tech game will make a huge difference. And with these companies deploying high performing Agile teams delivering the tech they need, the contrast of performance starts to show itself in other parts of the organization. This contrast means that the tech departments that previously used to be the bottleneck start to look like the organization’s golden child. Unfortunately, other structural parts start to hold things back. More traditional business functions become the bottle kneck as the tech function tries to adapt to changing external or internal circumstances.
So in answer to your question: “Is this relevant to all organizations?“. Yes! And particularly those that are hitting an adaptability wall. Not because of tech delivery, but other aspects of the organization holding back the flow of outcomes and ability to adapt to change. This contrast of performance brings up the subject of the ‘Theory of Constraints.’
Bloody hell! Now you’re talking about the Theory of Constraints? Why is that relevant?
In the fabulous piece by Evan Laybourn (CEO of the Business Agility Institute), “Evan’s Theory of Agile Constraints,” Evan talks about organizations that can only be agile as the least agile part of the organization. The simple diagram shows the point here (all credit to Evan and the work that the Business Agility Institute does).
The illustration below shows a very simple example of how tech functions were once the bottleneck.
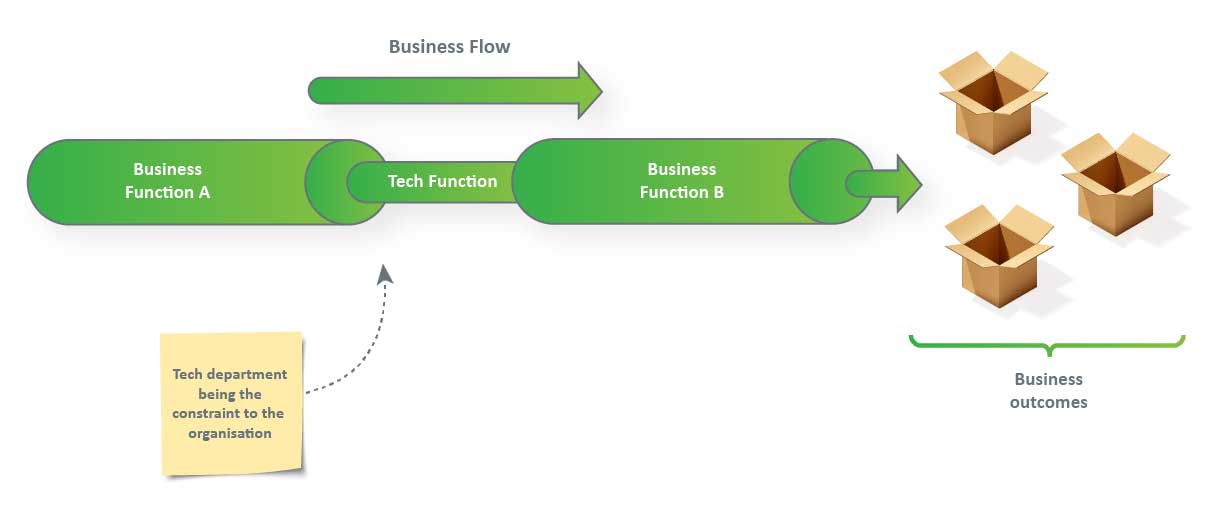
Then Agile and the likes came along and created high performing teams with an enlightened approach to product (outcome) management. Tech functions became the golden child of the Business.
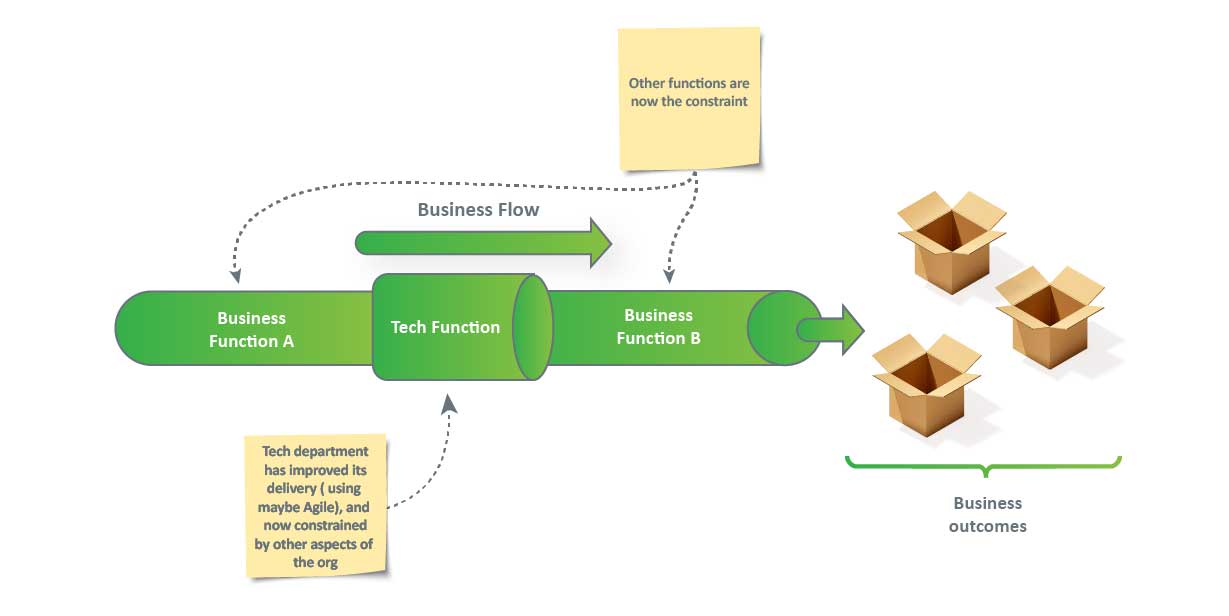
The natural outcome for businesses and enlightened leaders was to see how the organizations could have golden children across their span, where each function complemented the other. Thus the idea of Business Agility enters the stage, intending to ensure no one function constrains another:
In the context of the illustrations here, we are talking about business flow and improving the delivery of business outcomes. For a software company, this may be software; this may be things that the customer needs. For other organizations, it will be different, but still, outcomes that they desire.
The flow could be about the company adapting to internal or external change. As one aspect of the businesses adapts to the change, one area becomes the overarching constraint. In short, improvements in one area don’t provide benefits to the whole. Worse still, improvements in one area may create a painful overload in other areas.
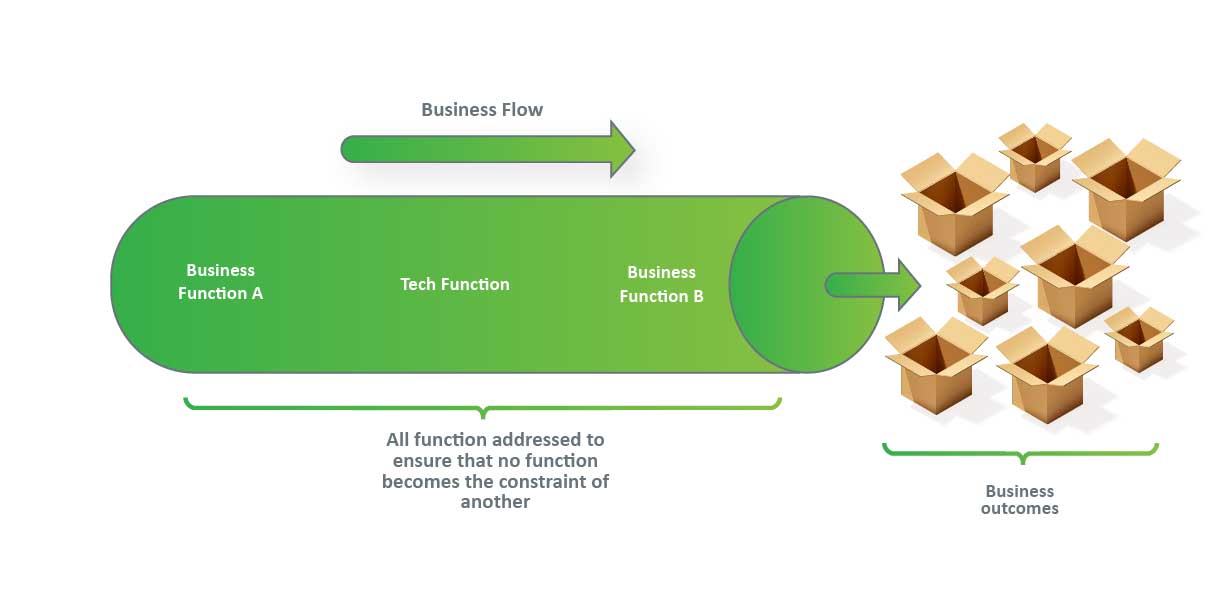
So at the end of the business flow is the end customer. The outcomes can be in many forms, but it‘s ultimately about the customer receiving the desired outcomes.
Is business agility all about the end customer?
Yes! Damn right. When you boil down the waffle, At the heart of all businesses is the end customer. Those beautiful people you are here to serve.
Business Agility ensures (better still, fights for) the entire organization delivering the customer’s needs. All continuous learning in any part of the Business is always sensing, learning, and adapting to serve the end customer. This focus then helps the company create financial opportunities and growth to keep it alive.
This perspective brings me onto a beautiful diagram by the Business Agility Institute, showing the customer at the org’s heart.
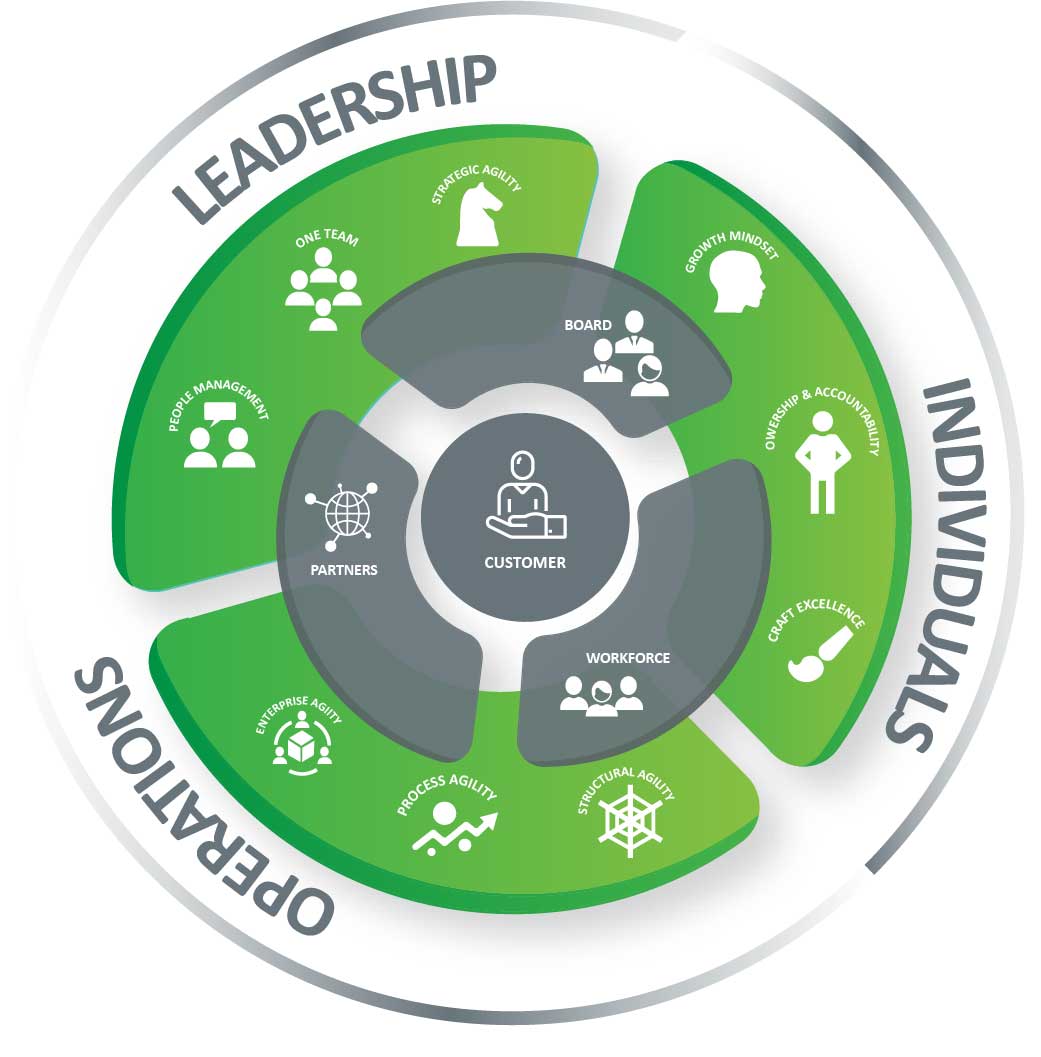
Mmmm, this is interesting; how do we get going with this Business Agility gobbledygook?
Firstly don’t call it gobbledygook. That’s just not nice. To me, it‘s common sense. The name may be new, but thriving companies have played the Business Agility songbook for a while. And as mentioned, greatly profited from it. It‘s a kind of disrupting common sense that’s in the space. The question is not ‘IF‘ you start to employ the concept, but ‘WHEN.’
Observe from the diagram how these business domains, or organizational elements, feed directly into the customer–centric view. There are no hard and fast rules about these, but this is a nice grouping. The naming of them allows conversations to be started about how organizational Agility can be created and adapted for the here and now. You see, there are no cookie-cutter solutions that work for all organizations; they are all unique. They have their incumbent cultures, ways of operating, with strengths and weaknesses in them all. The key with Business Agility is to shine a light on them and see where the constraints and need for adaption are.
There are many tools and approaches you can take, but no single one. Often you hear people say that you need to implement Agile (one of the many approaches to creating Business Agility). But this simply is not the case. Just because it shares the word in the title, it doesn‘t get an implicit inclusion in an approach (but I do feel it‘s a good one). It depends on the particular situation or Business. So here is a memorable quote from someone I very much respect in the field.
“Business Agility does not need Agile, but Agile needs Business Agility.”
(Stephen Parry)
Can we go into a bit more detail on the domains of Business Agility?
Yes and no. I‘m not going to much detail here, as there‘s a lot to cover. But the Business Agility Institute has a great piece on this, centering around the infographic above.
Check it out here: Domains of Business Agility (Busines Agility Institute)
But while we are here, let‘s create a quick overview of the Domains and Subdomains. Don’t try to overthink this. This is more of an art than it is a logical path or a set of instructions. The domains that the BAI have created are a great starting point to get the conversation going.
The Customer
Tip número uno! Create a gravity well around your target customers. Everything you think, do, experiment, and innovate about, ideally always gravitates towards the customer.
“The heart of business agility is no less than the very reason we exist: our Customer.“
(Business Agility Institute)
For different organizations, you can imagine this means different things. The bottom line is, it’s any people that your organization wants to deliver the best business/organizational value to.
Profiting from these activities from a Business Agility perspective is a side effect of serving the customer well. A quote that puts it nicely here is.
“Profit is like the air we breathe. We need air to live, but we don‘t live to breathe.“
(Frederic Laloux)
Profit is important because it allows us to survive. But our foundational purpose is the customer.
The systems that make up the organization
Within the living System of the organization, I like to view it has two systems working in unison, overlapping and intertwined.
- The Social System
- The Operational System
Now I would draw a diagram to illustrate them, but my brain had a seizure and lost the will to carry on. I think the main point here is to consider these two systems work hand in hand. If one is healthy and the other not, the situation tends to make things painful (i.e., not fun).

We want these systems to be healthy, right? For that to be the case a very simple view is to say these systems need to have:
- Healthy flow (of communication, information, and business value towards the customer)
- Well functioning, with honest feedback loops to show the state of the system
- The ability to reflect and adapt using the above two.
In both systems, we want to see how we can enhance all three of these. Its continual learning and, in a way, a never–ending task. This may depress some people out there. Especially leadership types. But this is the reality. We can‘t expect a world that is ever–changing to have a fixed approach. It‘s just not like that. The organization has to be a learning organization and always deepening that learning and turn it into action for adaption. Hence the name “Business Agility“. It literally is what it says on the tin.
Let‘s look at these two systems.
The social System (Relationships)
The view I like to take is that businesses/organizations are living systems. They are interconnected internally and externally. And those connections are, for the most part, relationships. Organizations are a complex social system that has a health and way of operation in its own right.
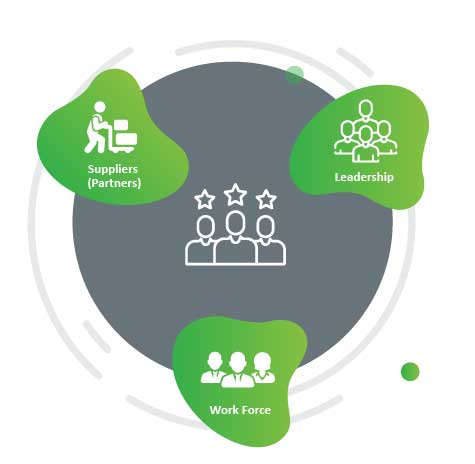
When approaching business Agility, we want to develop relationships. Not only within teams (Agile Scrum teams) but across teams. Across the organization. And then there is the external view, looking out from the organization. With Business Agility, we want to build strong relationships with our client base, building resilience into them. They can tolerate tough times when things go curly at the edges (go wrong) and build on things when they go well.
One area that gets missed often (in my experience) is the suppliers. Strong relationships with our suppliers develop into partnership with flexibility and mutual respect. When things can be better, or failures in the supply chain take a negative turn, incidences will be rectified through transparency, honesty, collaboration, and fairness.
The area to start building a relationship is … everywhere. Areas that get often grouped are:
- The leadership
- The workforce
- The suppliers (partners)
- And of course, the customer.
The aim is to build a healthy web of relationships that serve good honest, trusting communications. To get started where you see the most misunderstandings and upset. As you strengthen the Relationship in one area, others will most probably start to grow as well.
The mantra I and many within IT Lab‘s repeat is “Relationship First.” That’s what we build all the great work we do on. Why because it’s easier, more effective, and more fun.
“Relationship first. Always!”
(By Anyone with a well functioning heart)
The operational system (operations)
Operations cover all the things the Business does (the doing) to deliver value and how it is generated. Three key areas feed into this from a Business Agility Perspective. Areas that require similar continuous sensing, learning, and adapting.
- Structural agility
- Process agility
- Enterprise agility
Structural agility
There was a time (in the industrial age) where an organization’s structure would be set up, and “bobs-your-uncle,” (et voilà!) we were good to go as we started for a long period of time. This industrial-age approach is not the case anymore. Let me repeat that. “This is not the case anymore.” Do I need to repeat that for you? 😉
With an ever-changing world, the structures of businesses need to adapt. Maybe temporarily or for longer periods. The question is to ask continuously, is the structure we have right now serving the organization and its people best?
“Business Agility requires the ability for an organization to create coalitions or change structure as needed to embrace new opportunities with ease and without disruption.”
(Business Agility Institute)
There are many resources that others and IT Labs have created around this. Take a look at these for a start:
- CTO Confessions Webinar: Creating Structural Agility with Living Systems
with Sally Breyley Parker and Jardena London - Structural Agility | Using structure to enable the flow of value
- CTO Confession Podcast: Episode 5: Transformation Leadership for CTOs
with Jardena London - Structural Agility (Business Agility Institute)
As you can guess, some of the names listed are experts in this area. It’s well worth reaching out to them if you want to know more.
There are many approaches that we can employ to bring about Structural Agility. Contact IT Labs if you want to know more.
Process agility
All organizations create processes as they get a grip on the activities that occur regularly within the organization. The idea is to provide guides to help people know what to do, what sequence, and create consistency. This is good, right!?!
The challenges start (especially in this day and age) when the process becomes a kind of dogma. “This is the way we do it,” “This is the way we always did it,” “this is the way we do it … period!”.
So, where is the rational logic in that, if the world (internally and externally) is constantly changing? This spoke to those moments when you were in your career when you looked at a process with a grimaced face and said, “Why the hell are we doing this!… this is CLEARLY a waste of time!”.
Process agility is about getting all the eye-balls within the company to keep an eye on the ball. This sports analogy is really important because invariably in the past, “industrial age” past, experts, managers, or old textbooks would describe and dictate the process to follow. The people doing the work rarely looked up from their work to question why they were doing something. Well, now, with the advent of Agile mindsets and the distribution of leadership closer to where the work is accomplished, the people who are the experts about the job are the people actually doing the work. They are the ones that need to own the process, sense whether it’s working, and then adapt it if need be.
And taking a wider view across the organization, as is the role of Business Agility, we look to see how these processes interface and integrate. With this view, we look to see if we can:
- Consolidate processes
- Refactor processes to eliminate repeat work
- Remove parts of the process that creates additional work upstream or downstream
- Look to see if the combined processes are serving the customer. Remember, they are not just part of our universe; they are the center of it.
For further reading, take a look at this: Process Agility
Enterprise agility
“Enterprise agility” brings me to the last of the abilities that I can think of that I want to cover. I bet you are sick of reading the word “Agility” by now. Don’t worry; we are nearly there. You’ll be dreaming about this word during your slumber for the next few weeks.
This agility is about scaling. It’s how the small scale, efficient activities, frameworks, and methodologies can be scaled up to work across larger organizations. Think back to the big oil tank analogy earlier. This is about taking the various activities across that good ship (that are now working well) and bringing them up on a larger scale.
The objective is to create a high performing customer-centric business value flow that’s sensing and adapting ALL the time. This subject brings us full circle to the section on “Bloody hell! Now you’re talking about the Theory of Constraints? Why is that relevant?.”
“An organization can only be as agile as it’s least agile division!”
(Evan Leybourn, Evan’s Theory of Agile Constraints)
Enterprise Agility is a convergence of all the Agility efforts across the Business. When all the business units (IT, Marketing, Sales, Operations, Finance, Administration) have reached a level of Agility maturity, we have reached a kind of promised land. Where one business unit is not overly hindering others, if at all. Better still, they are enhancing each other. A synergy of efforts creating more than the sum of its parts. i.e., Enterprise Agility emerges.
For more information on this area, take a look at this: Enterprise Agility.
Conclusion
So, in short, Business Agility is about creating an agile organization. It doesn’t mean you have to use Agile. Business Agility is framework/methodology/tool agnostic. It’s a wider conversation of how an organization can focus its efforts on serving the customers. In turn, this creates, in my humble opinion, a life-enhancing work culture that creates energy around delivering value smoothly and effectively. Continuous sensing, learning, and adapting to improve the health of the organization (its financial bottom line).
Before I leave you, we have some podcast that touches on the topic of business agility here:
- CTO Confessions Webinar: Creating Structural Agility with Living Systems
with Sally Breyley Parker and Jardena London - CTO Confession Podcast: Episode 5: Transformation Leadership for CTOs
with Jardena London - CTO Confessions Podcast: Business Agility in the context of the CORONA Virus challenge
In the meantime, fire up your thinking about how this subject can make a difference to your organization. May your organization live long and prosper with Business Agility.
TC GILL
Co-Active® Business Agility Transformation Lead

Going serverless – choose the right FaaS solution
Nowadays, serverless computing, also known as ‘Function as a Service’ (FaaS), is one of the most popular cloud topics kicking around. It’s the fastest growing extended cloud service in the world. Moreover, it gained big popularity among enterprises, and there’s been a significant shift in the way companies operate. Today, building a reliable application might not be enough. Especially for enterprises that have strong competition, sizeable demands on cost optimization, and faster go-to-market resolution metrics. By using a serverless architecture, companies don’t need to worry about virtual machines or pay extra for their idle hardware, and they can easily scale up or down the applications/services as the business requires.

Software development has entered a new era due to the way serverless computing has impacted businesses, through its offer of high availability and unlimited scale. In a nutshell, serverless computing is a computing platform that allows its users to focus solely on writing code, while not having to be concerned with the infrastructure because the cloud provider manages the allocation of resources. This means that the cloud vendors, like AWS and Azure, can take the care of the operational part, while companies are focused on the ‘business’ part of their business. In this way, companies can bring solutions to the market at a much faster rate at less cost. Furthermore, serverless computing unloads the burden of taking care of the infrastructure code, and at the same time, it’s event-driven. Since the cloud handles infrastructure demands, you don’t need to write and maintain code for handling events, queues, and other infrastructure layer elements. You just need to focus on writing functional features reacting to a specific event related to your application requirements.
The unit of deployment in serverless computing is an autonomous function, this is the reason why the platform is thus called a Function as a Service (FaaS).
The core concepts of FaaS are:
- Full abstraction of servers away from developers
- Cost based on consumption and executions, not the traditional server instance sizes
- Event-driven services that are instantaneously scalable and reliable.
The benefits of using FaaS in software architecture are many; in short, it reduces the workload on developers and increases time focused on writing application code. Furthermore, In FaaS fashion, it is necessary to build modular business logic and pack it to minimal shippable unit size. If there is a spike workload on some functions, FaaS enables you to scale your functions automatically and independently, only on the overloaded functions, as opposed to scaling your entire application. Thus avoiding the cost-overhead of paying for idle resources. If you decide to go with FaaS, you’ll get built-in availability and fault tolerance for your solution and server infrastructure management by the FaaS cloud provider. Overall, you’ll get to deploy your code directly to the cloud, run functions as a service, and pay as you go for invocations and resources used. If your functions are idle, you won’t be charged for them.
In a FaaS-based application, scaling happens at the function level, and new functions are raised as they are needed. This lower granularity avoids bottlenecks. The downside of functions is the need for orchestration since many small components (functions) need to communicate between themselves. Orchestration is the extra configuration work that is necessary to define how functions discover each other or talk to each other.
In this blog post, I will compare the FaaS offerings of the two biggest public cloud providers available, AWS and Azure, giving you direction to choose the right one for your business needs.
Azure Functions and AWS Lambda offer similar functionality and advantages. Both include the ability to pay only for the time that functions run, instead of continuously charging for a cloud server even if it’s idle. However, there are some important differences in pricing, programming language support, and deployment between the two serverless computing services.
Amazon Lambda
In 2014 Amazon became the first public cloud provider to release a serverless, event-driven architecture, and AWS Lambda continues to be synonymous with the concept of FaaS. Undoubtedly, AWS Lambda is one of the most popular FaaS out there.
AWS Lambda has built-in support for Java, Go, PowerShell, Node.js, C#, Python, and Ruby programming languages and is working on bringing in support for other languages in the future. All these runtimes are maintained by AWS and are provided on top of the Amazon Linux operating system.
AWS Lambda has one straightforward programming model for integration with other AWS services. Each service that integrates with Lambda sends data to your function in JSON as an event, and the function may return JSON as output. The structure of the event document is different for each event type and defines the schema of those objects, which are documented and defined in language SDKs.
AWS Lambda offers a rich set of dynamic, configurable triggers that you can use to invoke your functions. Natively, the AWS Lambda function can be invoked only from other AWS services. You can configure a synchronous HTTP trigger using API Gateway or Elastic Load Balancer, a dynamic trigger on a DynamoDB action, an asynchronous file-based trigger based on Amazon S3 usage, a message-based trigger based on Amazon SNS, and so on.
As a hosting option, you’re able to choose memory allocation between 128 MB to 3 GB for AWS Lambda. The CPU functions and associated running costs vary with chosen allocations. For the optimal performances and cost-saving on your Lambda functions, you need to pay attention to balancing the memory size and execution time of the function. The default function timeout is 3 seconds, but it can be increased to 15 minutes. If your function typically takes more than 15 minutes, then you should consider finding some alternatives, like the AWS Step function or back to the traditional solution on EC2 instances.
AWS Lambda supports deploying source code uploaded as a ZIP package. There are several third-party tools, as well as AWS’s own CodeDeploy or AWS SAM tool that uses AWS CloudFormation as the underlying deployment mechanism, but they all do more or less the same under the hood: package to ZIP and deploy. The package can be deployed directly to Lambda, or you can use an Amazon S3 bucket and then upload it to Lambda. As a limitation, the zipped Lambda code package should not exceed 50MB in size, and the unzipped version shouldn’t be larger than 250MB. It is important to note that versioning is available for Lambda functions, whereas it doesn’t apply to Azure Functions.
With AWS, similar to other FaaS providers, you only pay for the invocation request and the compute time needed to run your function code. It comes with 1 million free requests with 400,000 GB-seconds per month. It’s important to note that AWS Lambda charges for full provisioned memory capacity. The service charge for at least 100 ms and 128MB for each execution, rounding the time up to the nearest 100 ms.
AWS Lambda works on the concept of layers as a way to centrally manage code and data that is shared across multiple functions. In this way, you can put all the shared dependencies in a single zip file and upload the resource as a Lambda Layer.
Orchestration is another important feature that FaaS doesn’t provide out of the box. The question of how to build large applications and systems out of those tiny pieces is still open, but some composition patterns already exist. In this way, Amazon enables you to coordinate multiple AWS Lambda functions for complex or long-running tasks by building workflows with AWS Step Functions. Step Functions lets you define workflows that trigger a collection of Lambda functions using sequential, parallel, branching, and error-handling steps. With Step Functions and Lambda, you can build stateful, long-running processes for applications, and back-ends.
AWS Lambda functions are built as standalone elements, meaning each function acts as its own independent program. This separation also extends to resource allocation. For example, AWS provisions memory on a per-function basis rather than per application group. You can install any number of functions in a single operation, but each one has its own environment variables. Also, AWS Lambda always reserves a separate instance for a single execution. Each execution has its exclusive pool of memory and CPU cycles. Therefore, the performance is entirely predictable and stable.
AWS has been playing this game longer than all other serverless providers. However, there are no established industry-wide benchmarks, many claim that AWS Lambda is better for rapid scale-out and handling massive workloads, both for web APIs and queue-based applications. The bootstrapping delay effect (cold starts) is also less significant with Lambda.
Azure Functions
Azure Functions by Microsoft Azure, as a new player in the field of serverless computing, was introduced in the market in 2016, although they were offering PaaS for several years before that. Today, Microsoft Azure with Azure Functions is established as one of the biggest FaaS providers.
Azure Functions has built-in support for C#, JavaScript, F#, Node.js, Java, PowerShell, Python, and TypeScript programming languages and is working on bringing in support for additional languages in the future. All runtimes are maintained by Azure, provided on top of both Linux and Windows operating systems.
Azure Functions have a more sophisticated programming model based on triggers and bindings, helping you respond to events and seamlessly connect to other services. A trigger is an event that the function listens to. The function may have any number of input and output bindings to pull or push extra data at the time of processing. For example, an HTTP-triggered function can also read a document from Azure Cosmos DB and send a queue message, all done declaratively via binding configuration.
With Microsoft Azure Functions, you’re given a similar set of dynamic, configurable triggers that you can use to invoke your functions. They allow access via a web API, as well as invoking the functions based on a schedule. Microsoft also provides triggers from their other services, such as Azure Storage, Azure Event Hubs, and there is even support for SMS-triggered invocations using Twilio, or email-triggered invocations using SendGrid. It’s important to note that Azure Functions comes with HTTP endpoint integration out of the box, and there is no additional cost for this integration, whereas this isn’t the case for AWS Lambda.
Microsoft Azure offers multiple hosting plans for your Azure Functions, from which you can choose the hosting plan that fits your business needs. There are three basic hosting plans available for Azure Functions: Consumption plan, Premium plan, and Dedicated (App Service) plan. The hosting plan you choose dictates how your functions scaled, what resources are available to each function, and the costs. For example, if you choose The Consumption plan that has the lowest management overhead and no fixed-cost component, which makes it the most serverless hosting option on the list, each instance of the Functions host is limited to 1.5 GB of memory and one CPU. An instance of the host is the entire function app, meaning all functions within a function app share resources within an instance and scale at the same time. Function apps that share the same Consumption plan are scaled independently. In Azure Functions, the Consumption Plan default timeout is 5 minutes and can be increased to 10 minutes. If your function needs to run more than 10 minutes, then you can choose Premium or App Service plan, increasing the timeout to 30 minutes or even stretching it to unlimited.
The core engine behind the Azure Functions service is the Azure Functions Runtime. When a request is received, the payload is loaded, incoming data is mapped, and finally, the function is invoked with parameter values. When the function execution is completed, an outgoing parameter is passed back to the Azure Function runtime.
Microsoft Azure introduces Durable Functions extension as a library. Bringing workflow orchestration abstractions to code. It comes with several application patterns to combine multiple serverless functions into long-running stateful flows. The library handles communication and state management robustly and transparently while keeping the API surface simple. The Durable Functions extension is built on top of the Durable Task Framework, an open-source library that’s used to build workflows in code, and it’s a natural fit for the serverless Azure Functions environment.
Also, Azure enables you to coordinate multiple functions by building workflows with Azure Logic Apps service. In this way, functions are used as steps in those workflows, allowing them to stay independent but still solve significant tasks.
Azure Functions offers a richer set of deployment options, including integration with many code repositories. It doesn’t, however, support versioning of functions. Also, functions are grouped on a per-application basis, with this being extended to resource provisioning as well. This allows multiple Azure Functions to share a single set of environment variables instead of specifying their environment variables independently.
The consumption plan has a similar payment model as AWS. You only pay for the number of triggers and the execution time. It comes with 1 million free requests with 400,000 GB-seconds per month. It’s important to note that Azure Functions measures the actual average memory consumption of executions. If Azure Function’s executions share the instance, the memory cost isn’t charged multiple times but shared between executions, which may lead to noticeable reductions. On the other hand, The Premium plan provides enhanced performance and is billed on a per-second basis based on the number of vCPU-s and GB-s your Premium Functions consume. Furthermore, if App Service is already being used for other applications, you can run Azure Functions on the same plan for no additional cost.
Features: AWS Lambda vs Azure Function
(click to view the comparison)
Conclusion
As we see from a comparison of Azure Functions vs. AWS Lambda, regardless of which solution you choose, the serverless computing strategy can solve many challenges, saving your organization significant effort, relative to traditional software architecture approaches.
Although AWS and Azure have different architecture approaches for their FaaS services, both offer many similar capabilities, so it’s not necessarily a matter of one provider being “better” or “worse” than the other. Moreover, if you get into the details, you will see a few essential differences between the two of them. However its safe to say, it’s unlikely your selection will be based on these differences.
AWS has been longer on the market for serverless services. As good as it sounds, this architecture is not one-size-fits-all. If your application is dependent upon a specific provider, it can be useful to tie yourself strongly into their ecosystem by leveraging service-provided triggers for executing your app’s logic. For example, if you run a Windows-dominant environment, you might find that Azure Functions is what you need. But if you need to select one option of these two or if you switch among providers, it’s crucial to adjust your mindset and coding to match the best practices suggested by that particular provider.
To summarize, this post aims to point out the differences between the cloud providers, thus helping you choose the right FaaS that best suit’s your business.
Bojan Stojkov
Senior BackEnd Engineer at IT Labs

Why is Kubernetes more than a Container Orchestration platform?
Here at IT Labs, we love Kubernetes. It's a platform that allows you to run and orchestrate container workloads. At least, that is what everyone is expecting from this platform at a bare minimum. On their official website, the definition is as follows:
Kubernetes (K8s) is an open-source system for automating deployment, scaling, and management of containerized applications.
So, it adds automated deployments, scaling, and management into the mix as well. Scrolling down their official website, we can also see other features like automated rollouts and rollbacks, load-balancing, self-healing, but one that stands out is the "Run Anywhere" quote saying:
Kubernetes is an open-source giving you the freedom to take advantage of on-premises, hybrid, or public cloud infrastructure, letting you effortlessly move workloads to where it matters to you.
Now, what does this mean? How is this going to help your business? I believe the key part is "letting you effortlessly move workloads to where it matters to you." Businesses, empowered by Kubernetes, no longer have to compromise on their infrastructure choices.
Kubernetes as a Container Orchestration Platform
A bit of context
When it comes to infrastructure, the clear winners of the past were always the ones that managed to abstract the infrastructure resources (the hardware) as much as possible at that point in time.
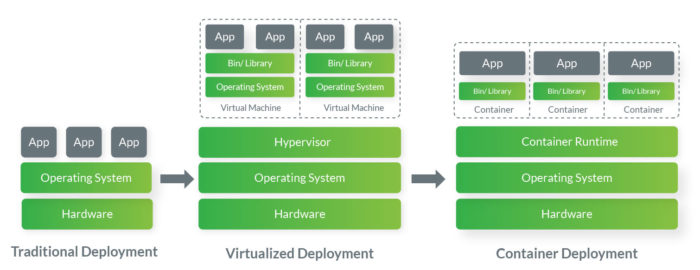 Each decade, a new infrastructure model is introduced that revolutionizes the way businesses are deploying their applications. Back in the 90s, computing resources were the actual physical servers in the backroom or rented at some hosting company. In the 2000s, Virtualization was introduced, and Virtual Machines (VMs) abstracted the physical hardware by turning one server into many servers.
Each decade, a new infrastructure model is introduced that revolutionizes the way businesses are deploying their applications. Back in the 90s, computing resources were the actual physical servers in the backroom or rented at some hosting company. In the 2000s, Virtualization was introduced, and Virtual Machines (VMs) abstracted the physical hardware by turning one server into many servers.
In the 2010s, containers took the stage, taking things even further, by abstracting the application layer that packages code and dependencies together. Multiple containers can run on the same machine and share the operating system (OS) kernel with other containers, each running and protected as an isolated process. In 2013, the open-source Docker Engine popularized containers and made them the underlying building blocks for modern application architectures.
Containers were accepted as the best deployment method, and all major industry players adopted them very quickly, even before they became the market norm. And since their workloads are huge, they had to come up with ways to manage a very large number of containers.
At Google, they have created their own internal container orchestration projects called Borg and Omega, which they used to deploy and run their search engine. Using lessons learned and best practices from Borg and Omega, Google created Kubernetes. In 2014, they open-sourced it and handed over to the Cloud Native Computing Foundation (CNCF).
In the 2010s, the cloud revolution was also happening, where cloud adoption by businesses was experiencing rapid growth. It allowed for even greater infrastructure abstraction by offering different managed services and Platform-as-a-service (PaaS). Offerings that took care of all infrastructure and allowed businesses to be more focused on adding value to their products.
The cloud transformation processes for businesses will continue in the 2020s. It's been evident that the journey can be different depending on the business use cases, with each company having its own unique set of goals and timelines. What we can foresee is that containers will remain the building blocks for modern applications, with Kubernetes as the best container orchestration platform, thus retaining its crown of being a necessity.
What is Kubernetes
Kubernetes enables easy deployment and management of applications with microservice architecture. It provides a framework to run distributed systems resiliently with great predictability.
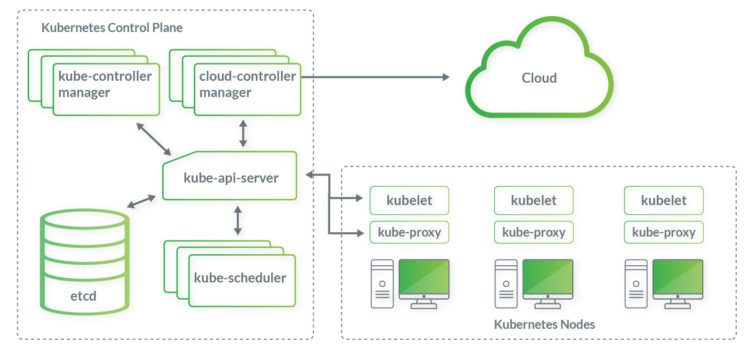
The main component of Kubernetes is the cluster, consisting of a control plane and a set of machines called nodes (physical servers or VMs). The control plane's components like the Kube-scheduler make global decisions about the cluster and are responding to cluster events, such as failed containers. The nodes are running the actual application workload – the containers.
There are many terms/objects in the Kubernetes world, and we should be familiar with some of them:
- Pod
The smallest deployable units of computing. A group of one or more containers, with shared storage and network resources, containing a specification on how to run the container(s)
- Service
Network service abstraction for exposing an application running on a set of pods
- Ingress
An API object that manages external access to the services in a cluster, usually via HTTP/HTTPS. Additionally, it provides load balancing, SSL termination, and name-based virtual hosting
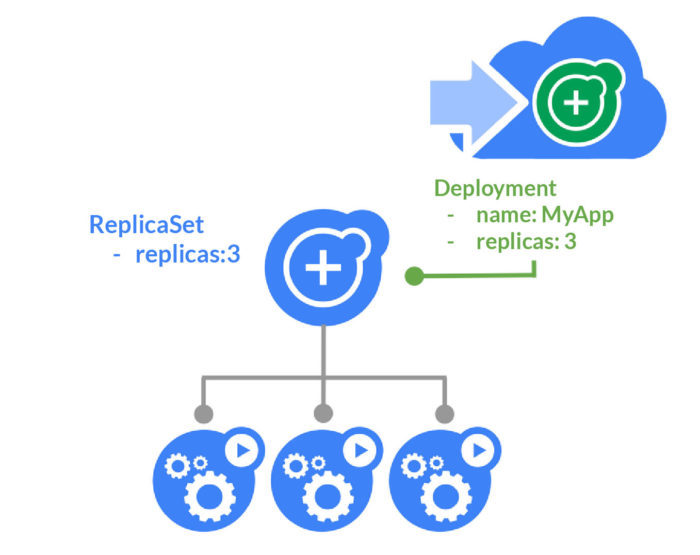
- ReplicaSet
The guarantee of the availability of a specified number of identical pods by maintaining a stable set of replica pods running at any given time
- Deployment
A declarative way of describing the desired state – it instructs Kubernetes how to create and update container instances
Additionally, Kubernetes (as a container orchestration platform) offers:
- Service Discovery and Load Balancing
Automatically load balancing requests across different container instances
- Storage Orchestration
Automatically mount a storage system of your choice, whether its local storage or a cloud provider storage
- Control over resource consumption
Configure how much node CPU and memory each container instance needs
- Self-healing
Automatically restarts failed containers, replace containers when needed, kills containers that don't respond to a configured health check. Additionally, Kubernetes allows for container readiness configuration, meaning the requests are not advertised to clients until they are ready to serve
- Automated rollout and rollback
Using deployments, Kubernetes automates the creation of new containers based on the desired state, removes existing container and allocates resources to new containers
- Secret and configuration management
Application configuration and sensitive information can be stored separately from the container image, allowing for updates on the fly without exposing the values
- Declarative infrastructure management
YAML (or JSON) configuration files can be used to declare and manage the infrastructure
- Extensibility
Extensions to Kubernetes API can be done through custom resources.
- Monitoring
Prometheus, a CNCF project, is a great monitoring tool that is open source and provides powerful metrics, insights and alerting
- Packaging
With Helm, the Kubernetes package manager, it is easy to install and manage Kubernetes applications. Packages can be found and used for a particular use case. One such example would be the Azure Key Vault provider for Secrets Store CSI driver, that mounts Azure Key Vault secrets into Kubernetes Pods
- Cloud providers managed Kubernetes services
As the clear standard for container orchestration, all major cloud providers are offering Kubernetes-as-a-service. Amazon EKS, Azure Kubernetes Service (AKS), Google Cloud Kubernetes Engine (GKE), IBM Cloud Kubernetes Service, and Red Hat OpenShift are all managing the control plane resources automatically, letting business focus on adding value to their products.
Kubernetes as a Progressive Delivery Enabler
Any business that has already adopted agile development, scrum methodology, and Continuous Integration/Continuous Delivery pipelines needs to start thinking about the next step. In modern software development, the next step is called "Progressive Delivery", which essentially is a modified version of Continuous Delivery that includes a more gradual process for rolling out application updates using techniques like blue/green and canary deployments, A/B testing and feature flags.
Blue/Green Deployment
One way of achieving a zero-downtime upgrade to an existing application is blue/green deployment. "Blue" is the running copy of the application, while "Green" is the new version. Both are up at the same time at some point, and user traffic starts to redirect to the new, "Green" version seamlessly.
 In Kubernetes, there are multiple ways to achieve blue/green deployments. One way is with deployments and replicaSets. In a nutshell, the new "Green" deployment is applied to the cluster, meaning two versions (two sets of containers) are running at the same time. A health check is issued for the "Green" deployment container replicas. If the health check pass, the load balancer is updated with the new "Green" deployment container replicas, while the "Blue" container replicas are removed. If the health check fails, then the "Green" deployment container replicas are stopped, and an alert is sent to DevOps, while the current "Blue" version of the application continues to run and serve end-user requests.
In Kubernetes, there are multiple ways to achieve blue/green deployments. One way is with deployments and replicaSets. In a nutshell, the new "Green" deployment is applied to the cluster, meaning two versions (two sets of containers) are running at the same time. A health check is issued for the "Green" deployment container replicas. If the health check pass, the load balancer is updated with the new "Green" deployment container replicas, while the "Blue" container replicas are removed. If the health check fails, then the "Green" deployment container replicas are stopped, and an alert is sent to DevOps, while the current "Blue" version of the application continues to run and serve end-user requests.
Canary Deployments
This canary deployment strategy is more advanced and involves incremental rollouts of the application. The new version is gradually deployed to the Kubernetes cluster while getting a small amount of live traffic. A canary, meaning a small subset of user requests, are redirected to the new version, while the current version of the application still services the rest. This approach allows for the early detection of potential issues with the new version. If everything is running smoothly, the confidence of the new version increases, with more canaries created, converging to a point where all requests are serviced there. At this point, the new version gets promoted to the title' current version.' With the canary deployment strategy, potential issues with the new live version can be detected earlier. Also, additional verification can be done by QA, such as smoke tests, new feature testing through feature flags, and collection of user feedback through A/B testing.
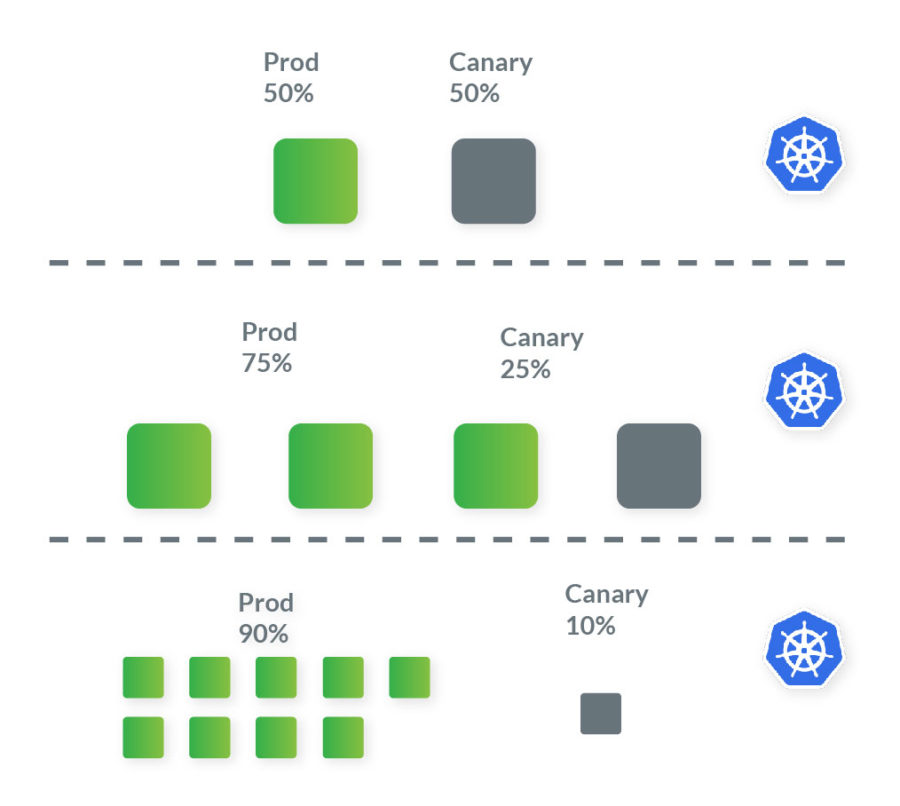 There are multiple ways to do canary deployments with Kubernetes. One would be by using the ingress object, to split the traffic between two versions of the running deployment container replicas. Another would be to use a progressive delivery tool like Flagger.
There are multiple ways to do canary deployments with Kubernetes. One would be by using the ingress object, to split the traffic between two versions of the running deployment container replicas. Another would be to use a progressive delivery tool like Flagger.
Kubernetes as an Infrastructure Abstraction Layer
Since more businesses are adopting cloud, cloud providers are maturing and competing with their managed services and offerings. Businesses want to optimize their return on investment (ROI), to use the best offer from each cloud provider, and to preserve autonomy by lowering cloud vendor lock-in. Some are obligated to use a combination of on-premise/private clouds, down to governance rules or nature of their business. Multi-cloud environments are empowering businesses by allowing them not to compromise their choices.
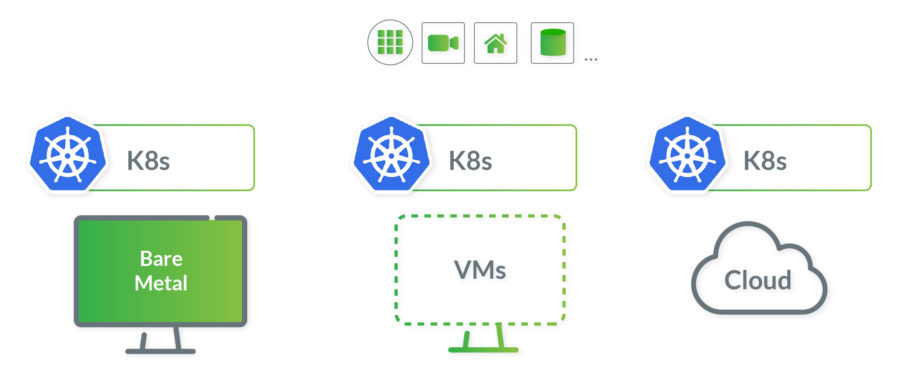 Kubernetes is infrastructure and technology agnostic, running on any machine, on Linux and Windows OS, on any infrastructure, and it is compatible with all major cloud providers. When we are thinking about Kubernetes, we need to start seeing it as an infrastructure abstraction layer, even on top of the cloud.
Kubernetes is infrastructure and technology agnostic, running on any machine, on Linux and Windows OS, on any infrastructure, and it is compatible with all major cloud providers. When we are thinking about Kubernetes, we need to start seeing it as an infrastructure abstraction layer, even on top of the cloud.
If a business decides on a cloud provider and later down the road, that decision proves to be wrong, with Kubernetes that transition to a different cloud provider is much less painful. Migration to a multi-cloud environment (gradual migration), hybrid environment, or even on-premise can be achieved without redesigning the application and rethinking the whole deployment. There are even companies that provide the necessary tools for such transitions, like Kublr or Cloud Foundry. The evolving needs of businesses have to be met one way or the other, and the portability, flexibility, and extensibility that Kubernetes offers should not be overlooked.
This portability is of great benefit to developers as well, since now, the ability to abstract the infrastructure away from the application is available. The focus would be on writing code and adding value to the product, while still retaining considerable control over how the infrastructure is set up, without worrying where the infrastructure will be.
"We need to stop writing infrastructure… One day there will be cohorts of developers coming through that don't write infrastructure code anymore. Just like probably not many of you build computers." - Alexis Richardson, CEO, Weaveworks
Kubernetes as the Cloud-Native Platform
Cloud-native is an approach to design, build, and run applications that have a set of characteristics and a deployment methodology that is reliable, predictable, scalable, and high performant. Typically, cloud-native applications have microservices architecture that runs on lightweight containers and is using the advantages of cloud technologies.
The ability to rapidly adapt to changes is fundamental for business in order to have continued growth and to remain competitive. Cloud-native technologies are meeting these demands, providing the automation, flexibility, predictability, and observability needed to manage this kind of application.
 Conclusion
Conclusion
 Conclusion
ConclusionWith all being said, it can be concluded that Kubernetes is here to stay. That's why we use it extensively here at IT Labs, future-proofing our client's products and setting them up for continuing success. Why? Because It allows businesses to maximize the potential of the cloud. Some predict that it will become an invisible essential of all software development. It has a large community that puts great effort to build and improve this cloud-native ecosystem. Let's be part of it.
Kostadin Kadiev
Technical Lead at IT Labs

What is GDPR and how does it affect software companies?

Maja Lazarovska
Prospecting Manager at IT Labs
The General Data Protection Regulation (GDPR) is an EU data privacy law that went into effect on May 25, 2018. It’s designed to give individuals more control over how their data is collected, used, and protected online. It also binds organizations to strict new rules about using and securing personal data they collect from people, including the mandatory use of technical safeguards like encryption and higher legal thresholds to justify data collection.
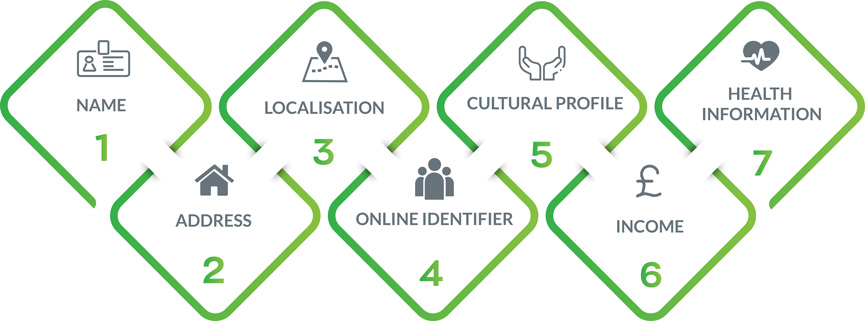
Application
Whom does the data protection law apply to?
The GDPR applies to:
- A company or entity which processes personal data as part of the activities of one of its branches established in the EU, regardless of where the data is processed; or
- A company established outside the EU and is offering goods/services (paid or for free) or is monitoring the behavior of individuals in the EU.
The law does not apply if the company is a service provider based outside the EU, or provides services to customers outside the EU. Its clients can use its services when they travel to other countries, including within the EU. Provided that the company doesn’t specifically target its services at individuals in the EU, it is not subject to the rules of the GDPR.
The protection offered by GDPR travels with the data, meaning that the rules protecting personal data continue to apply regardless of where the data lands. This also applies when data is transferred to a country which is not a member of the EU.
The rules only apply to personal data about individuals; they don’t govern data about companies or any other legal entities.
Does GDPR Apply to the US?
GDPR applies in the US, following the points described above – if the company offers goods or services to EU/EEA residents or if the company monitors the behavior of users inside the EU/EEA.
Moreover, if a data subject from the EU living in the US would fall under the GDPR should their personal data be processed by an EU established data controllers (an entity that makes decisions about processing activities) or data processors (the ones that process personal data on behalf of the controller). Conversely, a data subject from the EU living in the US would not fall under the GDPR should their personal data be processed by a purely US established data controllers or data processors.
Small and medium-sized enterprises
The rules apply to SME, but with exceptions. Companies with fewer than 250 employees don’t need to keep records of their processing activities unless processing of personal data is a regular activity, poses a threat to individuals’ rights and freedoms, or concerns sensitive data or criminal records.
Similarly, SMEs will only have to appoint a Data Protection Officer (DPO) if the processing is their main business, and it poses specific threats to the individuals’ rights and freedoms. This includes monitoring of individuals or processing of sensitive data, or criminal records, specially if it’s done on a large scale.
Principles
Key rules about data processing and conditions:
- Lawfulness, fairness, and transparency: personal data must be processed lawfully and transparently, ensuring fairness towards the individuals whose personal data is being processed. When data is obtained from another secondary company/organization, the primary company should provide the information (who, why, how long, etc.) to the person concerned at the latest, within one month after your company obtained the personal data;
- Purpose limitation: there must be specific purposes for processing the data, and the company must indicate those purposes to individuals when collecting their data, the company should explain in clear and plain language why they need it, how they’ll be using it, and how long they intend to keep it;
- Data minimization: the company must collect and process only the personal data that is necessary to fulfill that purpose. IT must be adequate, relevant, and within a limited scope of use;
- Accuracy: the company must ensure personal data is accurate and up-to-date, having regard to the purposes for which it is processed, and correct it if not;
- Compatibility: the company can’t further use the personal data for other purposes that aren’t compatible with the original purpose;
- Storage limitation: the company must ensure that personal data is stored for no longer than necessary for the purposes for which it was collected. The company should establish time limits to erase or review the data stored;
- Integrity and confidentiality: the company must install appropriate technical and organizational safeguards that ensure the security of personal data, including protection against unauthorized or unlawful processing and accidental loss, destruction or damage, using appropriate technology.
 Legal grounds for processing data
Legal grounds for processing data
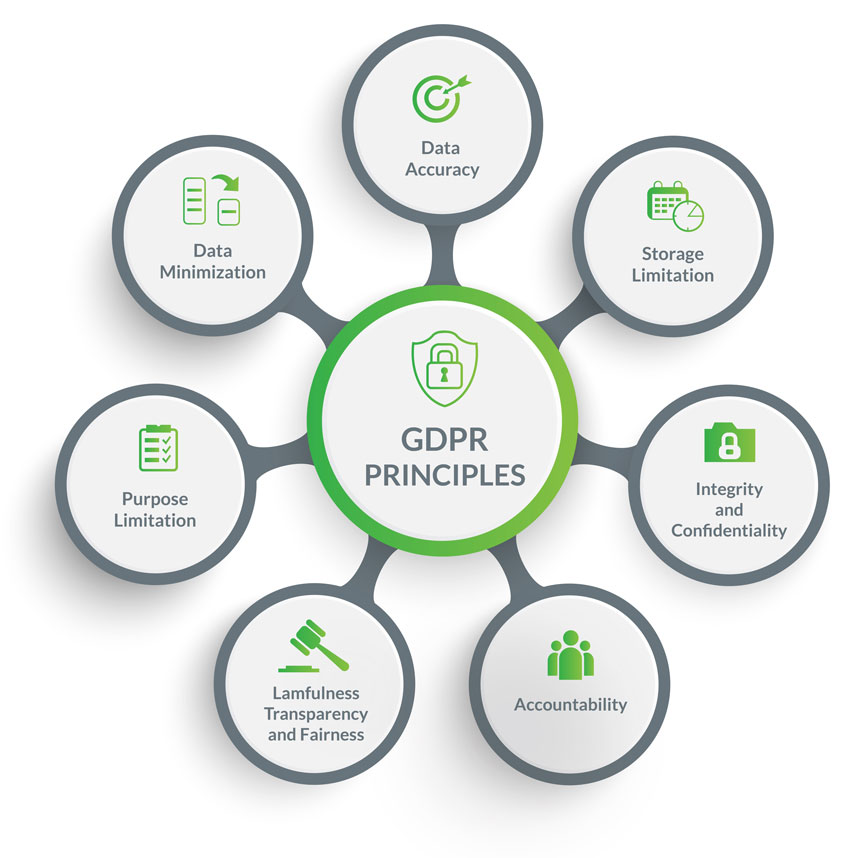 Legal grounds for processing data
Legal grounds for processing dataIf consent is withdrawn, the company can no longer process the data. Once it has been withdrawn, the company needs to ensure that the data is deleted unless it can be processed on another legal ground (for example, storage requirements or as far as it is a necessity to fulfill the contract).
Obligations
Data controller and data processor
The data controller determines the purposes for which, and the means, by which personal data is processed. So, these are companies that decide ‘why’ and ‘how’ the personal data should be handled.
The company is considered as a joint controller, when together with one or more organizations, it jointly determines ‘why’ and ‘how’ personal data should be processed.
The data processor is usually a third party external company. The data processor processes personal data only on behalf of the controller. The duties of the processor towards the controller must be specified in a contract or another legal act.
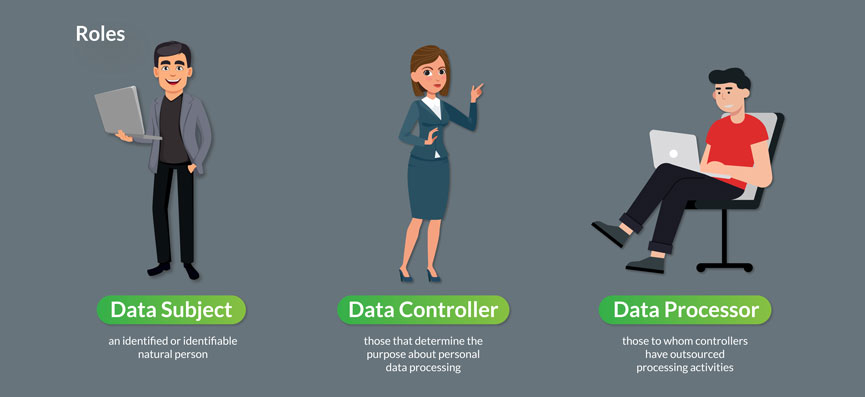
Data breach
If a breach occurs, the company has to notify the supervisory authority without undue delay and at the latest within 72 hours after having become aware of the breach. If the company is a data processor, it must notify every data breach to the data controller.
Demonstrating GDPR compliance
It can be a Code of Conduct prepared by a business association that has been approved by a Data Protection Authorities (DPA). A Code of Conduct may be given EU-wide validity through an implementing act of the Commission.
It can be a certification mechanism operated by one of the certification bodies that have received accreditation from a DPA or a national accreditation body or both, as decided in each EU Member State.
GDPR and software development
Every new piece of software should be fully GDPR compliant. GDPR requires companies to safeguard their users’ data and protect their privacy rights. Companies that handle personal data of European users must build their systems and processes with data protection by design and by default. Proper security measures must be taken like firewalls, encryption, data backup, etc.
When a company decides to outsource some of its functions, it remains responsible for the personal data transferred to the outsourcing vendor. The only way for a company to avoid GDPR liability is to ensure that it cannot access any personally identifiable data under any circumstances, which is often impossible in practice.
In other words, the GDPR places a huge emphasis on documentation and transparency. Companies must be able to clearly describe what data they are collecting, for what purpose, for how long, and who can access them, among other things. It’s important to share relevant documents, in order to be able to prove that the necessary steps for GDPR are taken.
While the GDPR doesn’t require companies that collect data from EU citizens to provide their users with automated, real-time tools for data management, it’s in every company’s best interest to do so. Without automated data management capabilities, each data-related request would have to be followed by a lengthy identity verification process to prevent data breaches.
Key requirements
- Pseudonymization by Default: Pseudonyms must be created for each individual, and data about the person’s identity should be stored in an area that is fully partitioned and separate from other user data. Such as information on the individual’s account within an app or software platform.
- The Right to Be Forgotten: Every EU citizen has “the right to be forgotten,” meaning that, upon request, companies are required to discard any and all personal data related to a particular individual. Therefore, the software or database should include tools that let you isolate and delete personal data as needed.
- The Right to Be Portable: Under this requirement, users must retain the ability to transfer their personal data from one service provider to another service provider. The company needs to configure the software, so it allows users to do so.
- Mandatory Data Breach Reporting: If there is a data breach, the company is required to inform users and law enforcement within 72 hours. This means the company must detect a data breach in a very short order. When developing software or a mobile app, it’s generally best to maximize security measures and include a security breach detection and reporting tool that can send notifications to the tech team.
- Privacy by Design: GDPR requires privacy by default, meaning that the software, mobile app, or website must, by default, provide users with the highest level of security and privacy. For instance, instead of automatically using a person’s name or email address as their username, the software should offer up a totally random username during the account creation process.
- Informed Consent: Users must be allowed to provide informed consent for the collection and processing of their data. This is why so many privacy-related disclaimer panels have popped up on websites, software platforms, and mobile apps in recent months. Another example of informed consent applies to tickboxes when registering for an account. In most cases, tick boxes should not be ticked by default; the user must tick them manually.
Compliance checklists
- What information do I really need?
- Why am I saving it?
- Why am I archiving this information instead of just erasing it?
- What am I trying to achieve by collecting all of this personal information?
Dealing with citizens
- Individuals may contact the company to exercise their rights under the GDPR (rights of access, rectification, erasure, portability, etc.).
- The company must reply to their request without undue delay, and in principle, within one month of receipt of the request.
- Dealing with requests of individuals should be carried out free of charge.
- The company must provide the individual with a copy of their personal data free of charge.
- The GDPR gives individuals the right to ask for their data to be deleted and organizations do have an obligation to do so, except if the data is needed to exercise the right of freedom of expression, the company has a legal obligation to keep it, or it keeps it for reasons of public interest;
- Individuals have the right to object to the processing of personal data for specific reasons. Whether such a particular situation exists must be examined on a case-by-case basis.
- Individuals have the right to data portability, which is to receive from the company the personal data they provided in a structured, machine-readable format, and have it transmitted to another company/organization.
- Individuals should not be subject to a decision that is based solely on automated processing (such as algorithms), and that is legally binding or which significantly affects them.
Enforcement and sanctions
The company does not need to notify the DPA (Data Protection Authority) that it processes data. However, prior consultation with the DPA is required when a DPIA indicates that the processing of the data would pose a high risk, and residual risks remain despite the implementation of several safeguards. Your company/organization would also need to contact the DPA in the case of a data breach.
In case of non-compliance with the data protection rules infringement: the possibilities include a reprimand, a temporary or definitive ban on processing, and a fine of up to €20 million or 4% of the business’s total annual worldwide turnover.
References
https://ec.europa.eu/info/law/law-topic/data-protection/reform/rules-business-and-organisations
https://gdpr.eu/companies-outside-of-europe/?cn-reloaded=1
https://brainhub.eu/blog/gdpr-secure-software-development-practices/
https://seventablets.com/blog/how-to-ensure-gdpr-compliance-for-software-development-projects/
https://www.datatilsynet.no/en/about-privacy/virksomhetenes-plikter/innebygd-personvern/data-protection-by-design-and-by-default/?print=true
Maja Lazarovska
Prospecting Manager at IT Labs

Designing social platforms in an evolving landscape

There are many types of users using Social Networks, and we are not talking small numbers here. Everything from end-users like you and I, to administrators, and all way through to advertisers. With millions of users using these platforms, you can easily imagine how they can become very demanding from a software and hardware perspective. It’s not an easy system to get in place and maintain. This makes the subject of social networks quite intriguing. Let’s dig a little deeper into the requirements and explore them further.
1. Requirements
Constant change – Change is the only constant, and social networks are not immune from the innovation storm that we all operate in. If any software doesn’t change, renewing itself in some way, it’s users simply lose interest. Social networking platforms are very demanding in this area; they need to adapt and change all the time. They steal ideas from one another alongside innovating with new ones. They constantly experiment, trying out ideas, applying them to small populations of users or user groups. Sometimes it creates desirable results, where the design is taken forward and published to the world.
High performance - Ten years ago, if you made some requests on an application, and the results returned within five seconds, that would have been acceptable1. Granted that some users would get impatient and annoyed, but not everybody. Nowadays, if requests last longer than a second, people will lose interest in using the application2. Having good performance is crucial with the modern human’s attention span, especially for social networking platforms. Simply put, high performance is all-important.
Easy UX – The next important requirement is being able to navigate the platform with ease. Being able to find your way around within the application is an essential aspect of user experience3. Not being able to see where you are, how you can continue, and how you can do the things you want to do, is something that will push users away from this site.
There are many types of users with their unique requirements and ways of using the platforms. Firstly there is the end-user. Like most of us reading this, we are end-users of social networks, and we expect everything already discussed above to happen. Next, there are advertisers. Advertisers are a crucial part of these platforms. They are the main revenue engine for social networks, so they are not easily ignored by the business. Finally, there are the page admins. A case in point is Facebook, where you have pages that you want to administer. For this, you need some special credentials and rules and whatnot. There are also some other features regarding the usage, but focusing on the abovementioned is enough for now.
2. Change and evolve
Social networking platforms are fine as they are. Still, we, the architects, are expected to do the architecture at the very beginning and have that same architecture remain as long as the social network remains alive. For example, Facebook has been live for more than 15 years, designing something at the beginning to withstand the changes of time is practically impossible.
If we make some analogy between Waterfall and Agile as project management types, we can say that, under the Waterfall approach, you are asking for all the requirements to be set at the beginning. Once you get all the requirements, once you have all the documentation, etc., it’s easy for you to follow the project and do what needs to be done4.
In the Agile world, it’s very different. You cannot simply require all those things upfront. You must adapt to never-ending changes every iteration. So, if the requirements are constantly changing, should the architecture also change? Can we make it possible for the architecture to evolve together with the requirements5?
Before we dive into that, to create context around what we are discussing, we will cover some important information to help the discussion.
2.1 Architectural types
Let’s discuss what architectural types there are.
Technical architecture type – What does this mean? This is in the realm of software engineers and developers. It includes frameworks, different libraries, connection types between classes, and all things technical related to the platform.
Data architecture type - This architecture focuses on everything that’s related to data. It can be database schemas, table layouts, any kind of data redundancies, replica servers, etc.
Security architecture type - When we discuss the security architecture, we are thinking about security measures, legal compliance, any guidelines that need to be taken care of.
Domain-Driven architecture - Probably one of the most recently discussed architecture types. Domain-Driven architecture focuses on the bounded context. A bounded context is a group of functionalities that work together, and only a few of those properties are exposed to the outside world. The idea behind the bounded context is that everything that is done inside this context remains the same and doesn’t break the logic of anything else outside of that context.
So we have covered the architectural types. Let’s now build up the picture further with architectural models.
2.2 Architectural models
N-tier monolith - The first well-known architectural model is the layered, or monolith-architectural model. Some call it the n-tier architectural model.
In the layered architectural model illustrated above, we have five different layers. In the ideal world, you should be able to change anything in any of those layers, and everything will work perfectly without affecting the behaviour of the others. For example, changes in the service layer have no impact outside оf itself. In a perfect world, you don’t need to touch any of the outside layers, and the application would continue to work correctly. However, experienced developers of this type of architecture are aware that this is not quite true, if at all.
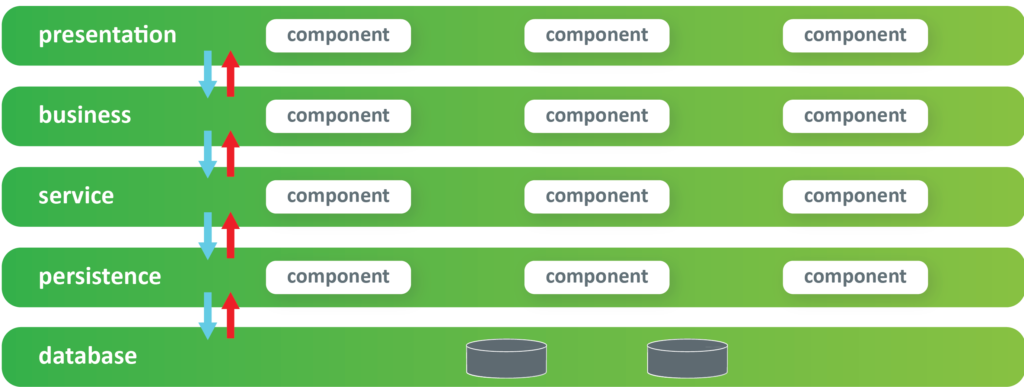
The second important thing about this architecture is that we have constant flow through the layers, up and down. The requests go from the topmost layer to the bottommost layer, and the responses go back from the bottommost layer to the uppermost layer. However, from time to time, some of these layers are not relevant for every request6 (even not needed in most cases). For example, in the illustration below, the service layer is not required and is therefore skipped.
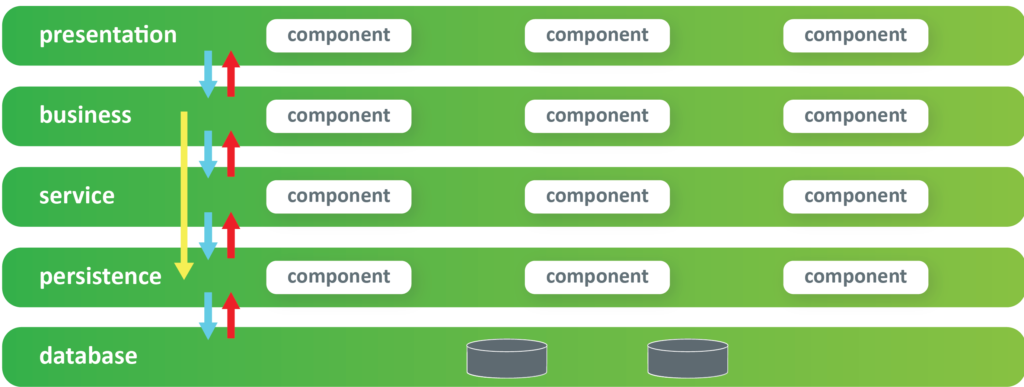
This notion is known as sinkhole anti-pattern architecture, where one of those layers is not required in most requests7. In this case, we simply skip this layer. Skipping layers, and by accepting this type of work, we have a notion of creating as many connections as necessary, and as tighter of coupling as needed, which is generally very bad for the architecture.
The next thing for consideration is the architecture. Let’s assume that we would like to change some of the domains in the application. For example, “feeds” feature that most of the social networks have nowadays. If we want to change a “feed” feature, we need to make the changes in all of these layers. That being said, the domain aspect of this application is not very well defined. This type of architecture is something that we don’t want to use if we are concerned about Domain-Driven Design. If this is not okay, the next thing that we do is to try to separate all these functionalities into separate domain models.
Let’s discuss models through an example. We have one functionality for the “feeds” in the first domain model. We have another functionality for the “ads”, in the second domain model, and everything else in the third domain model. This is okay as a concept. The only thing that is problematic here is the database. Let’s imagine that we have a 10+-year-old solution; it still lives and is being maintained and expanded. The database itself has vast amounts of tables and connections, are holding millions of records. It’s not easy to go to the database designer (or anybody that cares about the database and its data) and ask of them to simply split the database in a way the new architecture would prefer it to be divided. In practice, this is very hard, and in many examples, close to impossible when we take into consideration the time and budget needed. So, even though the Domain-Driven design is a good approach, we still have tight coupling when it comes to the database.
Next, a similar approach to this is microkernel architecture. In the context of this article, when we speak of microkernel architectures, we are referring to plugins8. An important point here is that these plugins are not focused on domains, but services. For example, browsers have microkernel architectures. You can put all different plugins in a certain browser, but all those plugins are service-based. They are rarely grouped regarding the domain.
Let us discuss a very well-known micro-services architecture. Many of us are aware of this architecture. It represents the ability to separate the domains as much as we need. With all domains being separated, it allows us to expand this architecture in multiple domains9. This is a good architecture to take as a Domain-Driven (Design) architecture.
Now, on top of the microservices approach, we can build something similar to HATEOAS architecture. It stands for “Hypermedia as the Engine of Application State”, where each response carries within itself other hyperlinks that will guide you further through the application10. This application can be built using microservices architecture, but it’s more of conceptual architecture rather than a technical one.
3. Practical Aspects
Let’s discuss a little bit about the practical aspects of architecture. When we consider social networks, as previously mentioned, we need to be able to change, adapt, and upgrade the architecture constantly. For this, we need to take care of several things.
3.1 Dimensions
We need to identify and prioritize the dimensions that are important to the outcome we are trying to achieve. There are many dimensions to any architecture, and it's imperative we prioritize what is most important to the platform. Examples of dimensions are audit-ability, performance, security, data, legality11, and scalability12. By determining these dimensions, we can focus on what is necessary for our application. Once we have determined priority, we can then focus on how to measure and constantly improve these dimensions. We do this by using so-called “fitness functions”.
3.2 Fitness functions
Fitness functions are tests for non-functional requirements in the application13. Implementing these fitness functions will help us determine the cost of maintenance. Let’s initially discuss some possibilities for fitness functions.
If performance is important to us, we need to implement functions that, with each delivery, will test our application for its performance. If, for example, a page request takes longer than one second (and one second is our limit), we become aware that there is a problem. We do not push the release live; instead, we resolve the issue there and then.
The second fitness function might be about environmental elasticity. Most of us are using Cloud environments, and we are aware that in a Cloud environment, there are possibilities to extend your fleet of servers in an elastic way. Whenever there is a huge amount of requests, the Cloud can, by itself, raise new servers, new instances, or maybe new docker instances (whatever is necessary). That way, it manages to service all requests. The question arises, are those instances raised when we need them? How can we test that? A very simple way to test the elasticity of a cloud environment is to establish a test environment on the Cloud, prepare load tests, and run them as many times as we need. This allows us to monitor and measure the instances of how they behave in specific scenarios and conditions. If, for example, we have 4,000 requests, and we are expecting a new instance to be raised, you can see if things transpire as planned. If the application doesn’t behave correctly, we can act to remedy the issue accordingly. The same goes for bringing down instances. When we reduce the number of requests, we observe to see if the application behaves as it should. If it doesn’t, then we know we need to make changes.
The next type of fitness function is to create a listener inside your application. The listener indicates what functions and methods are used in an application. If we are building code for 10+ years, we have lots of legacy code that most probably doesn’t even need to be there anymore. If we have any type of fitness functions that test what methods are executed and those that are not, and we have a report of that, we can easily clean our code of unnecessary items14.
Another example could be around accessibility for people with disabilities. Each time we push a release to the public, we can run the accessibility tests15. If there are any incorrect pages displayed which don’t fully support what our user needs, we can simply roll back the deployment and correct those issues.
The last one we will discuss here is the ability for all services to fail gracefully. We all know what this means. There are tons of services in our microservice application, and we must be aware of how those services function. Some of those services will most likely break16. When this happens, we need to be prepared so that we know what’s going on in our architecture and how our application is behaving.
3.3 Feature toggles
The article so far has discussed that we need to be aware that our architecture will evolve and change constantly. So, how do we get prepared to welcome the changes? How do we present small types of deployments to certain parts of the solution, and to test them?
This is where feature toggles come into play. The feature toggle set is a kind of functionality where we can switch on and off different features depending upon when we need them, how we need them, etc. These feature toggles are quite good for several things that we need to do17.
One feature toggle is A/B tests. We have tons of services, and we should be able to do A/B tests for all those services. A/B test allows us to make a comparison between two or more different implementations on a single service or functionality. Ones we are satisfied with one of the implementations, we should be able to toggle off the other ones or just simply remove them if needed.
Another one is canary releases. Canary releases are small chunks of releases for only a certain group of users. For example, when we have new functionality in our application, and we don’t know whether the end-user will accept this functionality. Using the approach of the canary releases, we can create a new service and toggle this functionality only a specific set of users. A few examples to illustrate this could be employees in our office alone, or maybe for only one geographical state. This way, this user group can be testers for our new functionality. Since these functionalities will be tested on a production environment, with the testing group being the actual test users, this can be described as the best testing group an application can ever have ?, although I don’t recommend doing this too often18.
Another possibility where we can use this fitness function is in experimentation. Again, if there is something new that we would like to experiment with, and see how it is received, or will it work correctly, then we can use fitness functions to toggle the functionalities of the code.
3.4 Maintenance
One important thing besides monitoring the services is that we must be able to track the routes between them. Why is this routing important? The monitoring of them is important because we will know when one of the services stops, which implicitly means that no other services are routing to it. If any are no longer being routed to, they should automatically be removed from the ecosystem. The business needs should determine the conditions and resulting response to whether a service is being routed to or not. This is another example of a fitness function.
4. Conclusion
All of what we have discussed in this article helps us manage changing requirements better. Thus, allowing architects to modify and change our architectures in unison with changing conditions. We should be able to evaluate the impact of any modifications quickly, and decide whether to push changes forward, fine-tune them, or roll them back. As you can see, all these approaches allow for an evolutionary architecture for our software.
So, to do a little recap… To be able to embrace the future of our architecture so it can change and evolve, initially, we need to design it in the Domain-Driven fashion. The second thing is that we should identify our priorities. We cannot test and monitor everything. Based on our priorities, we should be able to create fitness functions, at least for the most important cases. Besides other things, being able to develop fitness functions will also allow us to measure the cost of maintenance more easily. The price of maintenance in terms of effort, time, and money is one of the most important things for a software architect. Feature toggles are a good tool to deploy small parts and to test them, see how the application behaves and how the end-users receive them, and then depending on needs, turning the functionality or the service on or off. As for maintenance, being able to know how services are performing and which are no longer used will allow us to keep the solution clean and neat, thus enabling more efficient maintenance.
By: Ilija Mishov, Co-Founder of IT Labs
Co-author: Erin Traeger, Business Analyst at IT Labs
_____________________________
1 In 2011 perhaps 35% abandon by the time it’s 10 seconds, 25% at 4 seconds, which indicates a higher tolerance. https://royal.pingdom.com/the-software-behind-facebook/
2 In 2016, some sites had an INCREASE in load time whilst trying to offer a more immersive experience. This hurt their sales. Included is a statistic “Split second” for Nordstrom, which says, “Nordstrom saw online sales fall 11% when its website response time slowed by just half a second.” Note that at that time, they believed 2.5 second load time was ideal. https://www.bbc.com/news/business-37100091
As of 2018, the bounce rate was 32% for 1-3 second load time – see infographic at https://www.thinkwithgoogle.com/marketing-resources/data-measurement/mobile-page-speed-new-industry-benchmarks/
3 Overall, UX is very important. But interestingly enough, in 2018, research conducted amongst mobile users indicates millennials not only “are more likely to blame a slow learning curve on the app itself. They won’t keep using an app if it frustrates them or doesn’t fulfill their needs.”, but also “Suprisingly, millennials may be attracted to Snapchat because its design is more complicated and less intuitive than other apps.” Further within, it argues that Snapchat is an example of “shareable design”, which “requires users to learn by watching others.” - https://themanifest.com/mobile-apps/what-makes-social-media-apps-successful
4 NGuru99 – Waterfall can have phases, though, so changes do occur. https://www.guru99.com/waterfall-vs-agile.html
5 “On an agile project you assume that you cannot fix the requirements of the system up-front. As a result having a detailed design phase at the beginning of a project becomes impractical The architecture of the system has to evolve through the various iterations of the software. Agile methods, in particular extreme programming (XP), have a number of practices that make this evolutionary architecture practical.” - https://www.martinfowler.com/articles/evodb.html
6 “Challenges” section backs up Ile’s statements about layers that aren’t needed for every request, “It’s easy to end up with a middle tier that just does CRUD operations on the database, adding extra latency without doing any useful work.” - https://docs.microsoft.com/en-us/azure/architecture/guide/architecture-styles/n-tier
7 What architecture sinkhole anti-pattern is – see 2nd and 3rd paras under “Considerations”. It recommends that if 80 percent (from the 80-20 rule) are simple pass-through processing, then you may want to consider making some of the architecture layers open. https://www.oreilly.com/library/view/software-architecture-patterns/9781491971437/ch01.html.
Another mention of sinkhole antipattern - https://medium.com/@priyalwalpita/software-architecture-patterns-layered-architecture-a3b89b71a057
8 The article https://medium.com/@priyalwalpita/software-architecture-patterns-microkernel-architecture-97cee200264e in the “Pros” and “cons” sections gives reasons this wouldn’t be ideal for a high-traffic social network. Explains that there is the core and then plugins, with core containing minimal functionality needed to run the system. Also explains that generally not the ideal pattern to be used in high-performance applications, not highly scalable, and requires a thorough analysis of the design before implementation.
9“Microservices” section –Also discusses advantages that correlate with what you’d want on a social network – “ability to scale only microservices needing to be scaled.” “Easier to rewrite pieces of the application because they’re smaller and less coupled to other parts.” As well, it says it’s ideal for “applications that would become very complex if combined into one monolith.”, which for social networks always needing to push out new features, this would happen. - https://dzone.com/articles/software-architecture-the-5-patterns-you-need-to-k
10 Good explanation of what HATEOAS is, why you’d want it, such as under the section “Why do we need HATEOAS?”: “The single most important reason for HATEOAS is loose coupling. If a consumer of a REST service needs to hard-code all the resource URLs, then it is tightly coupled with your service implementation. Instead, if you return the URLs it could use for the actions, then it is loosely coupled. There is no tight dependency on the URI structure, as it is specified and used from the response.” - https://dzone.com/articles/rest-api-what-is-hateoas
11“Chapter 4. Scalability and Performance” – “A production-ready microservice is scalable and performant.” “Efficiency is of the utmost importance in real-world, large-scale distributed systems architecture, and microservices ecosystems are no exception to this rule. Scalability and performance are uniquely intertwined because of the effects they have on the efficiency of each microservice and the ecosystem as a whole…So, while scalability is related to how we divide and conquer the processing of tasks, performance is the measure of how efficiently the application processes those tasks.” - https://www.oreilly.com/library/view/production-ready-microservices/9781491965962/ch04.html
12 Mentions how to handle data management and questions you should ask before implementing a microservice solution. The questions touch on data, auditability, security, legality…(see very start of article) - https://www.ibm.com/garage/method/practices/code/data-management-for-microservices?lnk=hm
13 Section “What is a Fitness Function?” – “…real-world architecture consists of many different dimensions, including requirements around performance, reliability, security, operability, coding standards, and integration, to name a few. We want a fitness function to represent each requirement for the architecture….Performance requirements make good use of fitness functions…Performance testing should be conducted early and frequently, in particular to pick up inflection points when performance changes radically (usually in the wrong direction) because of an update to code.” - https://books.google.com/books?id=pYI2DwAAQBAJ&pg=PA18&dq=%22fitness+functions%22+for+testing+non-functional+requirements&hl=mk&sa=X&ved=0ahUKEwiPtpD-nO3oAhWCLc0KHWKgC74Q6AEIJjAA#v=onepage&q=%22fitness%20functions%22%20for%20testing%20non-functional%20requirements&f=false
14 Interesting article arguing that fitness functions can be used to determine best method of refactoring and save money - https://deepblue.lib.umich.edu/bitstream/handle/2027.42/147343/papertse.pdf?sequence=1&isAllowed=y
15 Lists accessibility as a non-functional requirement that can be tested by reviewing the application code à fitness functions can be used. (Note that there were some discussions elsewhere which indicated some consider this functional, others a combination of functional and non-functional.) - https://www.batimes.com/articles/non-functional-requirements-why-do-we-need-them.html
16 “Design for Failure” (pg26 pdf) and “Support for failure” (pg 26 pdf) – “The more microservices there are, the higher the likelihood at least one is currently failing”, “Key: design every service assuming that at some point, everything it depends on might disappear – must fail “gracefully”, “Goal: Support graceful degradation with service failures” - https://cs.gmu.edu/~tlatoza/teaching/swe432f17/Lecture%2011%20-%20Microservices.pdf
17 This article covers the toggles mentioned and backs up reasons for using them. - https://martinfowler.com/articles/feature-toggles.html
18 On pp34-35, “By implementing new features hidden underneath feature toggles, developers can safely deploy the feature to production without worrying about users seeing it prematurely.”, “One beneficial side effect of habitually building new features using feature toggles is the ability to perform QA tasks in production.” https://books.google.com/books?id=pYI2DwAAQBAJ&pg=PA170&lpg=PA170&dq=%22fitness+functions%22+feature+toggles&source=bl&ots=jGsuqTS4Sb&sig=ACfU3U2BRB1l810ouLVMeoUmqSNTqtvk4g&hl=mk&sa=X&ved=2ahUKEwi70_jQru3oAhUKCc0KHbOLBscQ6AEwAXoECAsQJw#v=onepage&q=%22fitness%20functions%22%20feature%20toggles&f=false

Fast transformation of work environments due to COVID-19 crisis
The Covid-19 crisis has created shock-waves in all aspects of our lives, in particular, the workplace. It's safe to say that workplaces will never be the same again. Starting with the very word, "workplace", previously it was a place where people traveled to work, now is blended with the places where we eat, sleep, exercise, play, and socialize. It's impacted how people learn, work, and socialize in so many ways.
![]()
On a positive note, this crisis has created an opportunity to design something that many organizations were slowly trying to embrace. Many were scared even to contemplate it. From an organizational perspective, the crisis is a valuable opportunity to change the way we work, benefiting the business and the precious people that work in them. Thus, bringing us to the subject of "Fast transformation of the work environment". By digitalizing our communications and putting in place tools for remote collaboration, we can redesign how our employees converse with each other, as well as with clients, customers, and vendors. And if done well, this can potentially be a significant winning point for success.
Switch to fully digital working environments
Post-virus winners will be the organizations that have quickly recognized the change and have the courage to jettison their old paradigms and start afresh. Many organizations have promptly figured out how to adapt and how to serve customers and clients remotely. From public schools remote-learning, streaming fitness classes, to tele-medicine in hospitals, every industry has accelerated its own digital working environment transformation.
Leaders need to prepare, setting expectations for the ways of working that will benefit the organization down the road so that employees can focus on the strategic business priorities of the future.
Many organizations will see and sense the opportunity to capitalize on the cost savings by switching to full digital working environments, thus reducing their operational costs.
Switching to fully digital working environments doesn't have to be overwhelming. It's not something to check off a list, but instead a mindset that becomes part of the organization's culture and experience.
Let us now cover the key elements that bring about the best results as part of this digitalization.
STRONG COMMUNICATIONS
Companies must endeavor to remove all roadblocks and provide more streamlined information flow across the organization. Effective communication is an integral part of a well-performing group of people.
Many organizations have already embraced technology by using off the shelf communication and collaboration tools, reinforced by quick training sessions for their employees. People are using video communication more often, and organizations should create a governance structure that will remove all barriers and empower frequent interactions with local decision-making.
TRUST AND TRANSPARENCY
Leaders and employees must understand and support each other like never before. With transparency and positive criticism being championed to bring about the best results. Additionally, it doesn't have to be all about the negative side of the spectrum (i.e. problems/challenges). Positive transparency is equally, if not more, powerful and important. Public recognition of excellence amongst our teams will earn even greater trust and loyalty from employees.
Leaders who seize this mindset, sooner rather than later, will be better prepared to engage employees for the long term, regardless of what is happening in the external environment.
FOCUS ON RESULTS
Let us be honest and clear; change is hard! Ideally, leaders need to champion "ways-of-working" that will help the organization down the road, rather than stagnate and hold it back. Employees must focus on the strategic business priorities of the future.
Instead of worrying about how employees spend their time, how they do their tasks, and the time it takes to get the job done, organizations should be focused more on the results and the value delivered from their work. i.e. the outcomes.
Motivating employees to perform will require modeling and measurement of their outcomes and being clear on those metrics. Companies must set expectations for what drives organizational priorities and goals rather than discrete tasks.
![]()
THE FUTURE
We will see the end of this Coronavirus episode, and many people will desire to get back to their old working habits in their original working environments. Still, many will want to continue working in "the new way", thus creating a beautiful mix of old and new, leveraging the best of both worlds.
We never know what the future will bring. We don't know when and where there will be another crisis. If we wish to succeed, we should always be prepared, knowing how to adapt fast. Learning from previous experiences, and the unique challenges that present themselves, we can be ready to take advantage of the changes that come.
AT IT Labs
For us as a team, all this came more naturally, and we adapted overnight. We could even say, almost instantly. Since day one, we already had our online digital tools and processes set up, working remotely and in mixed teams with our remote colleagues, clients, and partners. With an accumulated wealth of experience, knowledge, skills, the palette of remote managed services we offer, and the range of clients we support, we even helped many of them transform and switch to a fully digital working environment.
We take pride in who we are, what we are about, and how we can adapt to change fast. The fast transformation of our work environment is part of what we are. It's in our bones. We will continue to learn and adapt and teach others to do it as well as we do. So reach out and find out more.
Vladimir Ilievski,
Co-Founder and Managing Partner of IT Labs
There is no need to reinvent the wheel for User Identity Management

 In this new era of digitalisation, one of the most expensive assets in these days is the data. Yet, most of the data breaches are caused by weak authorisation, compromised credentials and poor implementation of access control. For this reason, data protection and security must be priority number one when building a web application.
In this new era of digitalisation, one of the most expensive assets in these days is the data. Yet, most of the data breaches are caused by weak authorisation, compromised credentials and poor implementation of access control. For this reason, data protection and security must be priority number one when building a web application.
One of the core components in any architecture is the user management, in particular authentication and authorisation. The common thing for most applications is the need to know who a user is and does that user have permissions to perform a given action. We refer to this as Identity management.
Do-it-yourself (DIY) development approach, when thinking about identity management and solutions, should not be underestimated, because it is not free and will waste the resources on something that already exists in the market. Efforts to develop this functionality will keep you away from your core business of delivering value to your end customer. You would agree that’s where an organisations efforts and time should ideally be invested in, right?! Nowadays, companies and organisations are looking for ways to outsource user management to a service provider.
The good news is that there are several identity solutions that exist off-the-shelf that focus on precisely the functionality you need.
Choosing the right identity solution is one of the essential things in the process of designing a system. Simple applications might take care of identity management. But, for larger and more complex systems, that’s not a recommended approach.
Choosing the identity and access management provider depends mainly on the specific business needs and requirements.
Identity, by definition, enables the right people to access the right resources, so authentication is the central piece of any software product.
First thing first, What is an IdP? The core element of any identity management solution is the identity provider (IdP). IdP is a centralised place for storing digital user identities. The identity management solutions available are continually increasing. There are a variety of services available, and one must ideally choose wisely to satisfy the business needs on one side, and also make sure its delivered on-time and on-budget.
Azure AD B2C
Azure AD B2C is a delivery manageable Customer Identity & Access Management system (CIAM), providing business-to-customer identity as a service. It’s a cloud-based service, built on top of Azure Active Directory. While Azure Active Directory should be the choice for corporate scenarios to provide SSO service, Azure AD B2C is more suited for public-facing applications, which deals with external users.
Azure AD B2C serves as a direct replacement for managing user identity database and authentication.
Azure AD B2C guarantees security on top of the two standard protocols: OpenID Connect and OAuth 2.0. While also providing seamless integration with your SaaS or on-premises applications, with 99.9% guaranteed availability. But note, for free-tier, no Service Agreement is provided. In case of issues, one can only expect action if a ticket is raised with the Microsoft team, with the response time based on the agreed service plan that you have in place.
Data storage for Azure AD B2C is located in the United States, Europe or the Asia Pacific region.
Setting up the Azure AD B2C can be an easy-going user-friendly experience trough the Azure portal.
Azure AD B2C gives the ability to have the same look and feel as on your application, (e.g. while signing in, signing up, password resetting etc.), all this can be easily achieved through the UI, via user flows or custom policies. The recommended approach here is to define custom user-flows through the Azure portal for either for password resetting or sign—up process.
User flows provide several built-in templates. They also offer the flexibility to use customised HTML and CSS. The customised UI content should be hosted on any publicly available HTTPS endpoint that supports CORS, like AWS S3, CDNS or Azure Blob storage. Now, there is a brand-new feature named Company branding, that enables injecting banner logo, background image and even background colour. Unfortunately, at the moment of writing this article, this is in the state of public review. In any case, any additional customisations can be done with custom JavaScript code.
Multi-Factor Authentication
An additional security step is the possibility to enable multi-factor authentication. By using custom-policies, one can configure password complexity (Note: the default password complexity is set to strong). Any policy requirement can be enforced as needed, together with required error messages that dynamically update as requirements for the password are met (or not).
Azure AD B2C also provides language customisation, either by using the 36 Microsoft supported languages or by using customer’s translations, that are not provided by default.
With Azure AD B2C, we can use either social identity providers like Google, Amazon, Facebook, LinkedIn, Twitter etc., or external identity providers that support standard identity protocols like OAuth 2.0, OpenID Connect, and many more.
For each token issued, administrator access, Azure AD B2C emits audit logs, that are available for seven days. Azure AD B2C provides activity reports for each admin sign-in, along with usage reports for the number of users and number of logins. These can be used to analyse the data and create alerts on specific events.
Pros:
- Secure, using OpenID Connect and OAuth 2.0 protocols
- UI customisation, page look & feel can be customised
- Localisation
- MFA
- 99.9% availability per SLA
- SSO
Cons:
- Not cost-effective
- The data can be accessed only through PowerShell to Azure AD
Identity Server 4
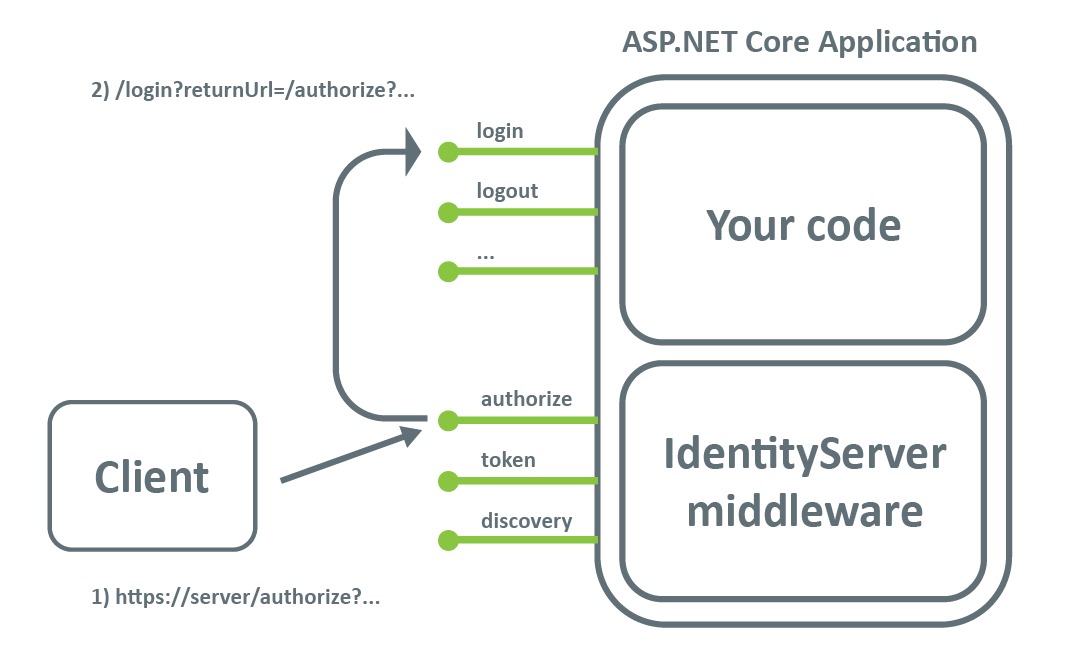
In the list of identity solutions, Identity Server 4 has been the solution that many turn to initially. Identity Server 4 is open-source and free to use. It provides centralised login flow for all applications, either web or mobile.
Identity Server 4 has built-in support for OpenID Connect and OAuth2 protocols. SAML plugin is available in case one needs to support SAML based IdP.
Also, Identity Server 4 has support for external identity providers like Facebook, Azure AD, Google etc.
Identity Server 4 is middleware that can be used to make the authentication an authentication server hosted on a separated instance.
From a scalability perspective, this server does not provide scaling out of the box. However, this can be achieved by putting a load balancer in front of the service.
Despite logging, the emitting events provide more useful information. These events contain data in a structured way.
Direct access to the user identities in the database makes it easier in case of migration activities.
If you would like to try out this solution, there is a handy demo instance of the IdentityServer4 to play with.
The most significant advantage of the IdentityServer4 is that is open-source, so the full code base is available on GitHub, and therefore can be customised as per the needs of a particular use-case.
When talking about customisation, in case of a multi-tenant solution, separate tenant pages can be implemented, and the internal navigation can be achieved by extending the AuthorizeInteractionResponseGenerator class and overriding the ProcessInteractioAsync method.
Since there is no user interface (neither for admin purposes), the IdentityServer4 can only be configured by directly updating the database or making changes in the code itself. Luckily there is a plugin that addresses this. If there is a need for out-of-the-box admin UI, there is a paid admin plugin for precisely this purpose.
Pros:
- Core solution: free of charge
- Good documentation
- Easily extendable
- Configuration as a code
- Since it’s a framework and not IaaS, we can adapt it to our system by writing extending code
Cons:
- Multi-factor authentication is not enabled, it needs 3rd party solution
- Localisation: needs to be developed
- The server’s code template lacks:
- user registration.
- ‘forgot password’ functionality
- MFA or Google Re-Captcha.
Amazon Cognito

Amazon Cognito is a user & identity management cloud service, enabling management of users in one place across multiple devices. It provides the possibility to sync all user information in one place securely and in a straightforward manner, with the ability to scale to hundreds of millions of users.
The two core services provided by Amazon Cognito are User and Identity pools.
User pools act as an Identity provider, storing user information’s and providing authentication information.
The authentication process resides within the Amazon Cognito user pool returned token. As defined in the OpenID Connect open standard, the ID Token contains basic unique information about the identity of the user. The Access token data is in a form that scopes which groups are granted access to a given authorised resource. Refresh token contains information needed to get new Access or ID token.
Amazon Cognito gives the possibility for customisation on multiple levels by using Lambda triggers. Either that’s a custom welcome message after a successful sign-up process or a trigger that will migrate an existing user directory (like AD) to user pools. Also, lambda triggers can be used for the pre-generation of a token, so the claims in the ID token can be modified. Post Authentication triggers might be used to send logs to CloudWatch (e.g. if a user has signed in from a new device).
For strengthening security, multi-factor authentication can be enabled from the UI. The two provided options are, sending an SMS, or using Time-based One-time Password. An everyday use case would be to use Time-based One-time password as a second step while authenticating, and keeping the SMS flow option for “forgot password” functionality.
Also, password policies can be customised based on particular use-cases.
For applications that provide a trial option, where the users can play around with the product/service before purchasing, Amazon Cognito has a perfect solution by using guest login, which enables restricted access.
Pros:
- User directory management and user profiles
- Easy for sign-in and sign-up (resulting in faster development)
- Sign-in using social network providers like Google, Facebook, Apple.
- MFA
- User migration trough AWS Lambda triggers
- SSO
- Supports access management via OAuth 2.0 (making authorisation easier)
Cons:
- Expensive security options
- Less configuration control (compared to other options)
- Not well-organised documentation
IDP COMPARISON TABLE (CLICK TO DOWNLOAD)
Conclusion
These days we rely on identity providers to securely connect our users to technologies and devices. Choosing the right identity solution must be made by taking into consideration the business value and the budget available, but without compromising security or chosen security protocols. Also, keep in mind scalability and SLA of the solution.
Follow the “do not limit a user” approach by choosing a solution that provides various authentication methods layered with a user– friendly experience. The chosen IdP should protect the user identities without making it challenging or painful for the end user.
Aleksandra Gjinovska,
Technical Lead at IT Labs

How Can You Get More Effective with DevOps?
The promise of DevOps is to provide a basis of collaboration between organisations and IT that produces superior customer value..

One of the most recent changes in operations and delivery, surrounding IT, has been a new awareness of how critical support for ongoing operations is, and how the value chain should continue to improve for the various businesses that IT supports. For large and fair-sized corporations, where the core business is anything but IT, popular opinion suggests that IT is perceived to consume company profits—essentially, a cost centre. This has led to a high level of scrutiny in recent years, especially with tighter budgets and shrinking profits. The need for strict control of expenditures in IT development and support to keep the network running smoothly is a growing concern for the CIO and CFO. In effect, this has turned into a struggle between the need to maintain tight operations with minimum expenditures and resources while attempting to maximise support and continuing to produce results.
The industry has seen this trend growing over the past few years, and the introduction of lean and agile methodologies has enabled management teams within these organisations to understand how to get more value when spending less. Gone are the days of an overabundance of IT jobs, where IT departments are populated with more personnel than needed to anticipate possible unforeseen emergencies. Times have changed. Today, IT is leaner and forced to be more efficient through better software, written specifically for enterprises, with enhanced development tools and superior support structures.
Introducing DevOps
Information services teams within organisations have certainly matured over the past fifteen years. The bar has indeed been raised from even just a few years ago. IT departments have arrived at a point where the work they do is primarily for organisational self-consumption and self-sustainability.
Organisations are getting smarter, workplaces are getting more secure, and technologies are becoming more sophisticated with every six-month cycle. The concept of accomplishing more with less is driving organisations towards better, more strategic management of resources and people, being more efficient, and generating high business value while maximising profits.
DevOps, or development operations, is a term used to define a specialised set of resources and people who supply de¬sired processes of efficiency and agility. This is designed to make organisations and their IT departments smarter and more productive while reducing defects. DevOps assists in generating higher business value for the organisation while simultaneously lessening costs. This specialised grouping of re¬sources and people wasn’t conceived yesterday—instead, this has always existed within the IT realm of application management and support.
So, What Has Changed?
DevOps is simply the result of technology’s continual quest to find something new and refreshing to refer to year after year. Certainly, DevOps sounds trendy and exciting. On a serious note, DevOps is gaining a lot of ground within structured IT management and operations circles. DevOps is not a fad; it is here to stay. Although the terminology might change over the years, the underlying integrity benefits will not. The prime purpose of creating a structure around DevOps is quintessential. Organisations don’t just see development costs as a benchmark by which to indicate the product’s quality, value, and profitability. Now, organisations take the perspective that cost saved is of more value when strategically invested toward the betterment of technologies. This results in operational gains, which promote success in business and help attain more customers while successfully moving forward.
DevOps assists in generating higher business value for the organisation while simultaneously lessening costs.
DevOps provides a more cooperative, productive partnership between development and operations teams, through fostering improved communications and efficiency during critical planning and development stages. Thus reducing or eliminating potential costs and problems down the road commonly linked with unforeseen changes. Typically, most personnel involved with DevOps, apply Agile and enterprise principles that help result in the successful deployment of DevOps processes.
DevOps focuses on typical key product development issues, such as testing and delivery, while stressing the business value of processes beyond release management, such as maintenance updates. This desired outcome is accomplished through the adop¬tion of iterative methods and incremental build models of development. Each milestone is carefully evaluated by the product development teams, analysed, and modified as needed. Only then does the team continue with the build and, ultimately, deployment. This continuous integration might seem tedious, but these frequent checks and balances will make the entire deployment process smoother, and more effective in the long run, as the need for backtracking and correcting mistakes is minimised.
The iterative approach for DevOps is in contrast with other more traditional methods. It emphasises the importance of strategic partnering of development team members. Thus, promoting communication among crucial personnel, inviting every team members critical input to be considered, thus streamlining the development process even further. Communication and feedback are viewed as essentials to reducing production costs, delivering business value, IT stability, and efficiency. This path to more effective communication requires an excellent communication infrastructure in place to ensure that nothing gets missed and that no team member is out of the loop. All these activities can appear to be daunting, especially with geographically distributed teams that include a diverse number of resources. That is where the value of change management and release management is demonstrated. All team members must be aware of the expectations of them, and their full participation is agreed-upon. Some typical communication challenges to be managed can include:
- “I didn’t know we were supposed to do that.”
- “My team doesn’t have the expertise, time, or resources to complete this milestone.”
- “Team A didn’t communicate to Team B what their requirements were.”
Any potential problems can be avoided by carefully managing and facilitating communication among team members, so there are no lingering surprises to be uncovered.
Going Forward with DevOps
Ultimately, the broad definition of DevOps is simply a method to foster effective communications and collaboration amongst development and operations team members. It’s about:
- delivering more with less
- working smarter, not harder
- getting things done quicker
The rise of social media and cloud computing necessitates the rapid, effective deployment of new IT systems. It addresses the critical need for fewer maintenance releases while recognising the unacceptability of the word ‘downtime’.
IT developers know the importance of business value, and DevOps helps them accomplish that by delivering faster product solutions, eliminating problems, and introducing added value through reduced costs and network and system stability. In addition to fostering communication and trust between departments, DevOps team members also should learn some new skills—all of which has a positive trickle-down effect and ultimately leaves a significant, positive impact on the organization.
Manoj Khanna
Chief Methodologist at IT Labs