
Re:Imagine Session – From Idea to MVP, From MVP to Product




Is it sufficient to start with idea development if it “looks” that the idea will bring business value? Many would say yes, but the truth is that proper planning must be executed to assess the validity of an idea, which will in turn show potential business or maybe other value to the company engaged in idea or product development.
In the video below, you will see the whole Re:Imagine session from 19.10.2022, in which IT Labs’ Chief Innovation Officer, Blagoj Kjupev, went through all the steps in the idea development process – focusing on listing the basic assessment steps required to have a justification if the idea should be developed as a prototype or MVP, and when the MVP is developed – what is required to have a product that should live and generate sufficient revenue to cover initial investment and running costs.
This is just one of our Re:Imagine sessions, at which we have experts from various fields and industries, using the sessions as a platform to share their experiences and who dive deep into subjects!
Topics covered:
- Idea development
- Preparation/planning
- Final Preparation Steps
- Execute Implementation

Re:Imagine Session: How to Create a Winning Team with Blagoj Kjupev


We started our Re:Imagine sessions with one goal in mind – to give experts, leaders, and people with ideas the platform to share their know-how, experience, and findings – and maybe even find like-minded people to join them on their journey! The sessions are powered by IT Labs – a company with a vision to enable clients to compete through tech while providing a platform for bright heads to grow and develop into top-notch tech professionals.
And here, for you, we got the first one! To share with everyone who couldn’t make it to the session, but would still like to hear from IT Labs’ CIO, Blagoj Kjupev!
This session will give an excellent overview of the required steps to set and monitor a team that will bring success to any project/start-up. Based on Blagoj’s many years of experience, he’ll discuss the possible scenarios from real-life scenarios and how to overcome the most common problems. He’ll also give a great overview of the whole process – from the idea of putting together a team all the way to project execution, all with examples of different team setups.
Topics covered:
- What is a winning team?
- Project team planning
- Team overture
- Team setup samples
- The six thinking roles/models
- The “surgeon” approach

Choosing a Tool to Practice End-to-end Automation
Choosing a Tool to Practice End-to-end Automation

Why do we need automation test sites?
As many automation frameworks/tools have risen in the last few years, we have more options to choose from when we evaluate which tool is best suited to a given project, and of course, practice makes perfect.
Practice requires environments prepared for that purpose, and that implies choosing a demo web app that allows us to add data and test workflows without affecting real users or any other collateral effect, playing the role of “Application Under Test”. This demo web app also supports us when preparing a demo or learning a new framework/tool to automate tests or, while assessing a new automation framework to help us decide which is the best one for a given project.
In this opportunity, we are looking for that project to use as a model (scenarios to test) for our whole QA team, that allows us to build automation suites using different frameworks, starting with Playwright and Cypress. The outcome of this exercise will be used as our IT Labs automation playground. Ideally, this project is open-source and allows us to build an immutable environment, working locally or deploying it in our in-company environments and, if needed, to add improvements to source code in order to achieve a good selectors strategy and add features to increase our testing coverage.
What are we looking for in automation test sites?
Usually, we look for a few elements (commonly found in all web apps) as:
• Login/Authentication: to test features which require to be logged as a valid user (right permissions applied) vs public features (available with no authentication needed).
• Roles/Authorization: testing features under different profiles and authorization levels (right permissions management). For example: actions that can be performed as admin users but not allowed to regular users.
• Forms: Save information and verify that information has been saved accurately.
• Modals/Popups: to check success/error messages, alerts, or modal forms to save information.
• Upload content: upload content and verify they have uploaded correctly and are available to consult/download such as files and images.
• Download content: testing that we can download content generated by web app, such as invoices, reports and so forth.
• Mouseover/Tooltips: to check help messages or error messages.
• Tables/Grids: to test/search information as products listings, employees, courses and so forth, organized in table or grid formats.
• Localization: to test dates and currencies formatting, time zones and languages which depend on countries/region. Also, features that should be available in certain countries/regions.
• API: we can test features through REST request, as they are faster than UI and, also, we can automate these requests.
• Selector Strategy: when we automate user interface tests, the first thing is to “find” elements in our web app, and then, we chain actions to those elements; this is how we interact with the web app. A selector strategy is the way we “find” and interact with all elements. So, this web app also will allow us to establish a good selectors strategy. Most elements have proper ids and names (which represent the data as username, password, personalID, address, save and submit, instead of IDs randomly generated), class names, attribute data-test or data-test-id (usually do not change over time).
• Workflows (e2e use cases): a workflow is a pattern of activity enabled by the systematic organization of resources into processes that transform materials, provide services, or process information. We look for workflows because we do not test isolated components; we test workflows just like our users would. Some examples are banking features (deposits, withdrawals, transfers, create accounts), e-commerce (add products to carts, accounts creation, set addresses and payment methods), human resources (creating employees, requesting PTO, generating reports), and so forth.
• Easy to manage (install, run, stop and restart) as our purpose is to work primarily in an automation suite and not get distracted in other kind of issues.
• Easy to reset (reverting back to initial state) in order to get predictable test outcome consistently (always).
• Easy to maintain in case we want to add more challenging features to be tested.
Automation test sites assessment
We compared elements and features to determine the complexity of workflows and the selector strategy we can use in a few demo sites created for testing purposes:
Ecommerce: SauceDemo, Juice Shop and Automation Exercise
Banking: XYZ Bank, Cypress Real World App and Parabank
Human Resources: OrangeHRM
Flights and hotels booking: PHP Travel
| SauceDemo | XYZ bank | Automation exercise | Parabank | Orange HRM | Juici Shop | PHP Travels | Cypress Real World App | |
| Login/Authentication | Yes | Yes | Yes | Yes | Yes | Yes | ||
| Roles/Authorization | Yes | Yes | Yes | Yes | Yes | |||
| Forms (save & check) | Yes | Yes | Yes | Yes | Yes | Yes | Yes | |
| Modals/Popups | Alerts | Yes | Yes | Yes | Yes | |||
| Upload content (files, images) | Yes | Yes | ||||||
| Download content (files) | Yes | Yes | ||||||
| Mouseover/Tooltips | Tooltip | Yes | Yes | |||||
| Tables/Grids | Grids | Yes | Yes | Yes | Yes | Grids | Grids | |
| Localization (other than English) | Yes | |||||||
| Accessibility | ||||||||
| API | yes | Yes | ||||||
| Good selector strategy | Yes | Yes | ||||||
| Good workflow | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
With this assessment phase, we arrived to the final two candidates – Orange HRM and Juice Shop. After further assessment, we chose Juice Shop because it has almost all the features except download files (files are open in another tab or window).
IT Labs Automation Playground
An automation playground is a plus when we want to assess different frameworks (writing and running the same test in different frameworks), because it allows us to focus our efforts on the technical capabilities and pros/cons of the tool/framework under assessment with complete impartiality as our Application Under Test (AUT) will be the same.
We assess in an automation framework features different than the ones we look for in an AUT, such as:
- Support for multiple browsers.
- Support for interaction with elements in the web app, reading attributes as so on described before as testing strategy.
- Support for asynchronous.
- Multiwindow support.
- Download/upload of content.
- Visual testing.
- Reporting.
- Integration with different CI/CD tools.
- Error handling.
- Retrying (when fails).
- Mocks.
- Assertions.
- Support for Page Object Model or other patterns.
- Organizing suites.
- Parallelism.
- Parametrization.
- Debugging.
As Juice Shop is an open-source project, you can fork it, as we did with our own automation-playground repository and add new features (such as download files, that it is missing in the original project right now). In that way, our automation playground will not be affected if the project is not available online anymore, and we will not affect any real user or any other side effect.
We will use this to compare different automation frameworks as we would use the same site to do the test (with most of the features we want in automation test sites).
We can test:
- Login with email and password; and using a Google account as well.
- A role for regular users and a role for deluxe membership where you will get discounts and delivery for free.
- Upload pictures as photo wall or setting user profile.
- Localization as there is a lot of languages available.
- Different workflows in a shopping cart such adding products, setting payment details, adding addresses, add reviews to products, send a complaint, a chat for customer support, order history and recycling box.
Modals and popups, forms, tooltips, tables, grids with IDs, aria-label and placeholders are available to test interactions. We can implement a selector strategy based on IDs, names, css classes, text, links, and attributes.
Juice Shop is a project created for security testing purposes, so, we can implement security and API testing as well. A good balance to practice automation testing. You can learn more about the challenges here.
Our discover in our playground
AS we mentioned before, there are many frameworks to automate tests and we need to choose the one which fits best for our project/product.
After running a few basic tests in Playwright and Cypress, we can verify the support in following items for each framework:
| Features | Cypress | Playwright |
| Support for multiple browsers | Yes | Yes |
| Support for interaction with elements in the web app, reading attributes and so on (described before as testing strategy) | Yes | Yes |
| Support for asynchronous | Automatic | Yes |
| Multi-window/multi-tab support | Yes | |
| Download/upload of content | Yes | Yes |
| Visual testing | Yes | Yes |
| Reporting | Yes | Yes |
| Integration with different CI/CD tools | Yes | Yes |
| Error handling | Yes | Yes |
| Retrying (when fails) | Yes | Yes |
| Mocks | Yes | Yes |
| Assertions | Yes | Yes |
| Support for Page Object Model or another pattern | Yes | Yes |
| Organizing suites | Yes | Yes |
| Parallelism | Yes | Yes |
| Parametrization | Yes | Yes |
| Debugging | Yes | Yes |
| API testing | Yes | Yes |
Playwright
Playwright can be installed with just 1 command:

Playwright Code Generator
We can start recording a test with 1 command as well (we will bring more about it in future articles):
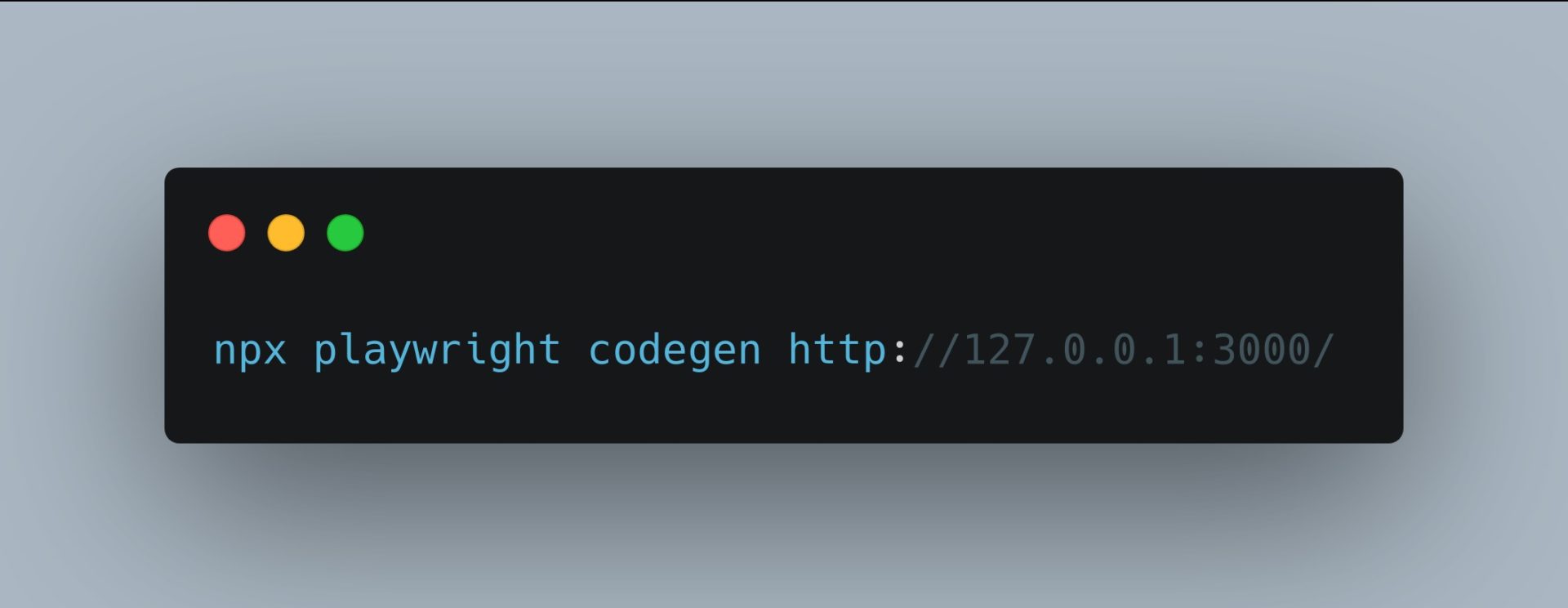
We can record tests, export them in several languages to include them in our suites.
Selectors Strategy
This is an example of multiple selectors that Playwright allows.
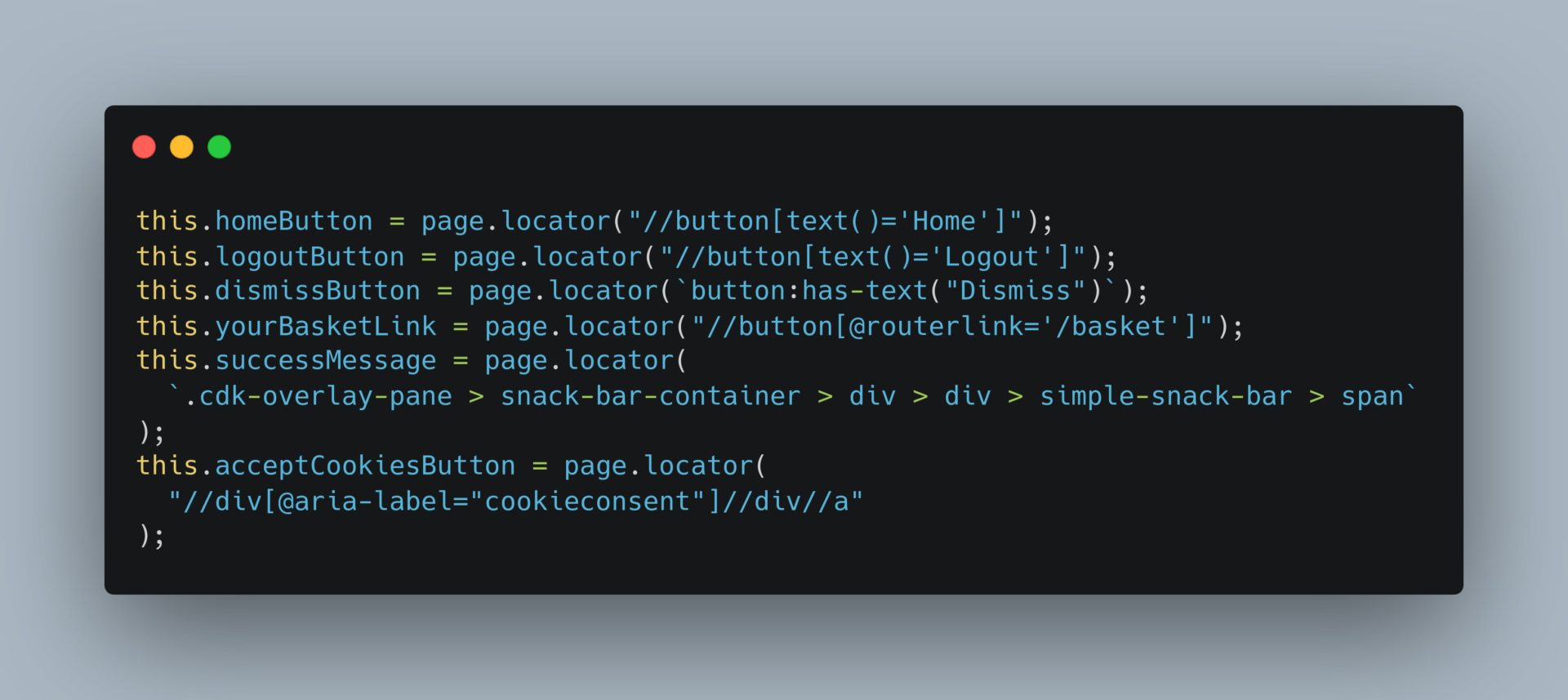
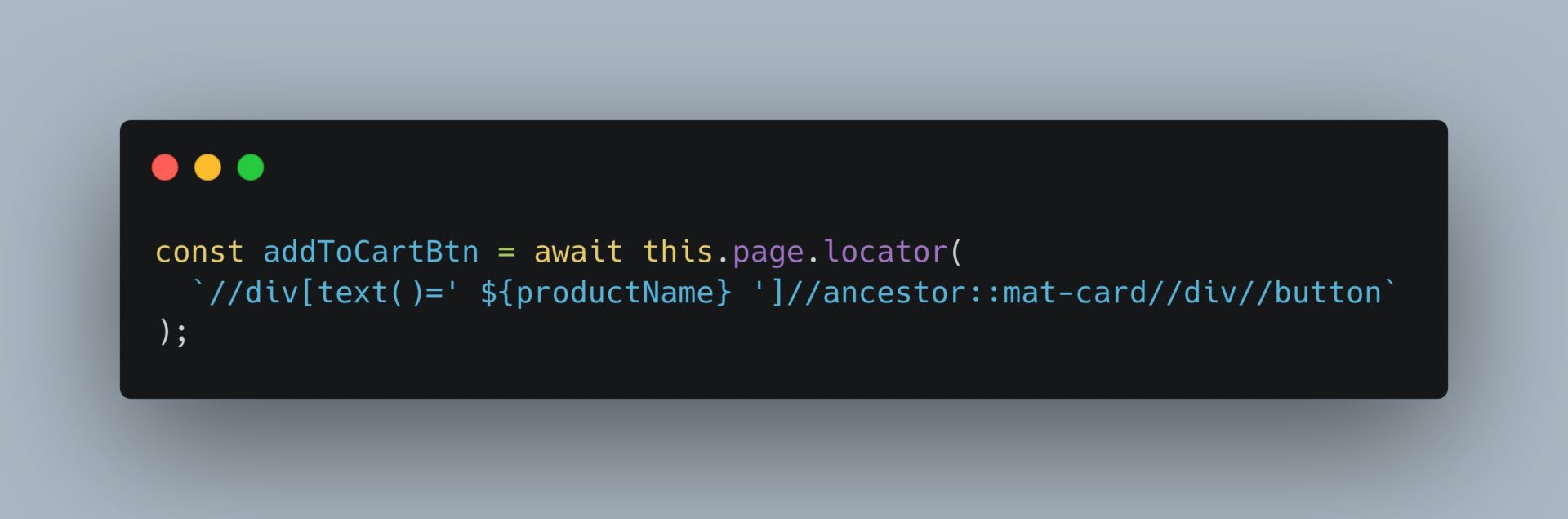
We can also build our selectors which depend on data or generated classes:
Page Object Model in Playwright
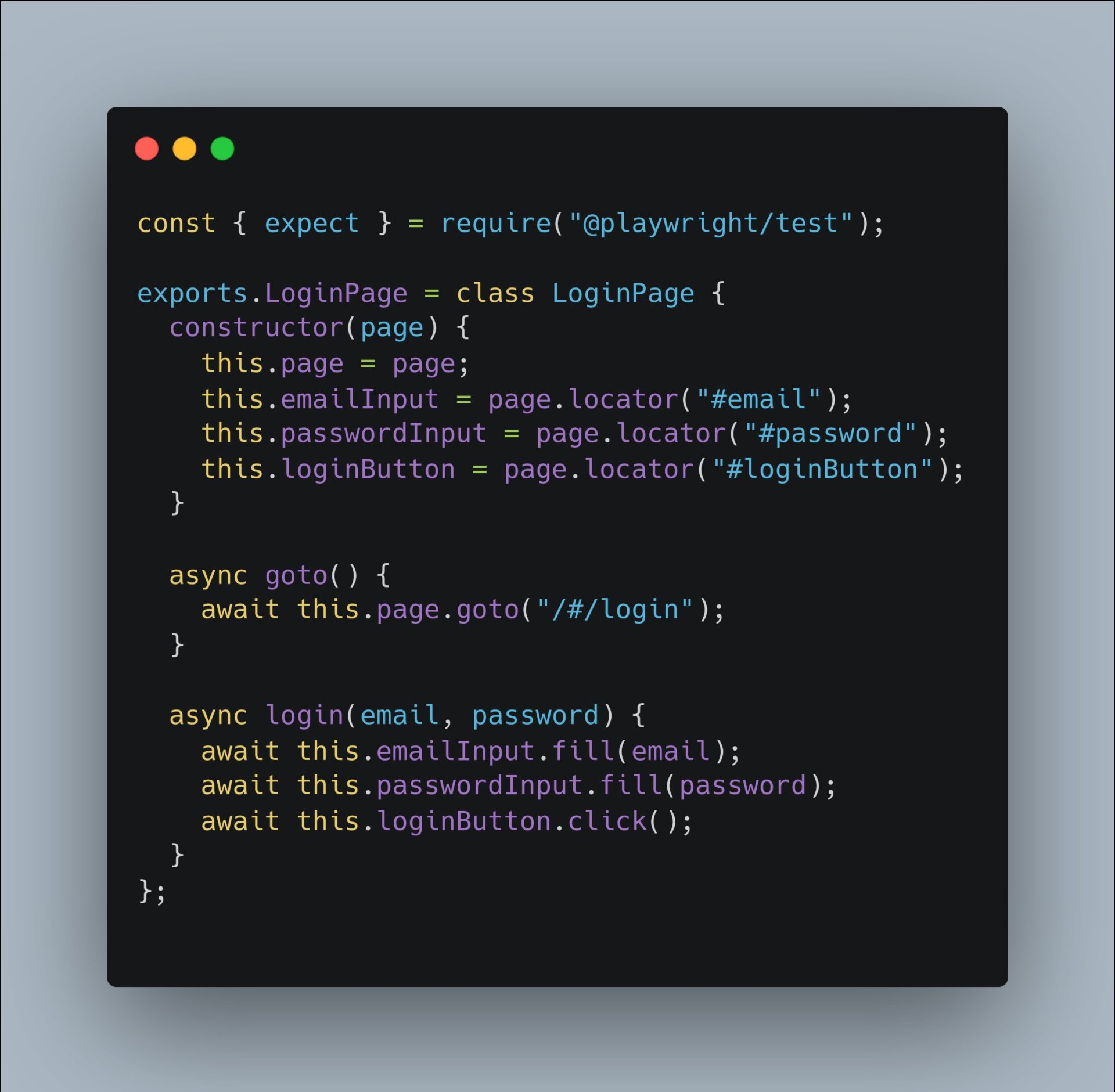
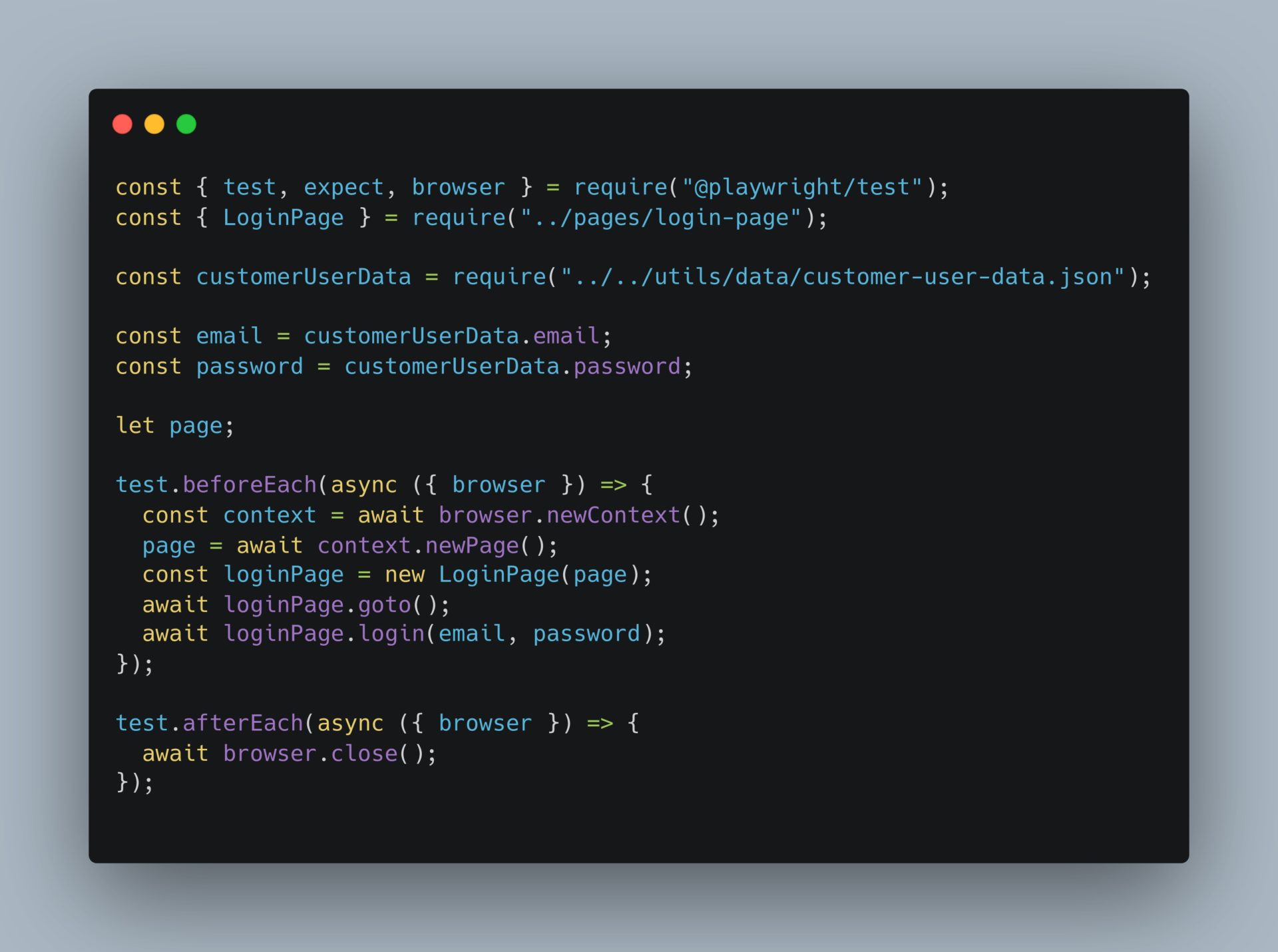
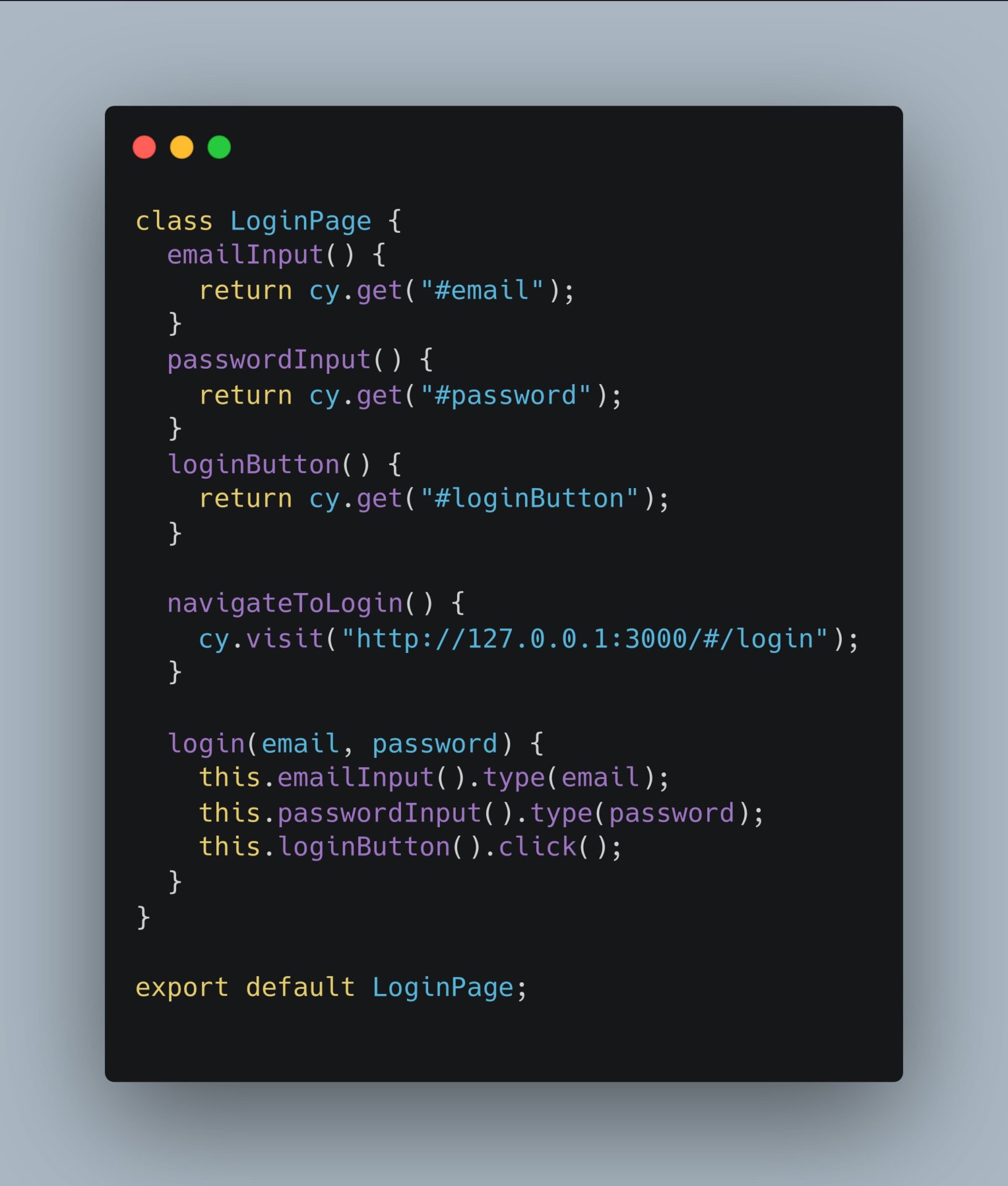
Let’s see an example of login:
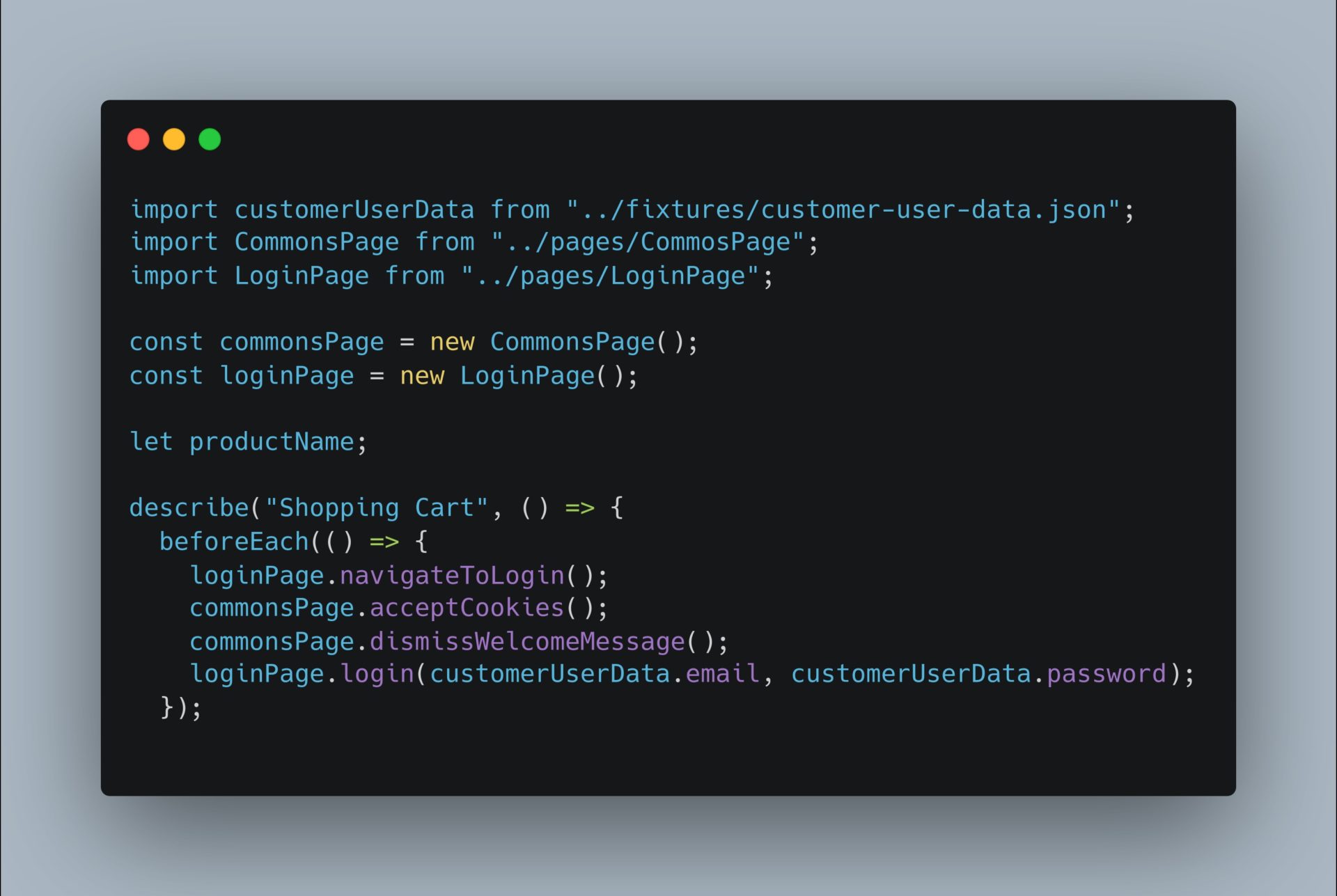
Following the page object model (POM) we have a page login-page.js and the spec file ShoppingCart.test.js where we are using the login page:
Login-page.js
ShoppingCart.test.js
Cypress
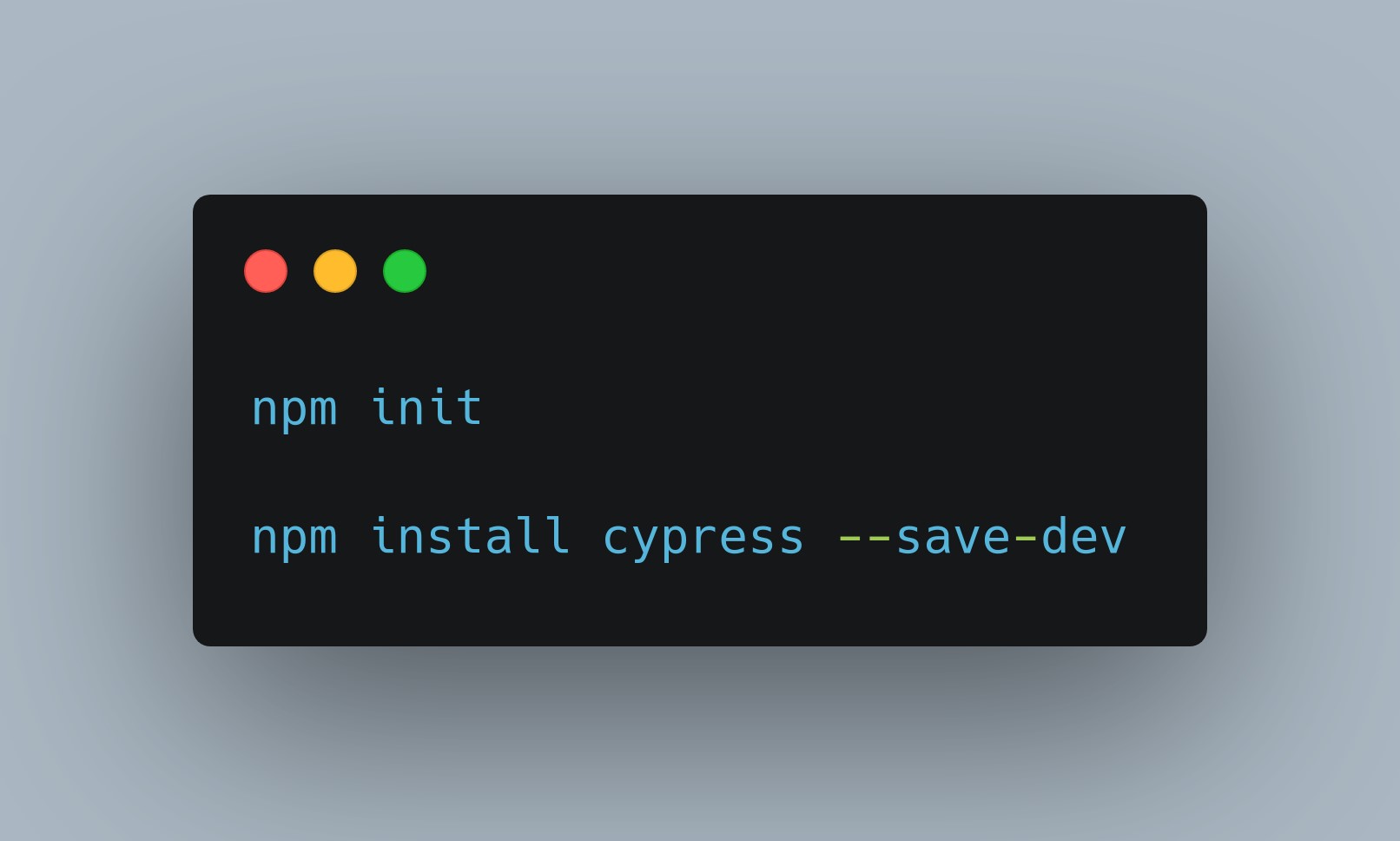
Cypress can also be installed in a few commands:
It has a user interface where you can configure it, run the tests and inspect elements. You can activate it with the command:

This is how the user interface looks like:
And this is how a running test looks like:
Selectors Strategy
This is an example of multiple selectors that Cypress allows. We can also build our selectors which depend on data or generated classes:
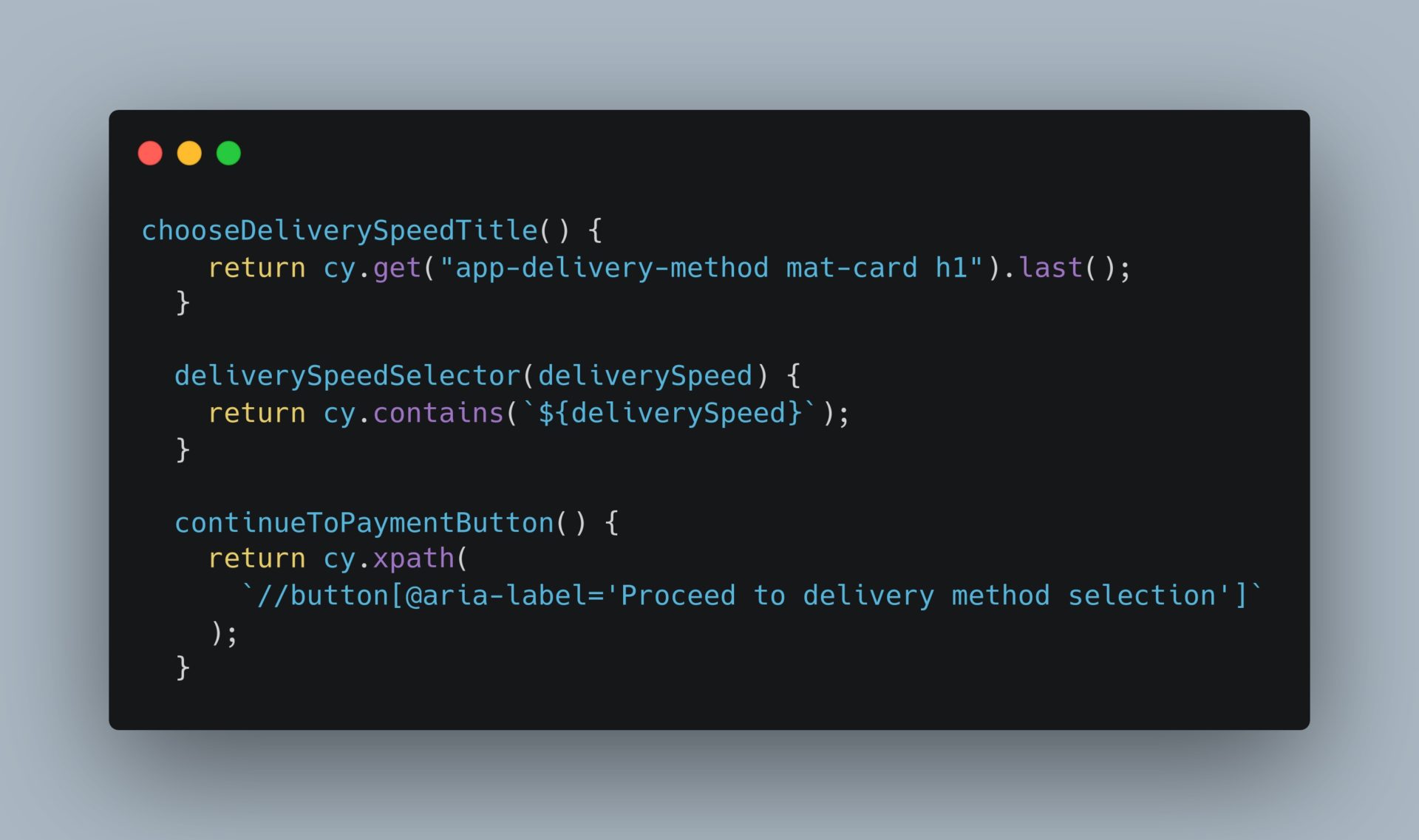
Cypress Studio (experimental)
Page Object Model in Cypress
Let’s see the same example we saw above: login. We have a page LoginPage.js and the spec file shopping_cart.cy.js where we are using the login page.
LoginPage.js
shopping_cart.cy.js
Speed of Tests
It’s important to mention that both frameworks work without Selenium and Webdriver, they tend to be faster. Cypress runs the tests in 25secs, and Playwright runs the same in 15secs, both in headless mode.
You can check the suites here: Playwright and Cypress.
Conclusion
There are many websites out there (both online and available to be installed locally -open-source projects-) and choosing a tool to learn and practice, or evaluate an automation tool, will be based on your purpose and need.
It is also worthwhile when we want to compare several testing frameworks and create test suites using different tools and approaches but the same website. In that way we can focus our efforts on the technical capabilities and advantages of the tool/framework under assessment with complete impartiality.
You need to make sure that the playground project you choose allows you to establish a good locator strategy and a good workflow to be tested (not only interacting with web elements) because from a real-world user’s perspective we do not test components isolated.
We can use Juice Shop as our playground web app to evaluate different test automation frameworks and to establish our test strategy with the advantage of having an immutable environment, easy to manage and reset guaranteeing consistent outcomes over time (same results in all testing execution cycles).
The final takeaway is that you need to choose the automation framework that fits best for your project, and this will be determined by the kind of project and features and complexity you need to test.
Both Playwright and Cypress are easy to install, have wide support from communities, and have all that we usually look for in automation frameworks. They are fast because they are not based on Selenium and Webdriver but still powerful in debugging and integration with several CI/CD tools. Definitely good choices for bringing automation regression into our projects/products.

Author:
Maria Aguilera
Senior Quality Assurance Engineer in IT Labs

State Management and You
State Management and You


Milan Saric – Technical Lead
In this article we will explore the history of state management, as well as how and when they should be used. It’s my firm belief that proper state management architecture in modern front-end projects is basically 90% of the work, afterwards it’s just simple controllers and CSS. You will find the steps and a flowchart bellow detailing when to use what type of state management, as well as various alternatives to industry standard state managers for all 3 major front-end frameworks.
History of state management
Since we had complex JS front-end apps, we had a problem, how do we cache/reuse/store data received from the backend? Thus a need for state management was born. The first solution still used today is web storage, colloquially known as Local Storage; it’s a segmented in-browser storage solution of key-value pairs. However, it had a significant downside – a 10MB limit almost across the board.
Thus a need for more complex storage emerged, and in the early 2010s, a new competitor emerged championed by Apple, Web SQL Database. Yet, it was quickly disposed of in favor of something that wasn’t SQL-related but rather JSON based. That standard was first released in 2015 and is now known as Indexed DB.
With new frameworks (especially React) came the need for a new type of state management, and consequently, session storage gained traction. It was a simple in-browser storage option that lives as long as the application is alive and dies with the browser garbage collection once you close the tab. Naturally, almost simultaneously, a persistent version of this was created – with the most famous of the so-called stores being Redux.
Below, you’ll find various ways to store app data, as well as various ways to use said storage well.

Web Storage
- It’s an API supported by every browser out there.
- It uses built-in storage that allows you to store usually up to 10MB of key-value pairs.
- It’s handy when storing a language setting or other bits of data. However, if you persist a complex store, it will most likely go into local storage.
Indexed DB
- This API is an in-browser DB that uses JSON and is indexed by a unique key. While relatively new (since 2015), it’s considered very old and archaic, despite coming out in the same year as the famous ES6.
- It’s helpful if you need to store and process massive data sets on the front end. For instance, if you’re creating an Excel clone that does all the processing on the front end, you might want to use Indexed DB.
- While the usefulness of Indexed DB is often very niche, it can be the perfect solution
Session Storage
- The need for this arose as single-page apps came to the fore, especially when components that needed to talk to each other were more integrated.
- How do you update an item in a “cart” component from a very nested component, “add to cart” that’s not a direct child of the “cart” component? Well, you update the state/context/redux/whatever your project uses.
- In the background, it’s just an event listener for the thing you registered in the related components.
- It’s used to store larger objects or when you need to manipulate data on the front end manually. Most frameworks allow built-in libraries that do this. However, those libraries can’t be persisted between sessions.
Persistent Storage
- Persisting session storage is possible if a state management library such as Redux is used, and in almost every case, the persisted copy is stored in Web Storage.
- When using a library such as Redux, it’s important to structure it well like you would a DB on the backend because having wrong “schemas”, or wrong actions/listeners will always cause unclean spaghetti code and many, many rerenders in React. (Ask me how I know).
- This is mainly used when there’s a need for a complex “store” that needs to persist between sessions. Think of a guest cart object in a webshop or anything else as something that can be updated between sessions before going to the backend.
Apollo GraphQL Client
Apollo has a built-in “store” for caching GraphQL calls that functions very similarly to Redux and other alternatives. It’s a very robust solution if you’re using GraphQL, and I recommend it over any other solution if using GraphQL.
It can also be persisted and then stored in Web Storage, however, it doesn’t need to be persisted to work.
When you’re using GraphQL, you probably want to cache the data from the backend to allow a smoother user experience, and you probably want to use the built-in method for that through Apollo Client.
Why Use It
Almost every front-end application needs some form of state management. If it’s a simple local storage store of a token/browser settings or a very complex Redux store, it’s essential to know when to use what, as not every tool is a hammer in state management.
If you’re building a complete PWA-compliant application that has complex interactions between components and needs to work well in the offline mode, I recommend using a complex Redux or similar store.
However, if you’re building a simple social network like a PWA application, you probably don’t need a complex store. Something like just Web Storage and good context design is perhaps good enough.
However, if you’re building a very complex application with a lot of data processing in the front-end or something that will store loads of blockchain data in the browser, you probably need Indexed DB.
And if you’re building a genuinely complex monolithic front-end application, you might need all of them in some combination. It’s very project dependent, and no single solution works for everyone.
Redux vs. Everything Else
Redux is still the industry standard for state management in React, followed very closely by NgRx for Angular and VueX for Vue. However, all of these libraries follow the same basic principles and share the same cons. They are slow, monolithic, and are used by default even if the project doesn’t require them.
As you’re about to see in the chart below, no state manager ticks all the boxes, and it’s critical to realize what you need for your particular application and if you want to go with the industry standard or try any of the numerous alternatives.

React
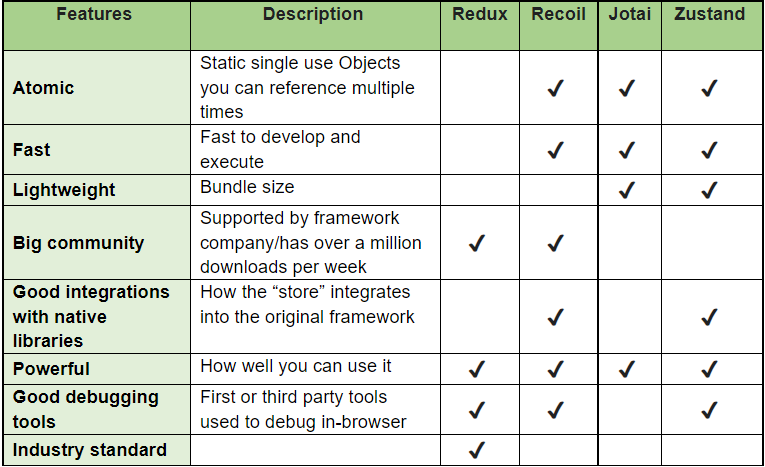
If you need a state manager for React, try any of the alternatives mentioned – I’m sure some of them will fit your needs better than the good old Redux. I recommend Zustand since it ticks most boxes and is both tiny (~1kb) and powerful.
Angular
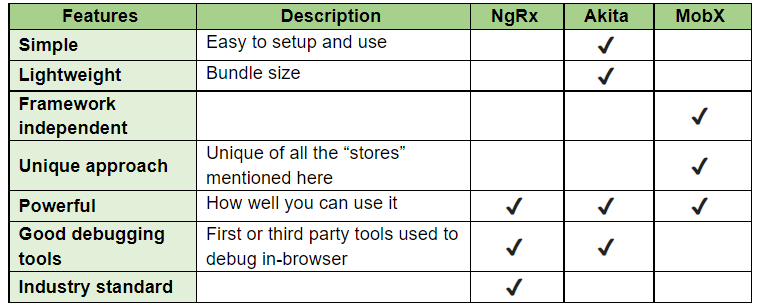
Angular has less–popular state managers, but it’s still worth it to take a look at the alternatives to see if they might fit your project better.
Note about the charts
The charts for React and Angular are different because the feature set depends on the frameworks and stores, and there’s a large variety of them.
Note about Vue
Vue has the de facto only state manager in the VueX, and while VueX fits the Vue paradigm quite well, nothing stops you from using MobX, for instance, especially if you have a more complex state that can accommodate two or more similar applications written in anything from Vue to Angular to React and beyond.
Flowchart
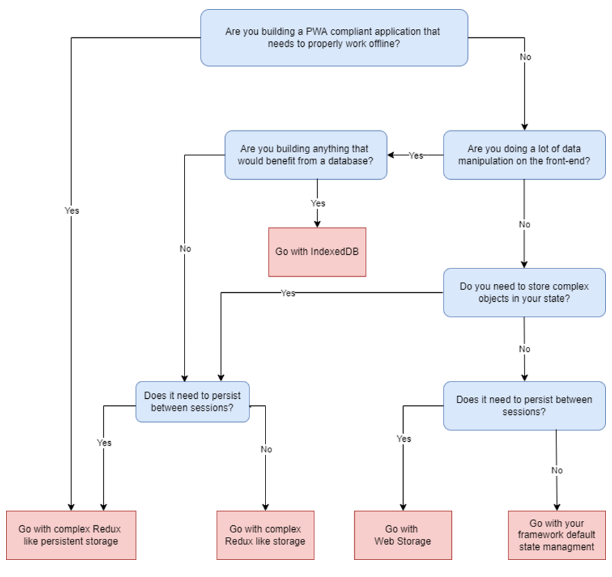
Storage State Management Decision Flowchart
Conclusion
When designing a new front-end application, it’s imperative that you develop the state management system properly, especially in React. In my opinion, the design of the state management system is 90% of the front-end work. The rest is simple logic and CSS.
More often than not, you’ll be using a combination of these state management tools, and it’s vital to properly know what’s stored in Redux, what’s stored in context, and what’s stored in the in-component store. This will avoid many unnecessary rerenders, and it will reduce the complexity of the entire app significantly, thus saving countless hours.
As we’ve seen in the flowchart, every state manager has its purpose, and we will almost always use a combination of a few managers in our app. And no matter what UI framework you use, I’d highly suggest you try one of the alternatives. Especially Zustand if you’re using React. Huge applications with millions of users require complex industry standard “stores”, but the application we write every day will benefit from something more “niche” that requires less resources but still produces the same results.
The important thing to understand on all these is that sometimes we don’t even need a complex state manager such as Redux, and that often we can use a simpler method to speed up the development process and still arrive at the same destination.

Author
Milan Saric – Technical Lead

From Deep Love for Tech to Rediscovering his Mojo: The Story of Milos Antic
From Deep Love for Tech to Rediscovering his Mojo: The Story of Milos Antic

Technical Lead
Anyone who’s ever done something in the tech world will know that the way up is impossible to walk unless you have that deep, burning love for technology and software. Just like our Milos Antic has – from how he made his first steps in the tech world, all the way to how he rediscovered his mojo and passion with IT Labs!
What keeps you motivated at work?
Mostly colleagues, environment, energy that I feel once I sit down in front of the computer. Of course, the project is part of it as well, but for me it’s the most important colleagues.
What drives you? What feeds that flame for learning and creating?
Before everything, my family, the fact that I will become a father and that I need to create a stable future for my family. After that, success, knowledge that I’m getting every day on the project and from my team, the performance that we are making and result of our work.
What annoys you at your job? Something you can’t stand.
When somebody is late on meetings, or when the team it’s not cooperating on a good level, but that’s not the case in the IT Labs.
What advice would you offer to young developers when it comes to loving what they do forever?
Don’t try to be the developer if you don’t love computers and software, otherwise you will start to hate it with the first coding problems. Love is something that keeps you motivated and focused at this job, if you want to join in IT industry just because it’s well paid, you will not much succeed and you will hate it soon or later. People are trying to convince you that you can get a $1000 job with 3-6 months courses, that is impossible, you can get some knowledge but if you want to be a successful developer you need to learn really hard for 12+ hours per day for at least 8-12 months.
What do you like about the working atmosphere at IT Labs?
People, people, people! We have an amazing team, atmosphere, communication so we always have time for fun, random stories, so it is enjoyable and relaxing to be in the team with all professionals from IT Labs. Every problem that we have as a team is extremely easy to solve just because we are solving it together. We have knowledge sessions where we share our knowledge and new founding, this increases your skills incredibly fast. We are working so much with the interns and juniors, I love to see how they progress every day and their transformation into juniors/mediors and impact that they are making after few months is amazing and enjoyable.

The Books That Helped Shape the Tech Leaders of Today – Part 3
The Books That Helped Shape the Tech Leaders of Today – Part 3
Talent and hard work are crucial for making it in the tech world, but for leadership in the industry, one must be ready to not just adapt to the circumstances, but also take a long hard look at oneself.
Leadership is about a lot more than just having the tech expertise and a sharp eye for detail, methods, and processes – it’s about creating connections and finding “gaps” through which you can inspire your team and drive progress and change.
In Part 1 and Part 2 of this series, I focused on books that were more about the organizational side of things, the structure, but in this one, I’m focusing more on shelling out the gems that are the true drivers of change – the change that comes from within ourselves.
Enjoy 🙂

Trillion Dollar Coach: The Leadership Playbook of Silicon Valley's Bill Campbell by Eric Schmidt & Jonathan Rosenberg
Description: A book that’s all about Bill Campbell, his life, his mindset, his leadership style – all combined nicely to provide the perfect balance between a personal story, and an educational masterpiece.
How it can help aspiring tech leaders: Sometimes just shooting out instructions and methods doesn’t work, as they lack context. The personal aspects in this book can help you understand better why his way worked, learn about the methods, and the most important thing of all – decide if this is something you might be interested in.

Trillion Dollar Coach: The Leadership Playbook of Silicon Valley's Bill Campbell by Eric Schmidt & Jonathan Rosenberg
Description: A book that’s all about Bill Campbell, his life, his mindset, his leadership style – all combined nicely to provide the perfect balance between a personal story, and an educational masterpiece.
How it can help aspiring tech leaders: Sometimes just shooting out instructions and methods doesn’t work, as they lack context. The personal aspects in this book can help you understand better why his way worked, learn about the methods, and the most important thing of all – decide if this is something you might be interested in.

The 4-Hour Work Week: Escape the 9-5, Live Anywhere and Join the New Rich by Timothy Ferriss
Description: What can effectively be described as a guidebook for people who want to live their desired life, ‘The 4-Hour Work Week’ does an excellent job of putting things into perspective for people, helping them find that way, while empowering them to stick to their plans.
How it can help aspiring tech leaders: Lifestyles, ideas, urges – these all are important to development and growth, but the basis for all of them to bear fruit is to learn how to think for yourself and break free from the norm. Tech leaders are disruptors, after all.
The 4-Hour Work Week: Escape the 9-5, Live Anywhere and Join the New Rich by Timothy Ferriss
Description: What can effectively be described as a guidebook for people who want to live their desired life, ‘The 4-Hour Work Week’ does an excellent job of putting things into perspective for people, helping them find that way, while empowering them to stick to their plans.
How it can help aspiring tech leaders: Lifestyles, ideas, urges – these all are important to development and growth, but the basis for all of them to bear fruit is to learn how to think for yourself and break free from the norm. Tech leaders are disruptors, after all.
The Art of the Start: The Time-Tested, Battle-Hardened Guide for Anyone Starting Anything by Guy Kawasaki
Description: Science is behind all the good moves leaders do, but the art of it is the connective tissue that brings it all to life, giving it meaning and purpose. In this book, you have an end-to-end guide on how you need to approach and execute various tasks – from start to completion.
How it can help aspiring tech leaders: Grand ideas are the backbone of anything meaningful that happens in the world, but turning that idea into something tangible and moving? This book contains some great ideas on how you can do it.

The Art of the Start: The Time-Tested, Battle-Hardened Guide for Anyone Starting Anything by Guy Kawasaki
Description: Science is behind all the good moves leaders do, but the art of it is the connective tissue that brings it all to life, giving it meaning and purpose. In this book, you have an end-to-end guide on how you need to approach and execute various tasks – from start to completion.
How it can help aspiring tech leaders: Grand ideas are the backbone of anything meaningful that happens in the world, but turning that idea into something tangible and moving? This book contains some great ideas on how you can do it.

Team of Teams: New Rules of Engagement for a Complex World by Stanley McChrystal, Chris Fussell, and David Silverman
Description: A bit of an unorthodox pick, but a book that’s much more about leadership than it is about military action and intricacies that revolve around it. Stanley McChrystal’s approach is one that defines the ills of today’s organizations – resistant to change, but badly in need of restructuring and reshaping in order to grow.
How it can help aspiring tech leaders: The real change must always come from the top – and the story in this book is all about that, supporting the old adage – be the change that you want to see around you.
Well, CTO Confessions is much more than just insightful and educational books - it's also about leaders, their path to becoming who they are, and the valuable lessons they learned along the way. Dive into one of our 100 episodes
Takeaway
When talking about difficult truths and difficult decisions, one must remember that the strain is all about finding the right circumstances and environments to execute and deliver them, rather than worry about the outfall of it all.
Stay tuned for part 4!
TC Gill
People Development
Coach and Strategist

The Books That Helped Shape the Tech Leaders of Today – Part 2
The Books That Helped Shape the Tech Leaders of Today – Part 2
Formal or informal education is, of course, essential for anyone that wants to one day rise to the top of an industry and become a leader. But that self-starting behavior, learning alone, devouring valuable information, experience, insight, and data can be the thing that sets you apart from the rest – and sets you up for long-term success.
We already presented the first tranche of books that helped shape today’s tech leaders, and there are many, many more to go. The way I make these lists is all mine, and I’m not dividing them by importance, category, genre, or any other way.
Why?
Simply because it’s too hard to put these amazing books in one box, so I decided to put them out in series, giving you – the curious reader – enough time to read and understand them, and be prepared for the next batch 😉
Here’s my part two of the books that helped the tech leaders of today become what they are. You can check the part One – here
The Manager's Path: A Guide for Tech Leaders Navigating Growth and Change by Camille Fournier
Description: Tech leadership is in many ways similar to leadership in other industries. BUT, considering the varying approaches, methods, and principles used in the tech world today, it’s fair to say that a book addressing this type of leadership was more than necessary.
How it can help aspiring tech leaders: You can learn various ways to tackle problems within an organization – at all levels – from lower to more senior. While it doesn’t dive deeply into the subject of the methods and explaining the why, it gives aspiring tech leaders the freedom to apply the methods in their own way and setting.

The Manager's Path: A Guide for Tech Leaders Navigating Growth and Change by Camille Fournier
Description: Tech leadership is in many ways similar to leadership in other industries. BUT, considering the varying approaches, methods, and principles used in the tech world today, it’s fair to say that a book addressing this type of leadership was more than necessary.
How it can help aspiring tech leaders: You can learn various ways to tackle problems within an organization – at all levels – from lower to more senior. While it doesn’t dive deeply into the subject of the methods and explaining the why, it gives aspiring tech leaders the freedom to apply the methods in their own way and setting.

Switch: How to Change Things When Change Is Hard by Chip Heath & Dan Heath
Description: We all know that changes in any tech company are not something that’s easily done. There are many variables at play, but this book does a good job of dividing the whole process into three stages, diving deeper into each, and providing a simple yet effective way to initiate change in your organization.
How it can help aspiring tech leaders: Flexibility in a tech company is crucial, and while important, it’s something that can vary with time. With the methods in this book you can learn how to better steer your teams towards the goal, direction, or course, that you want.
Switch: How to Change Things When Change Is Hard by Chip Heath & Dan Heath
Description: We all know that changes in any tech company are not something that’s easily done. There are many variables at play, but this book does a good job of dividing the whole process into three stages, diving deeper into each, and providing a simple yet effective way to initiate change in your organization.
How it can help aspiring tech leaders: Flexibility in a tech company is crucial, and while important, it’s something that can vary with time. With the methods in this book you can learn how to better steer your teams towards the goal, direction, or course, that you want.
The First 90 Days: Critical Success Strategies for New Leaders at All Levels by Michael Watkins
Description: A book unlike others of similar type – covering in depth all the strategies and potential that will keep you coming back to it to learn something new. It’s not a guide, it’s more of a position – a position from which you can look and observe situations, anticipate outcomes, and decide on moves.
How it can help aspiring tech leaders: As a tech leader, while you’ll definitely need your tech skills to be able to guide your teams, knowing how to handle your teams is of utmost importance if you’re to initiate and implement changes, and drive them towards goals.

The First 90 Days: Critical Success Strategies for New Leaders at All Levels by Michael Watkins
Description: A book unlike others of similar type – covering in depth all the strategies and potential that will keep you coming back to it to learn something new. It’s not a guide, it’s more of a position – a position from which you can look and observe situations, anticipate outcomes, and decide on moves.
How it can help aspiring tech leaders: As a tech leader, while you’ll definitely need your tech skills to be able to guide your teams, knowing how to handle your teams is of utmost importance if you’re to initiate and implement changes, and drive them towards goals.

The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win by Gene Kim & Kevin Behr
Description: Every company is unique in its own way, but more often than not, we’ve seen a vast number of businesses struggling with the same problems – the flow of information, organization, slow change and adaptation. This book provides blueprints that can help you shape your vision through which you can “unstuck” your organization.
How it can help aspiring tech leaders: Adaptability and quick reaction is crucial for all tech businesses looking to drive value to customers and users, and this book can help tech leaders in mitigating risks – all the while accepting a more flexible and more vibrant way of operating.
Well, CTO Confessions is much more than just insightful and educational books - it's also about leaders, their path to becoming who they are, and the valuable lessons they learned along the way. Dive into one of our 100 episodes
Takeaway
Let’s be real – there is no recipe for success that everyone can follow, but what we can do is learn from the experience and mistakes of others, and try to avoid them. The key to successfully implementing plans or changes is understanding that they are only as good as the people that execute them.
Stay tuned for part 3 of the series!
TC Gill
People Development
Coach and Strategist

Metaverse – “The Future” Or “A Feature”
The Metaverse is all the buzz now, and everybody is throwing this word around. But what does this word even mean, and how will it affect us in the real world? Or should we say – the digital world? Today, we’ll be talking more about this amazing concept, how it can be used, why it blew up suddenly, and the advantages it offers to anyone looking to jump into it.
To start, we need to clarify what the word, Metaverse, stands for. The Metaverse is a joint representation of two familiar concepts that people have been trying to perfect and implement in tech for a couple of years now – Augmented Reality (AR) and Virtual Reality (VR). This concept merges these two and creates a place where you could do things you’re doing in real life, but in a virtual setting – The Metaverse.Metaverse – “The Future” Or “A Feature”
What Is the Metaverse?



Why Is It Happening Now?
Being first out of the gate is really important in any new tech. So, companies like Facebook and Microsoft have already jumped on this trend and started making plans on how they can improve this “New Universe.”
Why is this happening at this moment of time, and why, all of a sudden, are companies starting to implement this new concept?
Part of the answer lies in Facebook’s rebranding that happened at the end of last year. This rebranding is the main reason why people think that the Metaverse is the same as “Meta,” Facebook’s rebranded company that includes all its subsidiaries.
But there’s more to this trend.
Constant improvement in technology, combined with the number of hours people are spending in front of their computers, allows companies to start entertaining the idea of combining the real and virtual world, and mix them up into a more intuitive world.
- Why spend money and go to the office when you could visit the virtual office from in the Metaverse, from the comfort of your own home?
- Why go to the supermarket and buy the groceries when you can visit the virtual E-store and make your order from there?
- Why go outside and socialize with people when you can go visit the nightclub in the Metaverse?
These are just some ways that these tech-giants are selling the Metaverse idea to regular people. And the ads and marketing campaigns promoting the Metaverse are becoming more and more prominent with each passing day. But why are they doing this? What benefits might they get from getting people onto the Metaverse, and how can they monetize it in order to start earning from people being there?
Monetization
To understand the monetization part of the Metaverse and how Tech Giants and other brands will be able to use it, first, we’ll need to understand the technologies that it implements and the features it offers to its “inhabitants.”
As we already mentioned above, VR and AR are a crucial part of the Metaverse, but so is blockchain tech – a decentralized network where the Metaverse is living. It also uses technologies such as NFTs and Cryptocurrencies that are also a part of the Blockchain in order to make the experience even better. Multiplayer games are also a part of the Metaverse, which will basically allow you to play them in virtual reality.
People are already spending crazy amounts of money in order to be the first ones, the early adopters of this idea. There are thousands of stories circulating on the internet. One of these stories is about an investor paying nearly half a million USD in order to be Snoop Dogg’s Neighbor in the Metaverse. Celebrities, as well as businesspeople, have paid a ridiculous amount of money, and regular people are following them.
Nike, Adidas, Dolce and Gabbana, and other famous brands are quietly preparing for the coming of the Metaverse. Other brands are not so quiet about it. Fashion companies, in particular, have dropped countless NFTs, which once the Metaverse becomes a thing, will be turned into fashion pieces there.
How Can You Monetize Your Business in The Metaverse?
As we already mentioned before, the Metaverse will become an integral part of the lives of many people. With the improvements people are making, there will be countless opportunities for businesses of all sizes, as well as earning possibilities for regular people.
So how will you be able to use the Metaverse for the advantage of your business? Here are a couple of ways we’ve thought about:
Virtual Products
Creating and selling virtual goods on the internet has been a proven technique for improving the financial state of your business. And, when you think about it, the manufacturing costs of a virtual product are much lower than those of a physical one. Add to that the obvious lack of shipping costs as well, and you can take out a significant chunk of the price of the product if you are able to sell it as a virtual/digital product.
Fashion brands have already jumped on this train as we mentioned earlier and started giving away virtual pieces of clothing alongside their NFTs.
NFT VIP Access
I am still to meet a person who hasn’t heard about NFTs. And this popularity is not based only on the fact that they’re a great way of making a quick buck. In fact, the reason why NFTs are becoming so popular is because these pieces of digital possessions can be used in the Metaverse as well. Whether it being a digital real-estate or something as minute as NFT shoes.
So, you, as a brand, could use these NFTs (whatever they might be) as a Special VIP Access to something your community might want.
Virtual Product Designing and Customization
Another thing you could do to improve your brand’s exposure would be to use the metaverse to allow your customers seamless and easy product customization. There are tons of configurators that allow laypeople an easy-to-use program in order to customize virtual products to their liking.
Virtual Showrooms, Meet-Ups and Seminars
Events such as Meet-ups, seminars, and showrooms are guaranteed to collect a massive audience if the reason why they’re meeting is good. Showrooms are a great way of letting people get a hands-on experience with your product without the need to buy it. So, the potential here is as big as your imagination.
Conclusion
So, what do you think of the Metaverse? Is it the future of the internet as we know it, or is it just a feature of it? Will you be investing in different parts of the Metaverse, or will you be waiting to see what will happen to the early adopters?

The Books That Helped Shape the Tech Leaders of Today – Part 1
The Books That Helped Shape the Tech Leaders of Today – Part 1
It’s been a bit over two years since I and the team here at IT Labs started work on the CTO Confessions podcast. We started small, going episode to episode, planning it all out and delivering and what began as somewhat of an experiment for us, turned out to be a goldmine of information and insight from some of the best leaders in the world of tech.
Our primary goal? Share this information with all the up-and-coming techies, giving them an insight into the minds and the modus operandi of some of the tech leaders, something from which they can learn.
The Literature
The one thing we learned from all the episodes was that tech leaders love to read. Books on organizational management, leadership, philosophies, guides – all kinds of books that helped them become better leaders.
And now, after more than 100 episodes of CTO Confessions, we found a pattern as we saw some titles repeating, so we dived deeper into these to see what was it that attracted them, and we put together a list of the books that we (and many tech leaders) think are a must-read for anyone looking to leave their mark in the tech industry.
Our first part of this series of pieces consists of the following books:

The Literature
The one thing we learned from all the episodes was that tech leaders love to read. Books on organizational management, leadership, philosophies, guides – all kinds of books that helped them become better leaders.
And now, after more than 100 episodes of CTO Confessions, we found a pattern as we saw some titles repeating, so we dived deeper into these to see what was it that attracted them, and we put together a list of the books that we (and many tech leaders) think are a must-read for anyone looking to leave their mark in the tech industry.
Our first part of this series of pieces consists of the following books:

Unboss by Lars Kolind
Description: Published in 2012, the book goes about analyzing traditional management and structure models in companies, and proposing a newer, fresher model which is more fitting for new businesses and start-ups, giving them a more human-centric approach that can help them grow.
Every department/part of an organization needs a specific strategy which is a part of a bigger, more significant strategy, aligned with the vision and mission of the company.
How it can help tech leaders: The need for newer working, hierarchical, and structure models is clear in the tech industry, as they are becoming the pioneers of inventing and implementing new ones that have an increased focus on the people, rather than just the projects and the business. Every aspiring tech leader should explore options on how they can structure/restructure their organization around the people and their needs.
Unboss by Lars Kolind
Description: Published in 2012, the book goes about analyzing traditional management and structure models in companies, and proposing a newer, fresher model which is more fitting for new businesses and start-ups, giving them a more human-centric approach that can help them grow.
Every department/part of an organization needs a specific strategy which is a part of a bigger, more significant strategy, aligned with the vision and mission of the company.
How it can help tech leaders: The need for newer working, hierarchical, and structure models is clear in the tech industry, as they are becoming the pioneers of inventing and implementing new ones that have an increased focus on the people, rather than just the projects and the business. Every aspiring tech leader should explore options on how they can structure/restructure their organization around the people and their needs.
Team Topologies: Organizing Business and Technology Teams for Fast Flow’ by Matthew Skelton
Description: Agile is the cornerstone on which sustainable organizational flow can be created, and this book goes deep into how you can transform your business to become more agile. In three parts, with each covering all the aspects that can help you achieve that desired company fast flow.
How it can help tech leaders: This one goes without saying, right? If you’re not thinking agile, what are you thinking about? It’s a better way to do things, and something, if you do it right, will set you up for long-term success and allow yourself to adapt to the highly volatile nature of the tech industry.

Team Topologies: Organizing Business and Technology Teams for Fast Flow’ by Matthew Skelton
Description: Agile is the cornerstone on which sustainable organizational flow can be created, and this book goes deep into how you can transform your business to become more agile. In three parts, with each covering all the aspects that can help you achieve that desired company fast flow.
How it can help tech leaders: This one goes without saying, right? If you’re not thinking agile, what are you thinking about? It’s a better way to do things, and something, if you do it right, will set you up for long-term success and allow yourself to adapt to the highly volatile nature of the tech industry.

The Fourth Industrial Revolution by Klaus Schwab
Description: We’ve had a few industrial revolutions so far, and the fact is, we’re currently going through the fourth one, in which the lines between the physical and the digital are slowly getting blurred. It’s an analysis of what might come, how it will be different from what was and what is, and how we can prepare for it.
How it can help tech leaders: The idea that we’re constantly changing, and progressing is something everyone knows, but to be part of the change, to be part of the people who will enable and power it up – we first need to learn how to master it. A powerful book that can help you expand and shape your vision and mission as a leader.
No Rules Rules: Netflix and the Culture of Reinvention’ by Reed Hastings, Erin Meyer
Description: Netflix has been known to have a distinct brand of culture inside – a culture that has helped shape the company and give its odd structure and unique way of operating. This book goes down into the details, a behind-the-scenes sort of view of how it all came to be.
How it can help tech leaders: Sure, proven and tested models that are proven to work will always be a go-to for some, but as a tech leader, the way something works doesn’t have to be all templatized. You can go your own way, and this book is a goldmine of ideas that can help you get into that mindset.

No Rules Rules: Netflix and the Culture of Reinvention’ by Reed Hastings, Erin Meyer
Description: Netflix has been known to have a distinct brand of culture inside – a culture that has helped shape the company and give its odd structure and unique way of operating. This book goes down into the details, a behind-the-scenes sort of view of how it all came to be.
How it can help tech leaders: Sure, proven and tested models that are proven to work will always be a go-to for some, but as a tech leader, the way something works doesn’t have to be all templatized. You can go your own way, and this book is a goldmine of ideas that can help you get into that mindset.

Bad Blood: Secrets and Lies in a Silicon Valley Startup’ by John Carreyrou
Description: A book about one of the biggest frauds in American history, and the biggest one in the tech industry – Theranos. The rise and fall, and all the details in between are in this book – simply put, this is a thriller with an ending that is bitter, but highly educational.
How it can help tech leaders: The how’s and why’s of some stuff that can happen are important, but the one thing that techies and tech leaders can learn from this book is that sometimes believing in an idea without being to objectively measure its feasibility can lead to disastrous results.
Well, CTO Confessions is much more than just insightful and educational books - it's also about leaders, their path to becoming who they are, and the valuable lessons they learned along the way. Dive into one of our 100 episodes
Takeaway
They say that nothing beats learning by doing, but truth be told, that ‘doing’ part can be much more efficient and educational if you get the facts straight and learn from the experience of others or get a bit deeper into the details. Stay tuned for part 2 of the series!
TC Gill
People Development
Coach and Strategist

Is Creative Thinking a Superpower by Ilina Pejoska Zaturoski
Is Creative Thinking a Superpower

Ilina Pejoska Zaturoski
UI/UX designer at IT Labs
What comes naturally to some, can be a hard task for others – take creativity, for example. A lot of people think that creativity is something you either have or you don’t – that it’s not something you can nurture, while others say that it’s just a matter of perspective and learning, and that creativity is something that we all have – albeit in a different shape. At our last Yay or Nay session, we decided to dive deep into this and finally give our take on the big question above.

At its core, creative thinking is intentionally gaining new insights and different ideas through existing information.
Often, creative thought involves tapping into unique styles of thinking and examining information from different viewpoints to see new patterns.
Anyone can foster a creative mind with some practice!
Using a wide variety of brainstorming strategies can help you discover innovative solutions for issues in various aspects of your life, be it personal relationships, work, etc.
The focus on creativity and innovation is important because most problems might require approaches that have never been created or tried before. It is a highly valued skill to have individually and one that businesses should always aspire to have among their ranks. The word creativity means a phenomenon where something new is created.
Creative thinking is a skill and, like any other, it needs constant exercise to stay sharp. You need to regularly expose yourself to situations in which a new idea is needed and surround yourself with like-minded people to achieve this goal.
Such a process is made easier with the use of certain techniques. They help get you on the right mindset and supply the basic structure to reach innovative ideas on demand.
Test your creative thinking skills with a simple mind game: Torrance’s test for creative thinking1: complete the drawing.
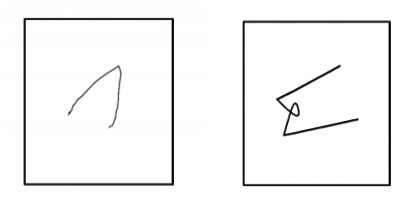
Classic Creativity Test, the Torrance Creative Thinking Test was introduced by psychologist Ellis Paul Torrance in the 1960s to conduct a more creatively inclined IQ test.
Types of Creative Thinking
Aesthetic thinking, divergent thinking, lateral thinking, convergent thinking, and inspirational thinking are five types of creative thinking that we will look at in more detail today.

- Divergent and convergent thinking are the most common ways to encourage creative thinking.
- Divergent thinking is like a traditional brainstorming session, where you produce as many solutions as your imagination allows.
- Convergent thinking, meanwhile, takes a more logical approach, encouraging you to gather facts and discover the most common solution to a problem. These strategies are often used together to extract new creative solutions.
- Inspirational thinking focuses on imagining the best scenarios to find a new way to solve the problem, while lateral thinking involves letting ideas flow in a step-by-step format.
- Aesthetic thinking focuses on reconstructing the problem to see its inherent beauty and value, as seen in a picture.
Brainstorming
This technique can be especially useful in small or large-scale problems that require a creative solution. The main goal is to form a group of people and throw around ideas without interference.
The general idea of brainstorming is that, by having an excess of creative potential solutions, it gets easier to reach one with the highest level of quality.
Brainstorming has several advantages that can help you exercise your creative thinking skills. For starters, it does not require a rigid structure to function, being very informal. However, it can be eased with professional guidance. Also, the people involved do not even need to be together at the same time, as you can use a virtual setting or put ideas into a shared document.
For it to work well, all participants must be aware of the problem that requires a creative solution and are familiar with how brainstorming works. In the end, do not forget to register all the ideas through proper documentation.

Mind mapping
The process of mind mapping helps you connect ideas you never imagined could be combined. Because of that, it might help you reach appropriate solutions while using creative thinking skills.
A mind map is a chart where you input ideas and connect them. It can have workable solutions to a problem, its immediate consequences, and be the best course of action to deal with them. Alternatively, your mind map can serve as a way to see a bigger picture regarding what you are trying to do.
Mind mapping can even be done individually. Sometimes, you may already have all the ideas you need but it is required to put them to paper. Creating a mind map helps to organize them and naturally reach conclusions.
Also, since a mind map is an infographic, those who were not part of the process can easily understand it. Therefore, it serves as a valid piece of documentation.
Examples of creativity skills
Besides these creative thinking techniques, we presented in this chapter, there are several skills you will need to develop to enjoy the advantages of the techniques. Some of the creativity skills may include:
• experimentation
• opposing views
• asking questions
• communication
• organization

Alternative Uses Task Test
Another fun game or assignment which you can use to improve or put your creative thinking to the test is the Alternative Uses Task.
Developed by J.P. Guilford in 1967, the Alternative Uses Task tests evaluates creativity by having you think of as many possible uses for a common household item (such as a brick, paperclip, or newspaper)
Example: name all the uses for a brick:
A paperweight
A doorstop
To throw through a window
To use as a weapon
To hit my sister on the head with
Try it: look around for a common house object, say a vase. How many uses can you think of for that vase?
What are the main benefits of creative thinking?
Developing your creative thinking skills is highly beneficial for any field of work. Every area needs people that can produce the best solutions to the everyday problems that arise, and creativity is critical to do that.
You can experience advantages such as these by developing creative thinking skills:
• ability to create the best solutions to daily demands, which provides value to clients and your own business.
• improvement on problem-solving for not only work-related matters but also those in your personal life.
• higher workplace involvement in daily activities and engagement, which is beneficial to a healthier environment.
• a better understanding of data — also known as data literacy — and how to present it through data storytelling.
• focus on self-improvement as you and your teammates will develop more soft skills.
• more effective teamwork and bonding since people grow used to bouncing off original ideas and learn each other’s creative traits.
STEM and creative thinking
Some people think of science and engineering as the opposite of art and creativity. That is not true. The fields of science, technology, engineering, and math (STEM) are highly creative. Designing a more efficient assembly line robot, writing an innovative new computer program, or developing a testable hypothesis are all highly creative acts.
The history of science and technology is filled with projects that did not work, not because of errors in technique or methodology, but because people remained stuck in their assumptions and old habits. STEM fields need creativity to flourish and grow.
In STEM industries like biomedicine, stimulating creativity by asking open-ended questions and creating fictional scenarios helps professionals find innovative solutions to health problems.
These questions encourage medical professionals to experiment and discover new ways of solving a persistent problem.
Through creative thinking, professionals in any field can discover unique answers to pressing problems.
Conclusion
Creative Thinkers relish the sight of a blank piece of paper. That is because they can see what is not yet real. And then make it real. They find inspiration in unexpected places and make connections between unrelated things. They are the people the team relies on to solve problems in clever, original ways.
Share your superpower.