
Common Challenges in Manual Software Testing and How to Overcome Them
Common Challenges in Manual Software Testing and How to Overcome Them
Manual software testing remains a cornerstone of the quality assurance process, offering human insight and adaptability cruical to ensuring reliable software products. This testing involves hands-on examination of software to ensure it meets user requirements without relying on automation tools. Testers independently develop and conduct test scenarios, constantly validating the software’s functionality against predefined criteria.

While manual testing has been a standard practice for some time, it struggles to keep up with the demands of Agile and Continuous Delivery methodologies. With frequent changes and updates, manually testing every aspect of the software becomes increasingly challenging. In this article, we’ll explore some of the most common challenges encountered by manual testers as well as the most effective strategies to overcome them.
Challenge: Time Limitations
Manual testing often means “juggling” project deadlines alongside comprehensive testing, which is a significant challenge. Testers frequently encounter time pressures that may result in insufficient test coverage or rushed testing, potentially compromising the product’s quality. Finding the right balance between “delivery on time” and “in-depth” testing requires effective time management and prioritization strategies.

Solution:
Prioritize Testing Scenarios
Firstly, prioritizing testing scenarios is crucial in manual testing, especially when time is tight. By identifying and focusing on critical test scenarios vital to the application’s functionality and the potential risks, testers ensure that essential areas get the coverage they need within a limited time. This smart approach allows for more efficient use of resources and provides maximum testing coverage despite time constraints.
Risk-Based Testing Methodologies
Using risk-based testing methodologies is another smart move when time is limited for manual testing. By evaluating tests based on their potential impact on the application and business goals, testers can manage time constraints effectively while still covering high-risk areas. This approach helps testers concentrate on areas with the most significant risk and optimize testing efforts to address potential issues within the available time.
Planning and Scheduling
Sometimes creating on-point test plans and schedules can be essential for navigating time limitations in manual testing. By outlining testing objectives, scope and timelines, testers establish a roadmap for their testing activities, ensuring that efforts are coordinated and efficient. Setting specific milestones and regularly reviewing the test plan allows for ongoing progress monitoring and adjustments to optimize testing within the given time frame.
Optimization
Optimizing test execution is vital to maximizing testing coverage and efficiency within time constraints in manual testing. Strategies such as the following can help streamline the execution process and maximize the available time:
- grouping related tests
- minimizing setup and teardown time
- using parallel testing
These tactics speed-up testing, reduce unnecessary steps, and ensure testing efforts are focused on achieving desired outcomes within the time limits.

Challenge: Test Case Management
Managing a large volume of test cases manually can be overwhelming and time-consuming. Challenges arise in organizing, updating and tracking these cases, resulting in inconsistencies and inefficiencies across the testing process. This issue becomes particularly noticeable during the Regression phase, where it can cause confusion regarding requirements that sync with the test cases and lead to execution delays.
Solution:
Adopting a simplified approach to writing test cases is crucial for maintaining agility and efficiency in dynamic projects characterized by constant changes and tight deadlines. Utilizing test outlines with a “Given-When-Then” syntax can streamline the process, providing a clear structure that allows quick adaptation to change without requiring extensive rewriting of traditional test cases. Also, using standardized test case templates boosts this method by offering ready-made frameworks for typical scenarios or functions. This helps testers easily access structured test cases and ensures broader coverage of required changes, making testing smoother in dynamic projects.
Furthermore, allocating specific time for reviewing and updating existing test cases is essential during task breakdown. When requirement alterations occur late in a sprint, testers may focus on running as many tests as possible within the available time frame.
When the requirements change at the last minute, it’s important to let everyone know that we may not be able to thoroughly test everything before the deadline. By being upfront about this challenge, the QAs ensure that everyone understands the situation at the end of the sprint. This helps developers and stakeholders know what to expect and allows them to set realistic timelines for testing. Clear communication helps everyone work together to handle these changes effectively.
Challenge: Repetitive Tasks
Manual testers often encounter the challenge of repeatedly executing the same test cases across various iterations or releases of a software product. This continuous repetition not only leads to a sense of monotony but also contributes to decreased productivity over time. Moreover, the repetitive nature of executing identical test cases increases the likelihood of overlooking potential defects in the system. This repetitive cycle can decrease testers’ enthusiasm and engagement, which can then impact the overall process and potentially lead to uncaught bugs into the software.

Solution:
To address the repetitive tasks that come with manual testing, one of the best strategies is to automate the execution of test scenarios that repeat frequently and cover the essential functions of the software. This means identifying the test cases that remain stable, repeat often, and don’t change much across different versions or updates of the software. By pinpointing these consistent and repetitive test scenarios, teams can leverage automation tools to streamline their testing processes. Automating these tests reduces the need for manual effort and ensures that tests are carried out consistently and reliably every time.
Moreover, automating repetitive tasks allows manual testers to focus their time and energy on more challenging and exploratory testing activities. This shift in focus not only improves the productivity of manual testers but also enhances the overall efficiency and effectiveness of the testing process. By reallocating resources from repetitive tasks to more complex testing endeavors, teams can uncover potential issues and areas for improvement that may have otherwise gone unnoticed.
Overall, by embracing automation for repetitive tasks, manual testing teams can unlock new levels of efficiency, productivity, and quality in their testing efforts.

Challenge: Communication and Collaboration
Effective communication and teamwork are absolutely vital in manual testing. Testers act as the bridge, linking developers, business analysts, and all other project participants. That’s why being on the same page is crucial. However, things aren’t always as smooth as they seem. With methodologies prone to constant change, important details can easily slip away. When everyone’s focused on different tasks, misunderstandings and misinformation can quickly arise.
Solution:
Collaboration between developers and QAs is crucial to enhancing testing effectiveness. By sharing knowledge with testers from the outset of development, developers empower them to make informed decisions about test prioritization, ensuring software quality and functionality. This collaboration streamlines the software development process, making it more effective and time efficient. A strategic approach involves:
- Scheduling additional meetings whenever new changes occur or additional questions arise from the requirements.
- Updating requirements in User Stories after each sync centralizes information and ensures everyone is on the same page.
Establishing new communication channels improves transparency, keeping all stakeholders informed and aligned with project developments. Empowering testers to make informed decisions not only benefits developers but also ensures comprehensive testing, making software components ready for deployment after each sprint. This approach not only eases the workload for QA testers but also guarantees that software products meet business requirements and function optimally.
Technical Challenges:
In manual testing, in addition to functionality testing, there are many technical challenges on a daily basis. Testers need to ensure that the software works well on different levels. The software should be checked to see how it performs under different conditions, such as:
- Various scenarios when a large number of people use the application at once (performance testing).
- Keeping the software safe from hackers (security testing).
- Ensuring the software works on various devices and systems (compatibility testing).

Solution:
Exploring the world of testing tools can be daunting, but it’s okay to take it one step at a time. Testers shouldn’t feel pressured to become experts overnight in every field of software testing. Mastery comes with practice and experience.
Start by familiarizing yourself with the basics of the tools you’ll be using. Reach out to colleagues who have more knowledge in the fields you are interested in so they can give you guidance and tips. They’ve been where you are and can offer valuable insights. It’s also beneficial to prioritize your learning objectives. Decide what areas of testing you want to focus on first and gradually expand your knowledge from there.
Once you feel comfortable with the knowledge level you have gained, try to incorporate it into your everyday work. Also, collaborating with your QA peers by splitting tasks between different testing types can provide better exposure to various aspects of testing, allowing you to build your skillset and gain a deeper understanding of the field.
Conclusion
Manual testing plays a vital role in ensuring the quality and reliability of software products, yet it has its challenges. These challenges merely scratch the surface, as testers encounter many more in their day-to-day work. By recognizing and addressing these common challenges, testers can enhance the effectiveness and efficiency of their testing efforts. It’s essential for testers to stay updated on the latest trends and approaches in the testing world to tackle common problems with fresh solutions. Don’t be afraid to try new things and step out of your comfort zone.

Author
Boris Kochov
Quality Assurance Engineer

What is GitHub Copilot in the Test Automation World?
What is GitHub Copilot in the Test Automation World?
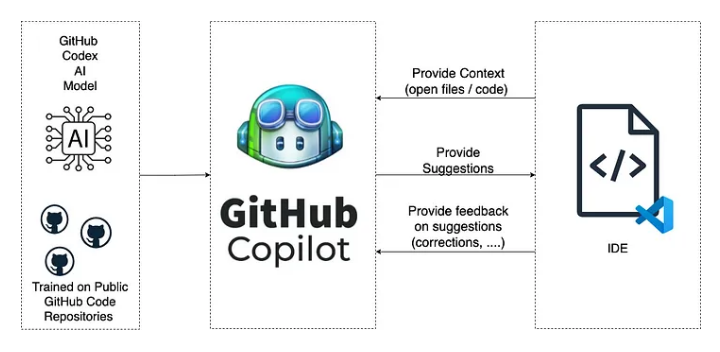
Test automation, a foundational element of contemporary software development practices, is critical for ensuring the reliability, functionality, and satisfaction of software users. As software becomes increasingly complex and the pressure for quicker development cycles mounts, the quest for inventive solutions to streamline the test automation process is more urgent than ever. This is where GitHub Copilot, born from a partnership between GitHub and OpenAI, comes into play, aiming to transform the way developers write, test, and maintain their code.
More than just another addition to the developer’s toolkit, GitHub Copilot is an AI-driven companion that adds a whole new layer to the coding and testing process. With its ability to interpret natural language and grasp the context of code, Copilot provides instant suggestions for completing code lines or even whole functions. This capability significantly cuts down on the time and effort needed to create solid test scripts and improve code quality.
This article sets out to explore the synergy between GitHub Copilot and test automation deeply. We’ll examine how this AI-enhanced tool is pushing the limits of automated testing by facilitating the generation of detailed test cases, refining existing test scripts, and guiding users toward best practices. GitHub Copilot emerges as a beacon of innovation, promising to speed up the development timeline while maintaining high standards of quality and reliability in software products.
Through our journey into the capabilities and applications of GitHub Copilot in test automation, we’ll discover its remarkable potential to transform. By the conclusion, the impact of GitHub Copilot in boosting test coverage, accelerating development cycles, and promoting an ethos of continuous learning and enhancement will be undeniable. Let’s embark on this exploration together, to see how GitHub Copilot is not merely influencing the future of test automation but reshaping the very landscape of software development.
What’s this about?
GitHub Copilot, in the context of test automation, refers to the application of GitHub's AI-powered tool, Copilot, to assist in writing, generating, and optimizing test code and scripts for software testing. GitHub Copilot is an AI pair programmer that suggests code and functions based on the work's context, making it a powerful tool for accelerating development and testing processes. When applied to Test Automation, it offers several benefits:
Code Generation for Test Scripts – GitHub Copilot can generate test cases or scripts based on your descriptions. This includes unit tests, integration tests, and end-to-end tests, helping to cover various aspects of application functionality.

Improving Test Coverage – By suggesting tests that you might not have considered, Copilot can help improve the coverage of your test suite, potentially catching bugs and issues that would have otherwise been missed.
Accelerating Test Development – Copilot can significantly reduce the time required to write test scripts by suggesting code snippets and complete functions. This can be particularly useful in Agile and DevOps environments where speed and efficiency are critical.
Learning Best Practices – For QA engineers, mainly those new to automation or specific languages/frameworks, Copilot can serve as a learning tool, suggesting best practices and demonstrating how to implement various testing patterns.
Refactoring and Optimization – Copilot can suggest improvements to existing test code, helping to refactor and optimize test scripts for better performance and maintainability.
However, while GitHub Copilot can be a valuable tool in Test Automation, it’s important to remember that it’s an aid, not a replacement for human oversight. The code and tests it generates should be reviewed for relevance, correctness, and efficiency. Copilot’s suggestions are based on the vast amount of code available on GitHub, so ensuring that the generated code complies with your project’s specific requirements and standards is crucial.

To effectively use GitHub Copilot in automation testing, you should:
- Clearly articulate what you’re testing through descriptive function names, comments, or both.
- Review the suggested code carefully to ensure it meets your testing standards and correctly covers the test scenarios you aim for.
- Be open to refining and editing the suggested code, as Copilot’s suggestions might not always be perfect or fully optimized for your specific use case.
Despite its capabilities, GitHub Copilot is a tool to augment the developer’s workflow, not replace it. It is crucial to understand the logic behind the suggested code and ensure it aligns with your testing requirements and best practices.
GitHub Copilot and Playwright
GitHub Copilot’s integration with test automation, particularly with frameworks like Playwright, exemplifies how AI can streamline the development of robust, end-to-end automated tests. Playwright is an open-source framework by Microsoft for testing web applications across different browsers. It provides capabilities for browser automation, allowing tests to mimic user interactions with web applications seamlessly. When combined with GitHub Copilot, developers and QA engineers can leverage the following benefits:
Code Generation for Playwright Tests
Automated Suggestions: Copilot can suggest complete scenarios based on your descriptions or partial code when you start writing a Playwright test. For example, if you’re testing a login feature, Copilot might suggest code for navigating to the login page, entering credentials, and verifying the login success.
Custom Functionality: Copilot can assist in writing custom helper functions or utilities specific to your application’s testing needs, such as data setup or teardown, making your Playwright tests more efficient and maintainable.
Enhancing Test Coverage
Scenario Exploration: Copilot can suggest test scenarios you might not have considered, thereby improving the breadth and depth of your test coverage. You ensure a more robust application by covering more edge cases and user paths.
Dynamic Test Data: It can help generate code for handling dynamic test data, which is crucial for making your tests more flexible and less prone to breakage due to data changes.
Speeding Up Test Development
Rapid Prototyping: With Copilot, you can quickly prototype tests for new features, getting instant feedback on your test logic and syntax, accelerating the test development cycle.
Learning Playwright Features: For those new to Playwright, Copilot serves as an on-the-fly guide, suggesting usage patterns and demonstrating API capabilities, thus flattening the learning curve.
Best Practices and Refactoring
Adherence to Best Practices: Copilot can suggest best practices for writing Playwright tests, such as using page objects or implementing proper wait strategies, helping you write more reliable tests.
Code Optimization: It can offer suggestions to refactor and optimize existing tests, improving their readability and performance.
Continuous Learning and Adaptation
As you use GitHub Copilot, it adapts to your coding style and preferences, making its suggestions more tailored and valuable.
Usage Example
Imagine writing a Playwright test to verify that a user can successfully search for a product in an e-commerce application. You might start by describing the test in a comment or writing the initial setup code. Copilot could then suggest the complete code for navigating to the search page, entering a search query, executing the search, and asserting that the expected product results appear.
Limitations and Considerations
While GitHub Copilot can significantly enhance the process of writing Playwright tests, it’s essential to:
Review and Test the Suggestions: Ensure the suggested code accurately meets your test requirements and behaves as expected.
Understand the Code: Rely on Copilot for suggestions but understand the logic behind the code to maintain and debug tests effectively.
In summary, GitHub Copilot can be a powerful ally in automating web testing with Playwright, offering speed and efficiency improvements while also helping to ensure comprehensive test coverage and adherence to best practices.

What data does GitHub Copilot collect?
GitHub Copilot, developed by GitHub in collaboration with OpenAI, functions by leveraging a vast corpus of public code to provide coding suggestions in real-time. Privacy and data handling concerns are paramount, especially when integrating such a tool into development workflows. Here is a general overview of the types of data GitHub Copilot may collect and use:
User Input – Copilot collects the code you are working on in your editor to provide relevant suggestions. This input is necessary for the AI to understand the context of your programming task and generate appropriate code completions or solutions.
Code Suggestions – The tool also records the suggestions it offers and whether they are accepted, ignored, or modified by the user. This data helps refine and improve the quality and relevance of future suggestions.
Telemetry Data – Like many integrated development tools, GitHub Copilot may collect telemetry data about how the software is used. This can include metrics on usage patterns, performance statistics, and information about the software environment (e.g., editor version, programming language). This data helps GitHub understand how Copilot is used and identify areas for improvement.
Feedback – Users have the option to provide feedback directly within the tool. This feedback, which may include code snippets and the user’s comments, is valuable for improving Copilot’s accuracy and functionality.
Privacy and Security Measures
GitHub has implemented several privacy and security measures to protect user data and ensure compliance with data protection regulations:
Data Anonymization: To protect privacy, GitHub attempts to anonymize the data collected, removing any personally identifiable information (PII) from the code snippets or user feedback before processing or storage.
Data Usage: The data collected is primarily used to improve Copilot’s algorithms and performance, ensuring that the tool becomes more effective and relevant to the user’s needs over time.
Compliance with GDPR and Other Regulations: GitHub adheres to the General Data Protection Regulation (GDPR) and other relevant privacy laws and regulations, providing users with rights over their data, including the right to access, rectify, and erase their data.
User Control and Transparency
Opt-out Options: Users concerned about privacy can limit data collection. For instance, telemetry data collection can often be disabled through settings in the IDE or editor extension.
Transparency: GitHub provides documentation and resources to help users understand what data is collected, how it is used, and how to exercise their privacy rights.
Users must review GitHub Copilot’s privacy policy and terms of use for the most current and detailed information regarding data collection, usage, and protection measures. As with any tool processing code or personal data, staying informed and adjusting settings to match individual and organizational privacy preferences is crucial.
Incorporate GitHub Copilot into the test automation project
Incorporating GitHub Copilot into an automation project involves leveraging its capabilities to speed up the writing of automation scripts, enhance test coverage, and potentially introduce efficiency and innovation into your testing suite. Here’s a step-by-step approach to integrating GitHub Copilot into your automation workflow:
1. Install GitHub Copilot
First, ensure that GitHub Copilot is installed and set up in your code editor. GitHub Copilot is available for Visual Studio Code, one of the most popular editors for development and automation tasks.
Visual Studio Code Extension: Install the GitHub Copilot extension from the Visual Studio Code Marketplace.
Configuration: After installation, authenticate with your GitHub account to activate Copilot.
2. Start with Small Automation Tasks
Use GitHub Copilot on smaller, less critical parts of your automation project. This allows you to understand how Copilot generates code and its capabilities and limitations without risking significant project components.
Script Generation: Use Copilot to generate simple scripts or functions, such as data setup, cleanup tasks, or primary test cases.
Code Snippets: Leverage Copilot for code snippets that perform everyday automation tasks, such as logging in to a web application or navigating through menus.
3. Expand to More Complex Automation Scenarios
As you become more comfortable with Copilot’s suggestions and capabilities, use it for more complex automation scenarios.
Test Case Generation: Describe complex test scenarios in comments and let Copilot suggest entire test cases. This can include positive, negative, and edge-case scenarios.
Framework-Specific Suggestions: Utilize Copilot’s understanding of various testing frameworks (e.g., Selenium, Playwright, Jest) to generate framework-specific code, ensuring your tests are not only functional but also adhere to best practices.
4. Optimize Existing Automation Code
Copilot can assist in refactoring and optimizing your existing automation codebase.
Code Refactoring: Use Copilot to suggest improvements to your existing automation scripts, making them more efficient or readable.
Identify and Fill Test Gaps: Copilot can help identify areas where your test coverage might be lacking by suggesting additional tests based on the existing code and project structure.
5. Continuous Learning and Improvement
GitHub Copilot is built on a machine-learning model that continuously evolves. Regularly using Copilot for different tasks lets you stay up-to-date with its capabilities.
Feedback Loop: Provide feedback on the suggestions made by Copilot. This helps improve Copilot and lets you learn new coding patterns and approaches.
6. Review and Quality Assurance
While GitHub Copilot can significantly speed up the development of automation scripts, it’s crucial to maintain a rigorous review process.
Code Review: Ensure that all code generated by Copilot is reviewed by a human for logic, efficiency, and adherence to project standards before being integrated into the project.
Testing: Subject Copilot-generated code to the same testing and quality assurance level as any other code in the project.
7. Collaboration and Sharing Best Practices
Share your experiences and best practices for using GitHub Copilot in automation projects with your team. Collaboration can lead to discovering new ways to utilize Copilot effectively.
Documentation: Document how Copilot has been used in the project, including any configurations, customizations, or specific practices that have proven effective.
Knowledge Sharing: Hold sessions to share insights and tips on leveraging Copilot for automation tasks, fostering a culture of innovation and continuous improvement.
Incorporating GitHub Copilot into your automation project can lead to significant productivity gains, enhanced test coverage, and faster development cycles. However, it's crucial to view Copilot as a tool to augment human expertise, not replace it. Properly integrated, GitHub Copilot can be a powerful ally in building and maintaining high-quality automation projects.
Example 1 – Adding Locators and Methods
Incorporating locators and methods into a page.ts file for a web automation project using tools like Playwright or Selenium can significantly benefit from the assistance of GitHub Copilot. This approach enables you to streamline the process of defining page objects and their corresponding methods, enhancing the maintainability and readability of your test scripts. Here is a step-by-step guide on how to do this with the help of GitHub Copilot:
Set Up Your Environment
Ensure that GitHub Copilot is installed and activated within your code editor, such as Visual Studio Code. Open your automation project and navigate to the page.ts file where you intend to add locators and methods.
Define Page Object Locators
Start by adding comments in your page.ts file describing the elements you must interact with on the web page. For example:
// Username input field
// Password input field
// Login button
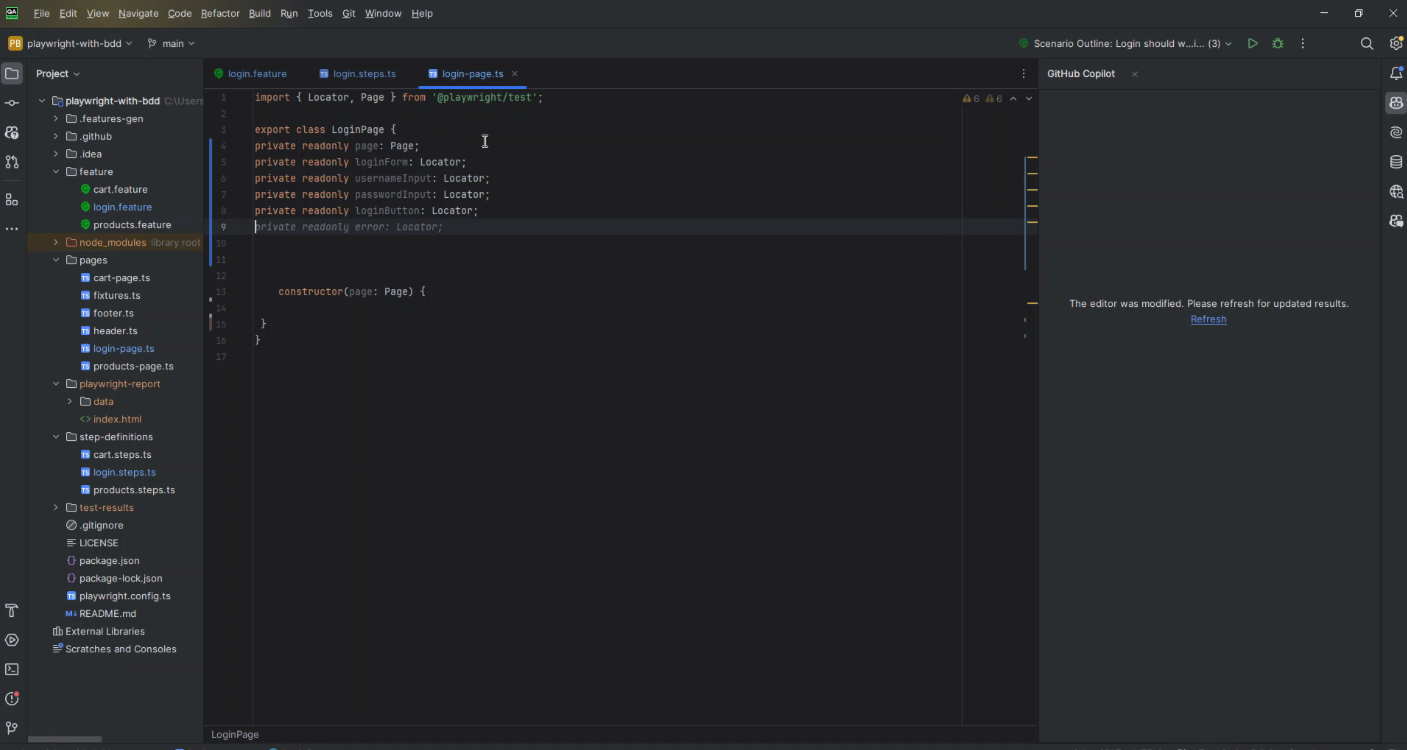
Then, begin typing the code to define locators for these elements. GitHub Copilot should start suggesting completions based on your comments and the context of your existing code. For instance, if you’re using Playwright, it might offer something like:
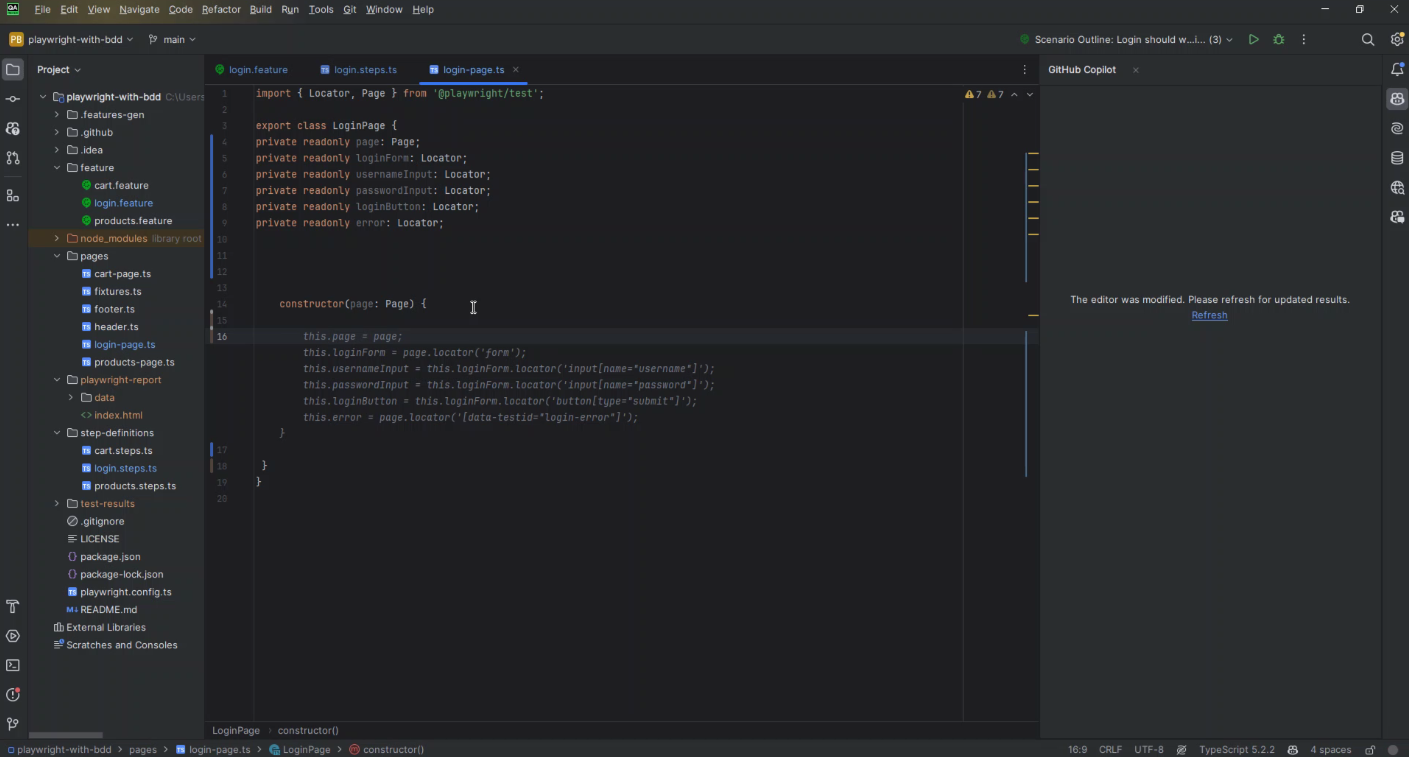
Implement Page Methods
After defining the locators, you will want to add methods to interact with these elements. Again, start with a comment describing the action you want to perform, such as logging in:
// Method to log in
Start typing the method implementation and let GitHub Copilot suggest the method’s body based on your defined locators. For a login method, it might offer:
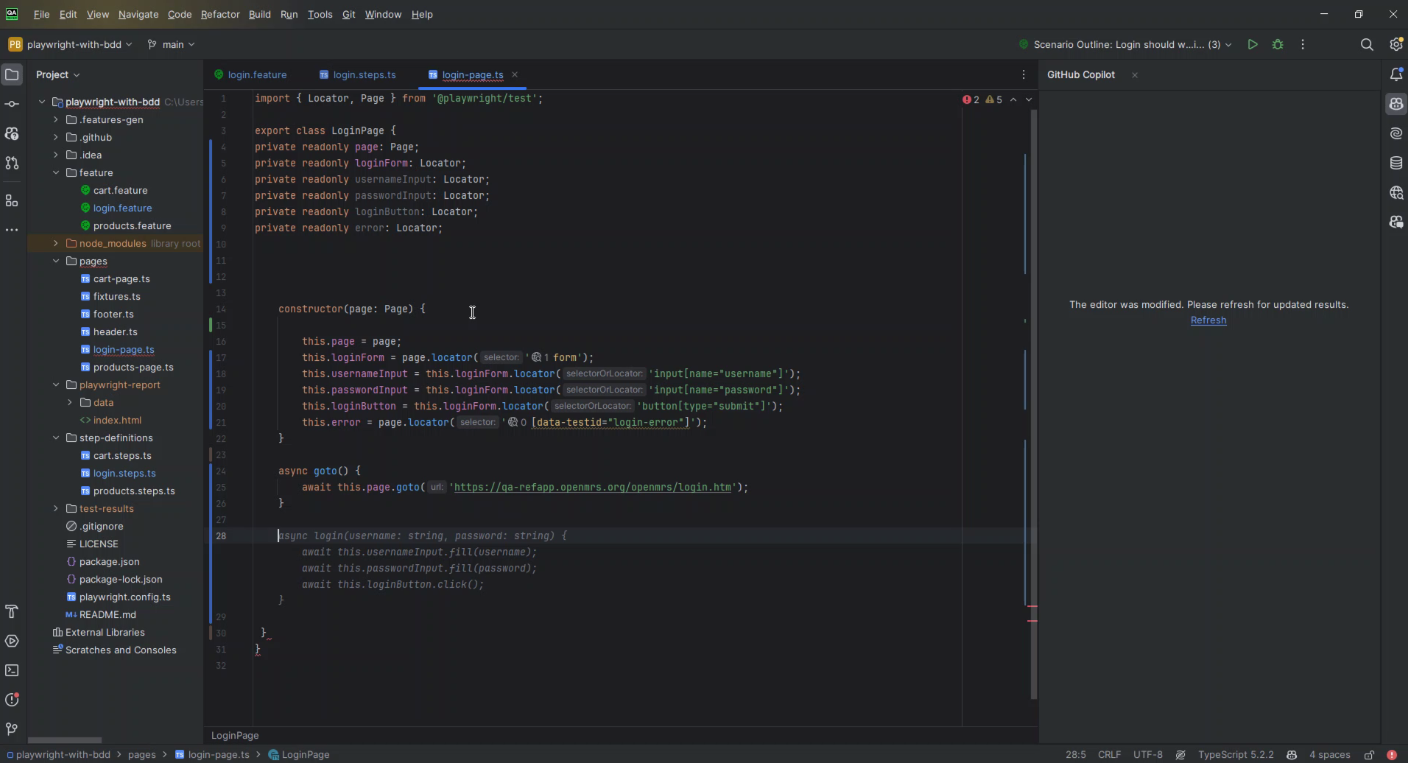
Refine Suggestions
GitHub Copilot’s suggestions are based on the patterns it has learned from a vast corpus of code, but they might not always be perfect for your specific use case. Review the suggestions carefully, making adjustments to ensure they meet your project’s requirements.
Test Your Page Object
Once you’ve added the locators and methods with the help of GitHub Copilot, it’s crucial to test them to ensure they work as expected. Write a test case that utilizes the new page object methods and run it to verify the interactions with the web page are correct.
Iterate and Expand
Add more locators and methods to your page objects as your project grows. GitHub Copilot can assist with this process, helping you generate the code needed for new page interactions quickly.
Share Knowledge
Share this knowledge with your team if you find GitHub Copilot helpful for specific tasks or discover best practices. Collaborative learning can help everyone make the most of the tool.
Example 3 – Analyzing codebase and multiple suggestions
When leveraging GitHub Copilot for analyzing a codebase and generating multiple suggestions in a test automation project, it's crucial to approach this with a strategy that maximizes the tool's capabilities while ensuring the quality and relevance of the suggestions. Here's a guide on how to effectively use GitHub Copilot for this purpose:
Understand Copilot’s Capabilities
First, recognize that GitHub Copilot generates suggestions based on the context of the code you’re working on and the comments you provide. It’s trained on a vast array of code from public repositories, making it a versatile tool for generating code across many languages and frameworks.
Provide Detailed Comments
Use detailed comments to describe the functionality you want to implement or the issue you’re trying to solve. GitHub Copilot uses these comments as a primary source of context. The more specific you are, the more accurate the suggestions.
– Example:
Instead of a vague comment like `// implement login test`, use something more descriptive like `// Test case: Ensure that a user can log in with valid credentials and is redirected to the dashboard`.
Break Down Complex Scenarios
For complex functionalities, break down the scenario into smaller, manageable pieces. This approach makes solving the problem easier and helps Copilot provide more focused and relevant suggestions.
– Example:
If you’re testing a multi-step form, describe and implement tests for each step individually before combining them into a comprehensive scenario.
Explore Multiple Suggestions
GitHub Copilot offers several suggestions for a given code or comment. Don’t settle for the first suggestion if it doesn’t perfectly fit your needs. You can cycle through different suggestions to find the one that best matches your requirements or inspires the best solution.
Refine and Iterate
Use the initial suggestions from Copilot as a starting point, then refine and iterate. Copilot’s suggestions might not always be perfect or fully optimized. It’s essential to review, test, and tweak the code to ensure it meets your standards and fulfils the test requirements.
Leverage Copilot for Learning
GitHub Copilot can be an excellent learning tool for unfamiliar libraries or frameworks. By analyzing how Copilot implements specific tests or functionalities, you can gain insights into best practices and more efficient ways to write your test scripts.
Collaborate and Review
Involve your team in reviewing Copilot’s suggestions. Collaborative review can help catch potential issues and foster knowledge sharing about efficient coding practices and solutions Copilot may have introduced.
Utilize Copilot for Boilerplate Code
Use GitHub Copilot to generate boilerplate code for your tests. This can save time and allow you to focus on the unique aspects of your test scenarios. Copilot is particularly good at generating setup and teardown routines, mock data, and standard test structures.
Continuous Learning and Adaptation
GitHub Copilot learns from the way developers use it. The more you interact with Copilot, providing feedback and corrections, the better it offers relevant suggestions. Engage with it as a dynamic tool that adapts to your coding style and preferences over time.
Ensure Quality Control
Always remember that you and your team are responsible for the code’s quality and functionality. Use GitHub Copilot as an assistant, but ensure that all generated code is thoroughly reviewed and tested according to your project’s standards.
Following these strategies, you can effectively leverage GitHub Copilot to analyze your codebase and generate multiple relevant suggestions for your test automation project. Copilot can significantly speed development, enhance learning, and introduce innovative solutions to complex problems. However, it’s crucial to remain engaged in the process, critically evaluating and refining the suggestions to ensure they meet your project’s specific needs and quality standards.
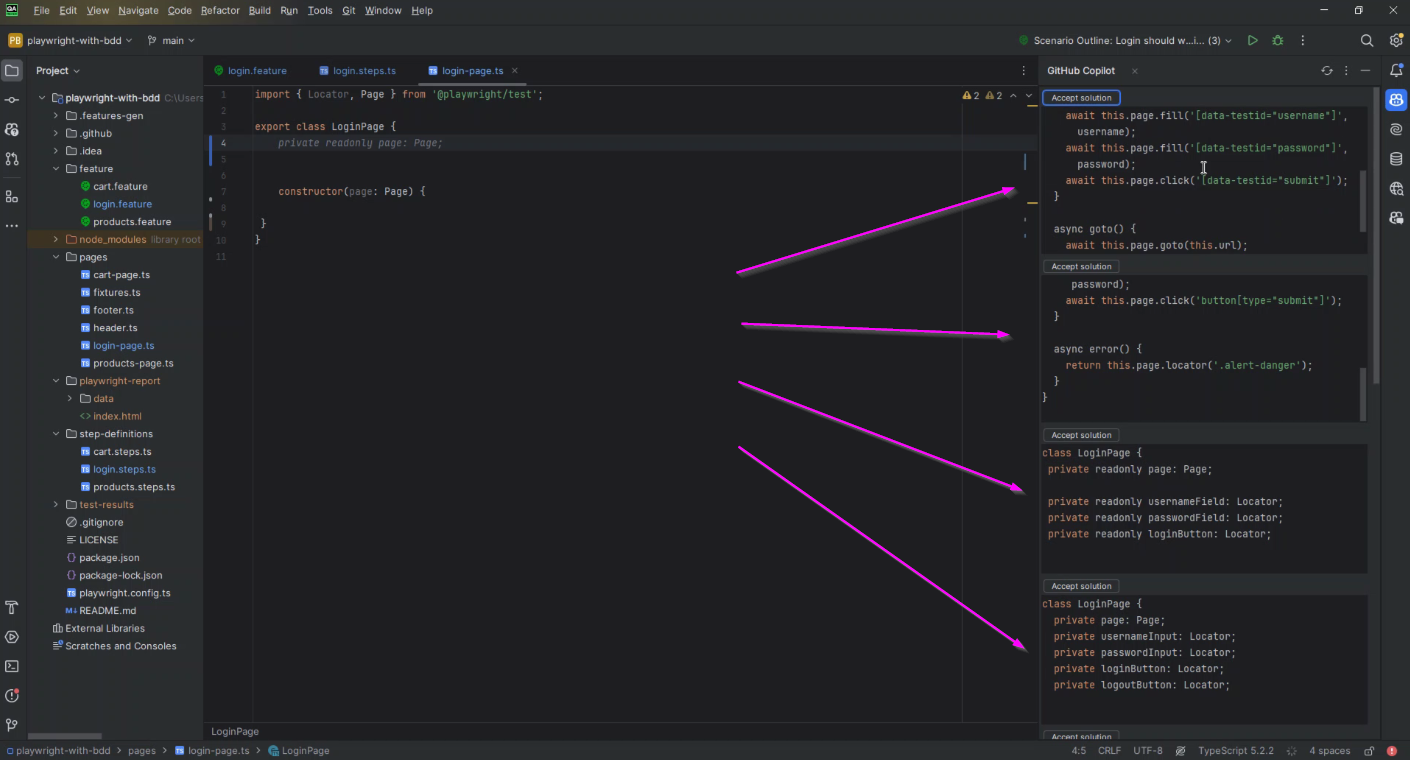
Example 4 – Generating Test Scenarios
Generating test scenarios with GitHub Copilot involves leveraging its AI-powered capabilities to brainstorm, refine, and implement detailed test cases for your software project. GitHub Copilot can assist in covering a broad spectrum of scenarios, including edge cases you might not have initially considered. Here’s how you can effectively use GitHub Copilot for generating test scenarios:
Start with Clear Descriptions
Begin by providing GitHub Copilot with explicit, descriptive comments about the functionality or feature you want to test. The more detailed and specific your description, the better Copilot can generate relevant test scenarios.
– Example:
Instead of simply commenting `// test login`, elaborate with details such as `// Test scenario: Verify that a user can successfully log in with valid credentials and is redirected to the dashboard. Include checks for incorrect passwords and empty fields.`
Utilize Assertions
Specify what outcomes or assertions should be tested for each scenario. Copilot can suggest various assertions based on the context you provide, helping ensure your tests are thorough.
– Example:
`// Ensure the login button is disabled when the password field is empty.`
Explore Edge Cases
Ask Copilot to suggest edge cases or less common scenarios that might not be immediately obvious. This can significantly enhance your test coverage by including scenarios that could lead to unexpected behaviors.
– Example:
`// Generate test cases for edge cases in user registration, such as unusual email formats and maximum input lengths.`
Generate Data-Driven Tests
Data-driven testing is crucial for covering a wide range of input scenarios. Prompt Copilot to generate templates or code snippets for implementing data-driven tests.
– Example:
`// Create a data-driven test for the search functionality, testing various input strings, including special characters.`
Implement Parameterized Tests
Parameterized tests allow you to run the same test with different inputs. Use Copilot to help write parameterized tests for more efficient scenario coverage.
– Example:
`// Write a parameterized test for the password reset feature using different types of email addresses.`
Leverage Copilot for Continuous Integration (CI) Tests
If your project uses CI/CD pipelines, Copilot can suggest scenarios specifically designed to be executed in CI environments, focusing on automation and efficiency.
– Example:
`// Suggest test scenarios for CI pipeline that cover critical user flows, ensuring quick execution and minimal flakiness.`
Refine Suggestions
Review the test scenarios and code snippets suggested by Copilot. While Copilot can provide a strong starting point, refining these suggestions to fit your project’s specific context and standards is crucial.
Iterate and Expand
Use the initial set of scenarios as a foundation, and continuously iterate by adding new scenarios as your project evolves. GitHub Copilot can assist with this ongoing process, helping identify new testing areas as features are added or modified.
Collaborate with Your Team
Share the generated scenarios with your team for feedback. Collaborative review can help ensure the scenarios are comprehensive and aligned with the project goals. GitHub Copilot can facilitate brainstorming sessions, making the process more efficient and thorough.
Document Your Test Scenarios
Finally, document the generated test scenarios for future reference and new team members. GitHub Copilot can even assist in developing documentation comments and descriptions for your test cases.
GitHub Copilot can significantly streamline the process of generating test scenarios, from everyday use to complex edge cases. By providing detailed descriptions and leveraging Copilot’s suggestions, you can enhance your test coverage and ensure your software is robust against various inputs and conditions. Remember, the effectiveness of these scenarios depends on your engagement with Copilot’s suggestions and your willingness to refine and iterate on them.
Conclusion: Redefining Test Automation's Horizon
Integrating advanced automation tools marks a pivotal moment in the evolution of Test Automation, bringing about a significant broadening of capabilities and a redefinition of the quality assurance process. This progress represents not merely an advancement in automation technology but a stride towards a future where QA is seamlessly integrated with creativity, insight, and a deep commitment to enhancing user experience. In this future landscape, QA professionals evolve from their conventional role of bug detectors to become creators of digital experiences, ensuring software is not only technically sound but also excels in delivering user satisfaction and upholding ethical standards.
Efficiency and Innovation as Core Pillars
The collaboration between advanced automation tools introduces an era marked by heightened efficiency, facilitating quicker release cycles without sacrificing output quality. This is made possible by automating mundane tasks, applying intelligent code and interface analyses, and employing predictive models to identify potential issues early. These technological advancements free QA engineers to use their skills in areas that benefit from human insight, such as enhancing user interface design and formulating strategic testing approaches.
Elevating Intuition and Creativity
Looking ahead, the QA process will transcend traditional test scripts and manual verification, becoming enriched by the intuitive and creative contributions of QA professionals. Supported by AI, these individuals are empowered to pursue innovative testing approaches, navigate the complexities of software quality on new levels, and craft inventive solutions to intricate problems. This envisioned future places a premium on the unique human ability to blend technical knowledge with creative thinking, pushing the boundaries of what is possible in quality assurance.
Achieving Excellence in Software Experiences
The primary goal of delivering outstanding software experiences becomes increasingly feasible. This ambition extends beyond merely identifying defects sooner or automating testing procedures; it encompasses a comprehensive understanding of user requirements, ensuring software is accessible and inclusive, and fostering trust through robust privacy and security measures. Test Automation emerges as a crucial element in the strategic development of software, significantly impacting design and functionality to fulfil and surpass user expectations.
Transformation of QA Engineers’ Roles
As the industry progresses toward this enriched future, the transformation in the role of QA engineers signifies a more comprehensive evolution within the software development field. They are more significant in decision-making processes, affecting product design and strategic orientation. Their expertise is sought not only for verifying software’s technical accuracy but also for their deep understanding of user behavior, preferences, and requirements.
Navigating the Path Forward
Realizing this vision involves overcoming obstacles, necessitating ongoing innovation, education, and adaptability. The benefits of pursuing this path are substantial. By adopting advanced technologies and methodologies, QA teams can refine their processes and contribute to developing digital products that genuinely connect with and satisfy users. Successful navigation of this path relies on interdisciplinary collaboration, continuous learning, and a dedication to achieving excellence.
Elevating Human Experience Through Technology
Ultimately, this envisioned future of Test Automation represents a broader industry call to utilize technology for efficiency and profit and as a vehicle for enhancing the human condition. In this imagined future, technology produces functional, dependable, enjoyable, and inclusive software aligned with our collective values and ethics. Integrating advanced tools and methodologies signifies the initial steps toward a future where quality assurance is integral to developing software that positively impacts lives and society.

Author
Jagoda Peric
Quality Assurance Engineer

What are the Top 5 CTO Challenges in Leading Teams – Part 5
What are the Top 5 CTO Challenges in Leading Teams – Part 5
By TC Gill

Welcome to Part 5 of our series on the Top 5 CTO Challenges in Leading Teams. In this installment, we delve into a critical aspect of tech leadership: budget management. In today’s tech landscape, where technology functions are not just cost centers but integral to business success, effective budget management is paramount. Join us as we explore the challenges CTOs face in budget management and discover strategies to navigate them successfully.
The Challenge of Budget Management
In the realm of technology leadership, effective budget management encompasses far more than mere financial oversight. It represents a strategic endeavor marked by a series of intricate challenges that CTOs face in their pursuit of fostering innovation while ensuring operational efficiency. These challenges are multifaceted, reflecting the dynamic interplay between forecasting accuracy, balancing innovation with operational necessities, and managing stakeholder expectations within the rapidly evolving technology landscape.


Forecasting Accuracy and Unpredictability
One of the most significant hurdles in budget management is the ability to forecast future financial needs with a high degree of accuracy. The tech industry is known for its rapid pace of change, with new technologies emerging and market demands evolving at an unprecedented rate. This unpredictability makes it challenging for CTOs to anticipate expenses accurately, often leading to discrepancies between forecasted and actual spending. The task is further complicated by the need to stay ahead of technological advancements, requiring allocations for new investments that were not part of the original budget planning. This scenario demands a flexible approach to budgeting, one that allows for quick adjustments in response to technological shifts without jeopardizing the financial stability of ongoing projects.
Balancing Innovation with Operational Necessities
Another critical challenge is the allocation of resources between innovative projects and the maintenance of existing operations. CTOs are tasked with driving growth through innovation while ensuring the reliability and efficiency of current systems. This balancing act is complicated by the competing demands of projects, each vying for a share of the budget based on their potential to contribute to the organization's strategic goals. The challenge lies in making informed decisions that prioritize projects not only on their immediate impact but also on their alignment with long-term objectives. This often involves tough choices, such as reallocating resources from popular initiatives to those that promise greater strategic value, all while maintaining operational excellence.


Managing Stakeholder Expectations
Compounding these challenges is the need to manage the expectations of a diverse group of stakeholders, including team members, executives, and external partners. Each group has its own set of priorities and expectations regarding budget allocations, making it difficult to achieve consensus. For instance, while the development team may push for increased funding for cutting-edge research, the finance department might emphasize cost reduction and efficiency. Navigating these differing priorities requires CTOs to engage in clear communication and consensus-building, striving to align budget allocations with the organization's overarching strategic goals. This involves making difficult decisions, negotiating compromises, and sometimes, advocating for budget adjustments to ensure both innovation and operational stability are adequately funded.
The Steps Needed for Effective Budget Management
In the fast-paced world of technology, Chief Technology Officers (CTOs) face the tricky balance of planning for the unknown and making every penny count. Gone are the days of set-it-and-forget-it budgets. Today, managing finances means being as nimble and innovative as the technologies we work with. We're diving into three key strategies that make budgeting less of a headache and more of a strategic advantage: Dynamic Budget Formulation and Adjustment, Prioritization and Resource Optimization, and Embracing Agile Financial Planning. These approaches not only help tackle the unpredictable nature of tech finance but also ensure that CTOs can keep their teams innovating, operations smooth, and stakeholders happy—all without breaking the bank. Let's explore how these strategies can transform budget woes into budget wins.


Dynamic Budget Formulation and Adjustment
To combat forecasting inaccuracies and the unpredictability of the tech landscape, adopting a dynamic approach to budget formulation and adjustment is crucial. This strategy involves regular review and realignment of the budget to reflect changing priorities and market conditions. By allowing for frequent adjustments, CTOs can ensure that financial planning remains flexible, responsive to technological shifts, and capable of accommodating new investments. This approach directly tackles the challenge of forecasting accuracy by instituting a framework that supports swift adaptation to unforeseen financial needs and opportunities.
Prioritization and Resource Optimization
Addressing the challenge of balancing innovation with operational necessities, the solution of prioritization and resource optimization is key. By employing a structured evaluation process for projects, such as the MoSCoW method, CTOs can identify and allocate resources to initiatives that align with the organization's strategic goals and offer the highest potential impact. This strategic prioritization ensures that limited resources are directed toward projects that not only promise significant returns but also maintain or enhance operational stability. This solution facilitates informed decision-making, enabling CTOs to navigate the delicate balance between fostering innovation and sustaining existing operations effectively.


Embracing Agile Financial Planning
To manage the complex interplay of stakeholder expectations, adopting an agile approach to financial planning offers a pathway to achieving consensus and aligning budget allocations with strategic objectives. Agile budgeting, characterized by its flexibility and iterative nature, allows for ongoing adjustments based on feedback from stakeholders and changes in business needs. This method promotes transparency and collaboration, encouraging input from various departments and ensuring that budget decisions support the overall vision of the organization. By fostering an environment where financial planning is adaptable and inclusive, CTOs can more effectively manage stakeholder expectations, negotiate compromises, and ensure that budget allocations reflect a shared understanding of the organization's priorities.
Conclusion
So, there you have it. What “I” think are the top five challenges. This is just from the perspectives of my lens and the conversations I’ve had with tech leaders. What are the topics that you would have listed in addition to these? I’d love to know. Drop me a line on tc.gill@it-labs.com if you feel there is a particular one that could be mentioned and unpacked.

So, what do you think? What do the challenges mentioned here mean to you? Did they get you thinking. How can you overcome these challenges? Is there something on the other side of them? An “opportunity” maybe! If you can get them out of the way.
Drop me a line and let me know your thoughts. In the meantime, keep growing and thriving.
Leadership is a ride… do your best to enjoy it.

Author
TC Gill – People Development Coach and Strategist

What are the Top 5 CTO Challenges in Leading Teams – Part 4
What are the Top 5 CTO Challenges in Leading Teams – Part 4
By TC Gill

The tech industry evolves rapidly, and CTOs must lead their teams through these changes, often requiring quick adaptations in skills, tools, and processes. It is a tough gig. I often see CTOs like time lords (reference to the main character in the famous “Dr Who” series). You not only have to deal with the past (legacy), but there is also the future (new innovations) and the most important moment, the here and now. It is a lot to navigate, and this comes up often in my tech leader conversations.
Handling the challenge of rapid changes in the tech world can sometimes be the make or break for a company and for teams.
The challenge of dealing with rapid technological changes
As we delve into the intricacies of this challenge, it becomes apparent that it encompasses several daunting aspects, each presenting its own set of hurdles to overcome.
Continuous Adaptation
In the dynamic landscape of technology, where innovations emerge at an unprecedented pace, the need for continuous adaptation is paramount. CTOs and their teams must remain agile, ready to evolve their skills, tools, and processes to stay ahead of the curve. This entails fostering a culture of lifelong learning, where team members are encouraged to embrace new technologies, acquire new skills, and adapt their workflows to meet evolving demands. By prioritizing continuous adaptation, CTOs ensure that their teams remain resilient and responsive to the ever-changing technological landscape.

Navigating Legacy and Innovation
Navigating the delicate balance between legacy systems and innovation is a challenge that CTOs must confront head-on. While legacy systems may be deeply ingrained within an organization, inhibiting agility and scalability, embracing new innovations is essential for driving progress and maintaining competitiveness. CTOs must carefully assess legacy systems, identifying opportunities for modernization and integration with innovative technologies. This requires strategic planning, effective communication, and meticulous execution to ensure seamless transitions and integration. By striking the right balance between addressing legacy systems and embracing innovation, CTOs empower their teams to leverage the best of both worlds, driving efficiency, and innovation.
Information Overload
In an era characterized by an abundance of information, staying informed about the latest technological trends and advancements can be overwhelming for CTOs and their teams. The sheer volume of information available can lead to information overload, making it challenging to discern relevant insights from the noise. To mitigate this challenge, CTOs must adopt a discerning approach to information consumption, prioritizing sources that provide valuable and actionable insights. Additionally, leveraging tools and technologies such as data analytics and machine learning can help streamline the process of gathering, analyzing, and synthesizing information. By empowering their teams with the right tools and resources, CTOs enable them to navigate the vast sea of information effectively, minimizing the risk of information overload and potential blind spots.
Maintaining Team Morale
Constant changes and the pressure to keep up with the latest technologies can take a toll on team morale and productivity. As CTOs lead their teams through the challenges of rapid technological changes, it’s essential to prioritize the well-being and morale of team members. This involves fostering a supportive and inclusive work environment where team members feel valued, empowered, and motivated to succeed. CTOs can nurture team morale by providing opportunities for professional growth and development, recognizing and celebrating achievements, and fostering open communication and collaboration. By investing in their team’s well-being, CTOs cultivate a positive and resilient culture that enables their teams to thrive amidst the demands of rapid technological changes.

How to stay ahead of the big tech development curve
So, what are the strategies for tech leaders to navigate rapid technological changes in the face of the relentless pace. Here are a few I feel would be good to focus on.
Embrace Agile Methodologies and Continuous Learning
Cultivating an Agile culture within the organization is paramount for adapting to the rapidly changing tech landscape. Agile methodologies such as Scrum or Kanban promote flexibility, iterative development, and responsiveness to change, enabling teams to deliver value to customers more efficiently. By embracing Agile principles, CTOs foster a collaborative environment where teams can adapt to evolving requirements and address challenges in a timely manner. Additionally, encouraging continuous learning among team members is essential for staying ahead in the tech industry. Providing opportunities for online courses, industry events, and knowledge sharing sessions empowers team members to enhance their skills and stay abreast of emerging technologies. This commitment to continuous learning ensures that teams remain adaptable and equipped to tackle new challenges as they arise.
Stay Proactively Informed
Maintaining a proactive stance in seeking out the latest information and insights in the tech world is critical for CTOs to effectively lead their teams. Actively monitoring industry news, participating in relevant forums and communities, and engaging with thought leaders allows CTOs to anticipate changes and trends. By staying informed about technological advancements, CTOs can make informed decisions and proactively prepare their teams for upcoming challenges. Additionally, dedicating time to researching and studying emerging technologies enables CTOs to identify opportunities for innovation and growth within their organization. This proactive approach ensures that teams remain competitive and future-ready in the ever-evolving tech landscape.
Encourage Open Dialogue
Fostering an environment of open dialogue within tech teams is essential for promoting collaboration and innovation. By encouraging discussions about industry changes and technological advancements, CTOs create a space where team members can share insights, express concerns, and propose solutions collaboratively. Regular team meetings and brainstorming sessions provide opportunities for team members to voice their opinions and contribute to the collective knowledge of the team. Furthermore, creating platforms and tools that facilitate communication and collaboration, such as chat channels and virtual whiteboards, enables teams to harness their collective intelligence effectively. This culture of open dialogue and collaboration empowers teams to tackle challenges more efficiently and drive continuous improvement.
Takeaway
As the tech landscape continues to evolve at a rapid pace, CTOs and their teams face multifaceted challenges that demand innovative solutions. Embracing Agile methodologies and a culture of continuous learning fosters adaptability and resilience, empowering teams to navigate change with agility. By proactively seeking out insights and trends, CTOs position their teams for success in a dynamic environment, driving innovation and growth. Furthermore, fostering open dialogue and collaboration cultivates a culture of creativity and problem-solving, enabling teams to thrive amidst uncertainty. Together, these strategies equip CTOs and their teams to embrace the challenges of rapid technological changes, charting a course for continued excellence and achievement in the ever-evolving tech landscape. everyone informed but also helps in collectively navigating the challenges and opportunities presented by new technologies.
By implementing these strategies, tech leaders reduce their blind spots and can effectively guide their teams through the complexities of rapid technological changes, ensuring agility, preparedness, and continued growth in an ever-evolving tech landscape.

Author
TC Gill – People Development Coach and Strategist

What are the Top 5 CTO Challenges in Leading Teams – Part 3
What are the Top 5 CTO Challenges in Leading Teams – Part 3
By TC Gill

What was once a playground for innovation and experimentation has now transformed into a strategic battleground where every technological endeavor must align with broader business objectives. This shift marks a departure from the era of tech for tech’s sake to one where every innovation must serve a purpose – to meet the needs of the customer and drive organizational success. As we delve deeper into the following challenge, it becomes evident that several key aspects contribute to its complexity.
The challenge of creating team alignment to business goals
Gone are the days when tech was such a cool thing, we knocked out tech for tech’s sake. It was a bit of a crazy fun party where everywhere you turned; people were creating tech for dubious “good” reasons. Well party time is over. The innovation storm that the tech world resides in just doesn’t have room for doing things because we think they seem kind of funky. We must buckle up and align to the outcomes the business needs, which is strongly underlined by the outcomes the end customer wants!
Here are some of the aspects that need to be considered in order to understand this challenge:

Changing Landscape
Gone are the days when technological prowess alone could guarantee success in the marketplace. Today, tech leaders find themselves grappling with the daunting task of navigating a rapidly changing landscape where the focus has shifted towards delivering tangible business outcomes. The challenge lies in steering the ship away from the allure of technological novelty towards a course that is firmly aligned with the overarching goals of the organization.
Communication Gap
One of the foremost challenges in aligning tech teams with business goals lies in bridging the communication gap that often exists between technical experts and the broader objectives of the company. Without clear and consistent communication channels, team members may find themselves adrift in a sea of technical jargon, disconnected from the larger vision of the organization. It is imperative for tech leaders to establish transparent communication channels that ensure every team member understands how their work contributes to the company’s success.
Vision Alignment
Another critical aspect of the challenge is ensuring that every member of the tech team is aligned with the company’s vision. Without a shared sense of purpose, individual efforts may diverge, leading to fragmentation and inefficiency. Tech leaders must take proactive steps to articulate and reinforce the company’s vision, integrating it into every aspect of the team’s operations. By fostering a shared understanding of the organization’s goals and values, tech leaders can create a cohesive team that is united in its pursuit of success.
Measurement and Evaluation
Finally, aligning tech teams with business goals requires a shift in focus from output metrics to outcome-oriented measurements. Too often, teams are judged solely on their ability to deliver projects on time and within budget, without considering the broader impact of their work. Tech leaders must redefine success metrics to emphasize the value their teams bring to the organization, focusing on outcomes such as customer satisfaction, revenue growth, and market share. By aligning performance metrics with business objectives, tech leaders can ensure that every member of the team is working towards a common goal.
How to create that alignment in your teams
So let me share with you what I think are the strategies for tech leaders to align teams with business goals. Here are a few that I’ve seen employed by tech leaders in my community.
Clarity in communication
Firstly, let’s get great at that thing that flows in all human systems, communication. Create crystal-clear communications on our collective objectives. As a CTO, it’s imperative to ensure that your team is not just aware of, but fully understands the broader business objectives. This means consistently communicating the goals, strategies, and expectations in a clear and concise manner. It’s about making sure everyone is on the same page and moving in the same direction.
Know where you want to go
As the leader in the space, it’s your top priority to reinforce a unified vision. I suggest continuously articulate and reinforce the company’s vision, over and over again. Integrate the vision into every conversation and decision-making process. The goal is to embed this vision deeply into the team’s mindset, so much so that it becomes a natural part of their thought process and approach to work.

Feedback, feedback, feedback
Businesses are a system of systems, and all healthy systems have healthy feedback loops. So, provide ongoing updates and feedback. Keep the team in the loop with regular updates on progress, changes, and any shifts in strategy. This ongoing communication is key to maintaining alignment, as it helps the team understand how their work fits into the larger picture and adapt as needed.
Outcomes are important as well!
Also focus on outcomes, not just outputs. Shift the emphasis from mere output or quantity of work to the impact of that work on business and customer outcomes. Make it clear that success is measured not just by what is produced, but by how it contributes to the company’s goals and adds value to the customer experience.
By implementing these strategies, tech leaders can effectively overcome the challenge of aligning their teams with the business goals, ensuring that every member contributes meaningfully towards the collective success of the organization.
Takeaways
Clarity, communication, and a strong commitment to a common vision are essential for success.
Tech executives may create a course for relevance and resilience by embracing the changing tech landscape and anchoring every endeavour to strategic goals. Leaders build a unified front in which every team member participates meaningfully by communicating openly and relentlessly on the company’s vision.
Furthermore, by redefining success measurements, leaders foster an environment of accountability and creativity in which every accomplishment moves the organisation ahead.
Let us carry on the lessons we’ve learned: true magic is found in transforming businesses, inspiring teams, and improving customer lives. With vision as our compass and collaboration as our guide, let us forge ahead into the unknown, seeing problems as possibilities and crafting a future where innovation knows no bounds.
Author
TC Gill – People Development Coach and Strategist

What are the Top 5 CTO Challenges in Leading Teams – Part 2
What are the Top 5 CTO Challenges in Leading Teams – Part 2
By TC Gill

In the whirlwind world of technology, where innovation and change are the only constants, the role of a CTO transcends mere management. It’s a dance on the razor’s edge of progress, where every step forward is met with new challenges.
At the heart of this dynamic arena is the challenge of leadership — how to guide, inspire, and retain a team of brilliant minds that are the lifeblood of technological advancement. The second part of this series delves into the nuanced world of tech leadership, dissecting the top challenges CTOs face in rallying their troops toward innovation and success.
Looking for Part 1? You can find it right here –> Part 1
Otherwise, dive in.
The challenge of recruiting and retaining top notch people
As we peel back the layers of tech leadership, we uncover a series of intricate challenges that CTOs face in the digital age. These hurdles are not just about technology; they’re about people, processes, and the delicate balance between innovation and stability. Each challenge presents a unique puzzle, requiring a blend of strategic foresight, empathy, and adaptability. In this section, we explore these pivotal issues, offering insights and strategies to navigate the complex terrain of leading tech teams to triumph.

Navigating the Talent War
The tech industry is notorious for its fierce competition for talent. CTOs are often at the forefront of this battle, striving to not just attract but also retain the brightest minds. This challenge is compounded by the rise of remote work, which has widened the talent pool but also intensified competition. Leaders must be adept at showcasing their company’s unique value proposition and crafting a work environment that caters to the diverse needs of today’s tech professionals.
Fostering Innovation While Maintaining Stability
Balancing the drive for innovation with the need for stable, reliable systems is a tightrope walk. CTOs must champion forward-thinking projects and technologies without jeopardizing the core operations that keep the business running smoothly. This requires a strategic mindset, capable of assessing risks and making informed decisions that align with long-term objectives.
Adapting to Rapid Technological Changes
The pace of technological advancement is unrelenting. CTOs must ensure their teams are not only up-to-date with the latest technologies but also proficient in them. This entails a commitment to continuous learning and development, fostering a culture where adaptation and growth are part of the daily routine.
Ensuring Team Cohesion in a Diverse Environment
Today’s tech teams are more diverse than ever, spanning different cultures, time zones, and working styles. While this diversity is a strength, it also presents a challenge in maintaining a cohesive team dynamic. Effective communication, inclusive leadership practices, and a strong sense of shared purpose are essential in unifying the team.
Leading Through Uncertainty
The tech industry is no stranger to uncertainty, be it from market fluctuations, regulatory changes, or emerging competitors. CTOs must lead with confidence and clarity, even when the path ahead is murky. This involves making tough decisions with incomplete information, managing stakeholder expectations, and keeping the team focused and motivated despite external pressures.
The Road to Finding and Retaining Top Talent
So, drawing from my personal lived stories and insights gained from dialogues with fellow tech leaders, lets answer the question of how can we effectively attract and retain top talent?


Enticing Talent with Compelling Rewards
Starting with the obvious, offer competitive compensation and attractive benefits to boot. All leaders want value from their talent and to get that, we have to offer reasonable value in return. i.e. a package that’s not just fair, but also appealing in the competitive tech landscape. You’ve often got to stand out. So, I encourage you to get creative on how you can do that. This doesn’t just include attractive salaries. Throw in a spectrum of comprehensive benefits, and additional perks.
Cultivating an Irresistible Workplace Vibe
Get incredibly intentional about cultivating the right culture. Building a culture that naturally draws in talent is crucial. This means creating an environment that’s inclusive, innovative, and aligns with the values and aspirations of the professionals you want to attract. A really delightful book on this that I’ve read, as well as many of the tech leaders I spoke to is “No Rule Rules” by Reed Hastings & Erin Meyer (the Netflix culture). Never leave culture to chance. Be intentional in its design and maintenance.
Empowering Teams Through Growth Initiatives
See everyone in your team as a unique person in their own right through commitment to their professional growth. Investing in the continuous development of your team not only enhances their skills but also shows your commitment to their career progression. This can be through ongoing training, mentorship programs, and opportunities for advancement. When people feel like they are growing, they feel fulfilled and that not only makes the feel like they belong, but it also creates a gravity that attracts others to want to be part of your team space.
Harmonizing Work and Well-being
Find the right balance of work with sustainable working practices. I really encourage leaders to embrace the principle of sustainable working as outlined in the Agile methodology. This involves creating a work environment that promotes balance, efficiency, and respect for individual needs and boundaries. Also listen and observe when the balance is out. Use this feedback loop as often as possible to tune the efforts of the team to not only serve the value delivered to the customer, but the wellbeing of your people.
Inspiring Passion and Commitment
Don’t just see the work as work. i.e. Something to be ticked off. Great leaders create engagement through making the work purposeful. Ensure you teams understand how their roles contribute to the broader business objectives and the impact on the end customer. i.e. How their work is journeying towards a vision that will make a difference. In addition, encourage creativity and innovation in their approach. When employees feel their work is purposeful and they are part of the bigger picture, their engagement and loyalty to the company increases significantly.
By focusing on these areas, tech leaders can create a magnetic pull for top talent and foster a culture where they choose to stay and thrive.
Author
TC Gill – People Development Coach and Strategist

What are the Top 5 CTO Challenges in Leading Teams – Part 1
What are the Top 5 CTO Challenges in Leading Teams – Part 1
By TC Gill

Questions around leading and management of teams have been on my (and other tech leaders I assume) – specifically, what are the most common challenges? Someone asked me this question, and while I should’ve had it all wrapped up in my head, it kind of stopped me in my tracks. Not because I was stuck for answers, but because there are so many that came to mind. Being the “Chief talking Officer” (CtO) of the CTO Confessions podcast and leading many technical people into the space of leadership – I was properly spoilt for choice.
So, I decided to “go long” with this – with the goal to cover the most important aspects of what the challenges are, and what tech leaders can do to overcome them, covered in 5 parts.
We’re kicking off with a problem that is fairly recent.
The Challenge of Orchestrating Remote Teams
This is any leader’s labyrinth now – not just tech leaders. Unless you’ve been hiding under some very big rocks, a new era unfolded in the world. Many companies were using remote working to some extent, especially in the tech space, but COVID did a number on us. This wasn’t just a change; it was a quantum leap into a new reality for many business functions. Remote became a norm that we had to adapt to quickly.
Looking at the concept of remote work, it comes with a variety of benefits and drawbacks – with the drawbacks’ list now seemingly growing, with research now pointing in a different direction, as well as statements and claims of influential tech leaders. So I’ll focus on the challenges posed by remote and diverse teams, and the biggest problems relating to it.


We lost the art of mingling
This is a big one for me. Remember the good old days when we had watercooler moments and team lunches with actual real people in front of us? Sadly, this seems a thing of the past. Or at least for it to happen regularly. Trying to foster and invigorate the social system and serendipitous moments of people meeting has turned into a challenging high wire act… without a safety net.
UTC, ET, or CST?
Second one added to the challenge cocktail – leaders must be global multi time zone orchestrators. It’s a global thing now. The world got a lot smaller and bigger at the same time, with mornings, afternoons and evenings sometimes all in a meeting at once. This difference in time-zones can be a strain on operations in any team, and can lead to lapses in communication, and lower collaboration.
Trust & Communication
The lack of contact and face-to-face time can be a hurdle in establishing a culture, principles, and some simple common understanding in teams. Add the global-ness into the mix, with the diversity of cultures that all have their own norms – and you’re walking a delicate line in terms of leading. And this is where this whole thing can crumble like a tower of cards – lack of connection gives way to lack of trust, then bad communication, lack of collaboration…well, I won’t keep on catastrophizing – you get the picture.
Now let’s jump to what we can do!

How to walk the leadership walk
So, how do we perform this high wire act of orchestrating remote and diverse teams? What steps can we take to enhance your approach? Drawing down from my personal experience and insights gathered from interviews and meetings with more than 100 tech leaders, I’ve come up with the following list:
- Prioritize the social fabric of your workplace. It’s crucial to put a spotlight on the social dynamics within the team. What I like to call “the social system”. Nurturing relationships and understanding interpersonal dynamics are key to not just productivity, but also satisfaction.
- And on top of that make it real! facilitate real-life connections. Whenever possible, arrange for the team to meet in person. An initial face-to-face gathering, especially an icebreaker event, can lay a strong foundation for future remote interactions. If you can’t do this, I implore you to get creative on how you can do this remotely. Whatever happens, people must get to know each other. As my personal leadership mantra goes: “Relationship first”.
- The third thing on my list is equip your people with the right tools for effective collaboration. The digital toolbox is essential for seamless remote work and maintaining productivity. But again, don’t just throw the tools into the space, think about how they can be used elegantly. Tap into the teams with continuous learning about the way they work, and how this learning can be brought to life to create an iteratively smoother ride for all concerned.
- And finally in the context of remote working, develop skills and processes that make it easy, productive, and fun. It’s not just about being able to see each other on a screen. Cultivating the right skills and establishing robust processes for remote work are critical for success. Don’t leave it to chance. Lead the way. Get people thinking about what’s working well and what’s not. I suggest conducting cyclic remote working retrospectives for learning and adaptation.
Thankfully, many of the tech leaders I’ve worked with and met, work on the said topics in a big way. I hope some of the ideas here inspire you to put a bright spotlight on the topic.
Stay tuned for Part 2, coming next week!
Author
TC Gill – People Development Coach and Strategist

A Guide for Tech Leaders to Boost Team Efficiency and Quality Through Outside Expertise
Articles

John Abadom
General Manager at IT Labs LTD
In the ever-evolving landscape of technology, businesses often find themselves grappling with the challenge of developing innovative software solutions to stay ahead of the competition – and with the advancements made in technology, coupled with the customer and market demands, innovation has turned from goal to a necessity.
For businesses and leaders that lack the capacity to create and deploy software, the journey from conception to execution can be a daunting one. This poses a problem that can be both resource and time-consuming – and one that can be easily solved by finding an external partner that can do this for them – like IT Labs.
Choosing your software development partner is not like choosing a regular vendor for your needs – it’s a strategic move that can empower your business by building resilient, scalable, and innovative applications. By leveraging you partner’s expertise and experience, you’re not just keeping up with the competition in the present – you’re laying the groundwork for a more sustainable future.
What Your Outside Expert Needs to Look Like
Considering the role, the implications, and the potential influence your software development partner might have on business growth, it’s important that you pick the right one. This means that your outside experts need to have the following qualities:








And, of course, there’s always the option of mixing teams – in an era where technological prowess defines competitiveness, the synergy between in-house teams and external expertise becomes a cornerstone for success.
Getting the Collaboration Moving – Process Outline
The process of getting the collaboration moving, it’s important to follow the phases through, as the initial phases are crucial in setting up the collaboration for success.
Our approach for tech leaders wanting to work together in navigate the software development process is listed below:

Step 1 – Define Clear Objectives and Requirements
Before embarking on the software development journey, technology leaders must clearly define project objectives and requirements. This includes understanding business goals, user needs, and desired functionalities. Meticulously documenting forms the foundation of the project.
Step 2 – Assess In-House Capabilities
Tech leaders should evaluate their in-house capabilities and expertise. By acknowledging strengths and identifying potential skill gaps, technology leaders can strategically decide which aspects of the project are best suited for internal development and where external expertise would be invaluable.


Step 3 – Forge a Strategic Partnership
Selecting the right software development partner is paramount and tech leaders should opt for a partner, with a track record of success deliveries, diverse tech capacity and innovation. This partnership should not be transactional but collaborative, where open communication and shared goals foster an environment of trust and creativity.
Step 4 – Collaborative Planning and Agile Methodologies
Work closely with the chosen software development partner in collaborative planning. Adopt agile methodologies that allow for iterative development, ensuring that the project stays on track, and adjustments can be made swiftly. This fosters a culture of adaptability and responsiveness to changing requirements.


Step 5 – Radical Transparency in Project Management
Maintain radical transparency throughout the project. Regular updates, transparent communication channels, and shared project management tools contribute to a seamless flow of information between the in-house team and the software development partner. This not only builds trust but also ensures that everyone is on the same page.
Step 6 – Continuous Learning and Innovation
Encourage a culture of continuous learning and innovation. Leverage the expertise of the software development partner to introduce cutting-edge technologies and methodologies. This not only enhances the quality of the final product but also empowers the in-house team with valuable insights and skills.


Step 7 – Budget Management and Deadline Adherence
Collaborate with the software development partner to establish a realistic budget and timelines. Transparent financial discussions and a clear understanding of project scope are essential. Regularly review progress against milestones to ensure that deadlines are met without compromising on quality.
Takeaways
So, in the ever-evolving realm of technology, a partnership with IT Labs emerges as the linchpin for some technology leaders aiming to stay ahead of the competition. IT Labs unwavering commitment to expertise across diverse technologies, agile development methodologies, and a relentless focus on customisation and scalability positions software development providers like IT Labs as not just a service provider, but a strategic ally.
By emphasising security, ensuring time-efficient development, fostering a culture of continuous innovation, and nurturing collaborative partnerships, IT Labs not only builds applications but also constructs a pathway to sustained success.
In choosing IT Labs, technology leaders not only invest in cutting-edge solutions but also embrace a dynamic and future-ready approach that propels their businesses ahead of the curve.

Author
John Abadom – General Manager at IT Labs LTD

Meltano DataOps Tool for ELT Pipelines




Data is everywhere, but how do we manage it? Working with data and managing it can be a challenging task, and selecting the right data process can be complicated. That’s where Meltano comes in- a powerful open-source ELT framework that can simplify the data-building process.
This open-source ELT framework simplifies the process of building data integration and analytics pipelines. It offers flexibility, extensibility, and a range of features to efficiently extract, load, and transform data from various sources into a target data warehouse. Because of its flexibility, Meltano enables customization and extension of the framework’s capabilities to suit one’s unique needs. In today’s world, overwhelmed with information, data is king- and it’s essential to select the right tools to manage it effectively.
Curious about how to manage data with Meltano? Our latest Re: Imagine Session was held on 31.05.2023 and covered the topic of data and data processing, at which Oliver Tanevski, a Data Engineer from Data Masters, dived deep into the subject of data with focus on Meltano.
Leave behind the overwhelming world of data management and transform your data processing!
Topics covered:
- World of data
- ETL vs. ELT
- Meltano- a framework for simplifying the data-building process
Get ready to elevate your cloud management game!


ReImagine Session - Martin Dimovski Topic Azure Arc, The Future Cloud

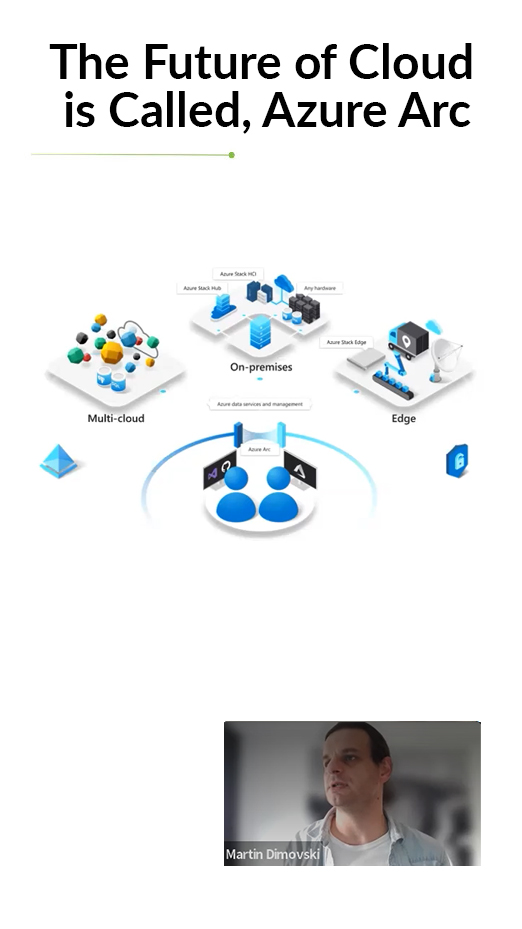
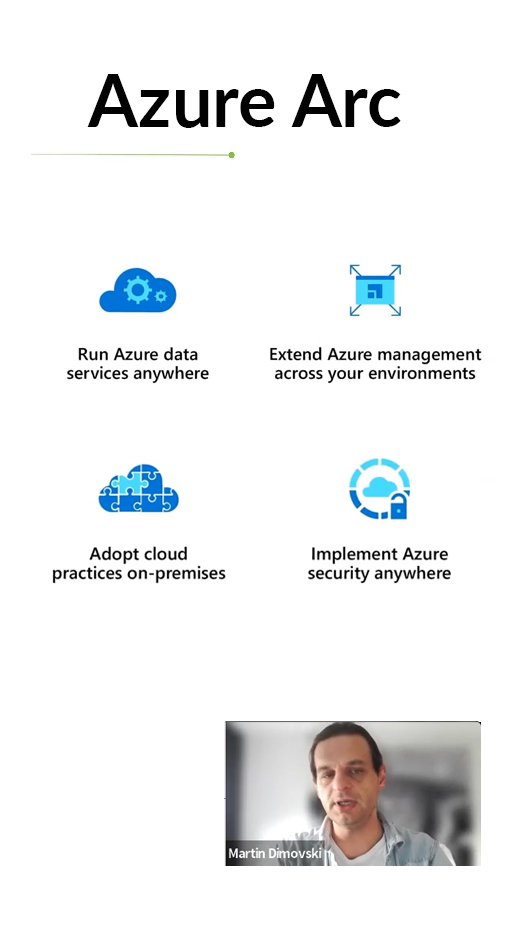
Did you know that the future of cloud management is here? Do you know the benefits of using Azure Arc and how it can manage your environment seamlessly?
In today’s rapidly evolving, ever-changing world, businesses are struggling with the challenge of managing complex environments that span across data centers. Azure Arc serves as a bridge that expands Microsoft’s Azure platform’s capabilities, empowering you to build applications and services that can operate across multiple clouds, at the edge and data centers.
With Azure Arc, you can effortlessly organize, control, and secure Windows and Linux servers, SQL Server, and Kubernetes clusters. Curious about how you can leverage Azure Arc to drive your business into the future? Our latest Re: Imagine Session that was held on 23.03.2023 covered this topic, at which Martin Dimovski (DevOps Engineer with 15+ years of experience) answered these questions and many more about the entire scenario of managing on-premises environments using Azure Arc.
Topics covered:
- Azure Arc Overview
- Managing your environment together
- Azure Resource Manager
Get ready to elevate your cloud management game!