
Caring For the Environment: The Impact of IT Companies
Caring For the Environment: The Impact of IT Companies
Something To Be Done
So, what can companies in the ICT sector do to curb their effect on the environment? A lot, and many of them are already going green or greener, but more needs to be done. The basis on what can and needs to be done varies, and it depends on the size of the company, and the impact it has/it can have on communities – both locally and globally – but in the end, it’s all about initiative and execution, and being a driving force in the quest for creating a better, more sustainable world.
Following, you’ll read more about what can be done, and what we’re doing to fulfil our role as an environmentally friendly company.



Think Globally, Act Locally
The idea of having a month dedicated to the environment was something we at IT Labs would serve our goal, and is an activity that is part of the core of who we are and what we do. We lead by example, and that’s why we decided to spend a month focusing our efforts on making a change in our communities, as something to complement our continuous efforts in becoming a more green and sustainable company.
So look in your communities, in your cities, the areas nearby – what can you do? Carry out a volunteer action? Collaborate with NGOs that tackle issues of environmental nature in communities? Maybe help them with financing? The options are endless, and actions of this type help improve livelihood in communities, and can present a good team-building activity for your employees.
For example, we teamed up with “Ne Bidi Gjubre” – a civil organization that organizes volunteers for cleaning polluted “hotspots” around Skopje – and spent the day with them! We cleaned up an important part of the city in a large, coordinated action which around 70 people, as well as mechanization and help from the ‘PE Communal Hygiene Skopje’. A continuous effort in initiatives like this one, will definitely have an effect on the long run, and help increase environmental awareness not just in the communities, but also among your employees as well.
The Awareness
You see everyone on the internet these days talking about raising awareness on some issues, and these help in keeping the general public informed on all the important events in that sphere, and also educate people on all the progress being made, as well as trying to engage them in activities.
Special attention was paid when we planned this at IT Labs, as we wanted to find a speaker who is deep into the environmental world, who knows all the aspects – policy, activism, and hands-on experience in tackling some of the biggest issues. And, of course, we got Ana Petrovska to hold a presentation and educate us more on the topic of ‘Zero Waste’ and we got into a discussion looking to answer one of the more pertinent questions regarding zero waste: is it possible?




Repurposing, Recycling, Reusing
Just managing how much waste you create and being aware of the whole environmental effect is all fine, but what happens when you lower your effect by simply finding a new place, a new role, and a new purpose for all the items and objects we dispose of daily.
So we challenged our teams to find something old, something that is way past it’s usage date, and find a new use for it!
The results? Well, see for yourself:
Final Takeaway
If you want to do something, you’ll either find a way, or you’ll find an excuse, but considering all we talked about above, an excuse is not really an option, and finding a way is not “easier said than done” anymore. It’s all about perspective, willingness, and the opportunity to do well.
It’s about the environment – and excuses are not an option there.

Growth, Progress, and Success at IT Labs
Growth, Progress, and Success at IT Labs
We’re a people company first and foremost, and the topic of career development is something that is really important. This covers not only the professional development of all at IT Labs, but also their well-being. As IT Labs grows, so does the need to add new positions for incoming talent, and programs for development and growth for our existing talent. In every company, growth is important, but only if it’s followed and matched by people’s growth inside the company.

Talent Development & Seniority
The development of talent starts much earlier than many would expect. It starts with the hiring process, during which we evaluate the candidate’s strengths and weaknesses and we predefine some goals we think and feel the candidate can reach in a certain frame of time. Once the candidate joins and becomes a part of the IT Labs story, this predefined path and goals can, of course, change as time goes on.
So how do we go about picking and nurturing our talent? We have a few “pillars” that help us find people who are a good fit for us:
Hiring by value
We believe that for any candidate to have a successful career at IT Labs, he or she first needs to share the same values that we do. Finding a new member to join teams is down to much more than just having the technical competencies required for a job position – it’s about finding someone who can fit in culturally .
At IT Labs, we’re championing recruitment and development on five pillars: Integrity, Proactivity, Excellence, Innovation, and People. These are at the core of everything we strive to achieve, underpin all our decision-making systems, and influence the way we go about finding suitable talent, and nurturing them.
Maybe add more about the culture, or link to an article that describes the culture – what are the value we share among us and we look for in a candidate?
Nurturing
All the predefined goals and paths designed by the People & Talent Department are subject to change as individuals grow inside the company. Each path is unique, and each professional development plan is designed to fit each individual.
Shadowing
Mentors supervise individuals, in a process that is beneficial for both mentor and mentee – both grow in their own way and develop relationships that improve communication and team spirit.
Training talent, not just going for experienced heads
Cherry-picking for talent is the way to stagnation for any company. Instead of scouting for talent for months at a time, you can spend those resources training someone in-house. At IT Labs, 60% of our talent is homegrown, with training focused on processes, hard skills, communications, and gaps that may be identified beforehand or along the way.
Teaming
Individuals that start in junior roles are nurtured by supervision and feedback sessions which help them grow and refine their skills – up until they’re ready for prime time.
Proper care
Aside from the professional, there’s also the personal – we develop a happiness strategy for every individual to keep them engaged, growing, and happy at IT Labs!

Balanced Professional and Personal Growth
For all the pillars described above, we have a variety of programs and activities are deployed to ensure individuals reach the levels they desire, and to ensure even development in all aspects. These include but are not limited to:
Tech-stack Community
Information, knowledge sessions, databases, skills, articles, pet projects – we have communities for all of these, and individuals can gain access to invaluable information based on experience and know-how, while also get hands-on experience and participate in various projects.
Technical training and courses
Depending on the role, individuals have the opportunity to obtain specific knowledge or skills in various areas, through training programs which provide certificates, which boost productivity and confirm quality standards.
Innovation
We live, breathe, and dream innovation, as we consider it to be the pinnacle of knowledge – the moment you put at work all the knowledge and experience you’ve amassed through the years, to bring to light a tech or solution or method that can help drive progress and innovation even further.
We have innovation sessions, at which we discuss ideas and concepts and we dissect them and see if they actually carry the initial potential, and if they’re worth pursuing!
Certification & Trainings
Certificates are a proof of expertise, and they also pose a challenge for employees – keeping them engaged and learning continuously. With this, they become more confident in their abilities, and look for the next step.
Tech Radar lab
Staying on top with the latest developments in the world of tech, following new releases, and deployment of new tech is crucial for being up to date with the latest trends – both in terms of work and productivity. Experimenting with the latest tech is crucial in the development of a culture that’s driven by innovation and idea-sharing.
Personal development plan
Two times a year, we have performance review sessions, during which we define a detailed personal development plan, with action points and timeframes, and the whole team around you will be engaged in ways that can support you and help you reach your objectives.
Soft-skills training
Your personal improvement is just as important as your professional – as training focused on developing your adaptability, leadership skills, critical thinking, and communication.
Coaching sessions
We have a certified Agile coach, and our employees have one-on-one and group sessions with the coach, helping them develop new attitudes to overcome challenges.
Change this to certification and trainings – there is soft-skills training, but we also provide upskill tech trainings for our employees.
How Each Position Grows
This is the path we have laid out for all our employees, and they usually go as they’re laid out in order, but of course, in some cases, should any team members show extra effort and competence, some of the steps are skipped, and the individual is allowed to move more steps above.
Software Engineer (SE)
1. Junior SE
2. Intermediate SE
3. Senior SE
4. Principal SE
5. Technical Lead
6. Principal Software Architect – PSA
Quality Assurance (QA) and Automation Engineer (AE)
1. Junior QA/AE
2. Intermediate QA/AE
3. Senior QA/AE
4. Principal QA/AE
5. Lead QA/AE
DevOps Engineer
1. Junior DevOps
2. Intermediate DevOps
3. Senior DevOps
4. Principal DevOps
5. Lead DevOps
Business Analyst
1. Junior BA
2. Intermediate BA
3. Senior BA
4. Principal BA
Project Manager
1. Junior PM
2. Intermediate PM
3. Senior PM
4. Principal PM
Career Path Change
All of this sounds defined and predetermined, but what happens if a team member wants to change their career path? The need for change in today’s world of tech is only natural, as new technologies and platforms are always growing and changing, and some do better than others. With all of this in mind, we allow this change to be initiated in one of two ways – by the Department Manager through a knowledge level process, or during a Performance Potential Review, initiated by the Department Manager or the employee.
If both the DM and the employee agree, a Development Plan is created and put into action.

Development Plan
1. Initiation
2. Creation of Development Plan
3. Feedback Session
4. Promotion
Knowledge Level Evaluation Process
A process used to determine and define the seniority level of an employee according to their position and the skill-set prescribed in the job description for the position, in order to perform it with the expected quality.
A KL Evaluation Process can be initiated by the Department Manager on the following occasions:
– Three months after an individual becomes an employee of IT Labs
– During the Performance Potential Review feedback
– Once the DM notices a significant change in the knowledge and skill level of the employee, compared to the previous evaluation
To Sum Up
The importance of having a clear-cut path for every employee and every position is something that not only helps them feel settled, but it gives them a feel of the future, of where they’re heading.
At IT Labs, we know this, which is why we always look for our employees to be at their best – both professionally and personally – as we know that this is the best way for them to grow and develop, becoming future leaders not just in our company, but also our communities and the industry as a whole!

Mind over Matter: Meditating the Noise Away
Mind over Matter: Meditating the Noise Away

It started with a question – one that we’ve all tried to answer and have read tons about:
“What’s stress? How would you describe it?”
And depending on who you ask, you might get different answers. Some of the answers out there are:
- Feeling anxious, unable to focus, fatigue
- An amplified exaggerated emotional response to circumstances that feel out of one’s control
- Pressure to achieve something that we feel is impossible to be done in a certain timeframe or a frame of certain conditions and circumstances
- The thing that makes you feel like you need to run 10km in 5sec
It is about pressure. It is about feeling tension, both physical and mental.

At The Core of it All
The topic of stress in our everyday lives, both professionally and personally, was a topic that we learned a lot about, and also talked about in length, in our Mind over Matter: Meditating the Noise Away session with Sergej Georgiev.
Definitions aside, this was something we did to not just find answers, but to put ourselves in action fighting this other pandemic – stress.
In all the definitions of ‘stress’ that you’ll find online, you’ll see that the concept of time is rarely mentioned, and it is the one that is most important. Most of the time we’re stressed out in the NOW, about something that might occur in the FUTURE.
We’re dreading, anticipating, and coping with an event before it even occurs.

But What To Do About It?
So layers and layers of the what, defining it, but not a single why? Let’s change that.
Whenever we find ourselves in a stressful situation, the big trap that we all fall into is that this situation is somewhat different than anything we’ve faced before. We don’t prospect, we don’t measure, and we don’t assess – we just stress.
Having a black-and-white approach to these situations diffuses stress and keeps your much more relaxed. As Sergej shared his most recent stressful situation, where he got stuck at an airport, forced to take care of bureaucracy which could have made him be late and miss his flight, he talked in length about knowing what needs to be done, and not getting stuck in dreading – instead, put yourself in action.
He tried to get the documents he needed, tried to find a solution, so him and a few other people were allowed to skip the queue and move on. It sounds very simplistic and positive, but that’s not to say that Sergej wasn’t aware of the other possibility – ending up stuck in an airport.
The key takeaway from it all was the realization that it all boils down to what can we do when we’re in a stressful situation. Can we do something about it? If yes, then by all means, we should – if we decide to do so. Let’s get out of the rut.
But what happens when we can’t do something about it? This is a situation which learning how to cope with the circumstances and events is crucial – if nothing can be done to change what’s coming – an undesirable outcome, for example – than the best thing to do is completely accept the situation. This can help us avoid unneeded stress, and instead, focus on what lies ahead, and to try and work out what’s going to happen as consequence, and deal with that. In simple terms – we’re moving on without knowing that we’re moving on, which is the healthy, good thing we should be doing for ourselves.
We need to take a minute to cool off and step back in order to regain the energy to evaluate what can we actually do in the stressful situation. As we recognize the need for this “cool-off”, Sergej as certified professional coach, helps the IT Labbers get there during the Make It Zen sessions, twice a week.
OK, but Why Does This Matter?
The reason we would do well to revert to something simpler, a somewhat binary way of opinion, is that we need to learn how to adapt. Adapt our responses to external stimuli which can stop us in our day to day activities, can make us less productive, and in turn, shove us into destructive cycles – we can start catastrophizing, start dissociating, or even put the blame on someone who has nothing to do with what’s happening to us.
The key is focus – focus in moments when we most need it, but have the least strength to do it. The world has changed a lot, with the lines between the personal and the professional becoming blurred for some, while for others that line is becoming a wedge, a problem that makes them feel that they cannot lead their lives the way they want to, how they want to.
Meditation will probably not cure the world of excessive stress, but at the very least, it can give us the breathing space that we need when the going gets tough – and sometimes that’s more than enough. Sometimes we just need a break.

Conclusion
Stress is not always bad – it can spur us on to create amazing things. That little bit of pressure can be the difference-maker in many cases, but as it seems, excessive stress in longer periods will do more harm than good.
And in a world in which everyone seems to be online, available, and just a few clicks away, we need to find ways to rest our mind, and to keep it out (at least temporarily) of the chaos and all the noise, so that we can keep learning, keep growing, and remain our best selves.

Lawful Processing: How and When to Implement the basis of ‘Legitimate Interest’
Lawful Processing: How and When to Implement the basis of ‘Legitimate Interest’
Author : Ana Zakovska
Executive Legal Advisor and DPO


What is Lawful Processing and where it comes from?
Once the General Data Protection Regulation (EU) 2016/679 (‘GDPR’ or ‘the Regulation’) was announced, introduced, and finally adopted in 2016, it had three focal points:
- the global reach of applicability (beyond the EU members states),
- the never-before-seen volume of monetary sanctions and
- accountability in proving lawful processing by the entities to which the Regulation applied.
In the two years implementation period, in which entities and bodies were obligated to apply or enhance the personal data processing measures to demonstrate compliance, much of how the Regulation’s enforcement in practice would turn out, was still unknown. This was due to the fact that many of the GDPR’s requirements were novelties, so experience, statistics and analysis, were yet to be accumulated. However, since May 25th, 2018, the formal day of its enforcement, the world of privacy and protection of personal data shifted exponentially, affecting almost all industries and economies. The new conditions, nevertheless, positively contributed for creation of further new businesses and opportunities in multiple of areas, such as security engineering, cybersecurity, software development, managed services, academia and education, consultancy etc.
The requirement of lawful processing of personal data, maintained to be one of the more demanding prerequisites to demonstrate its compliance. Article 6 of the GDPR identifies six bases of lawful processing,
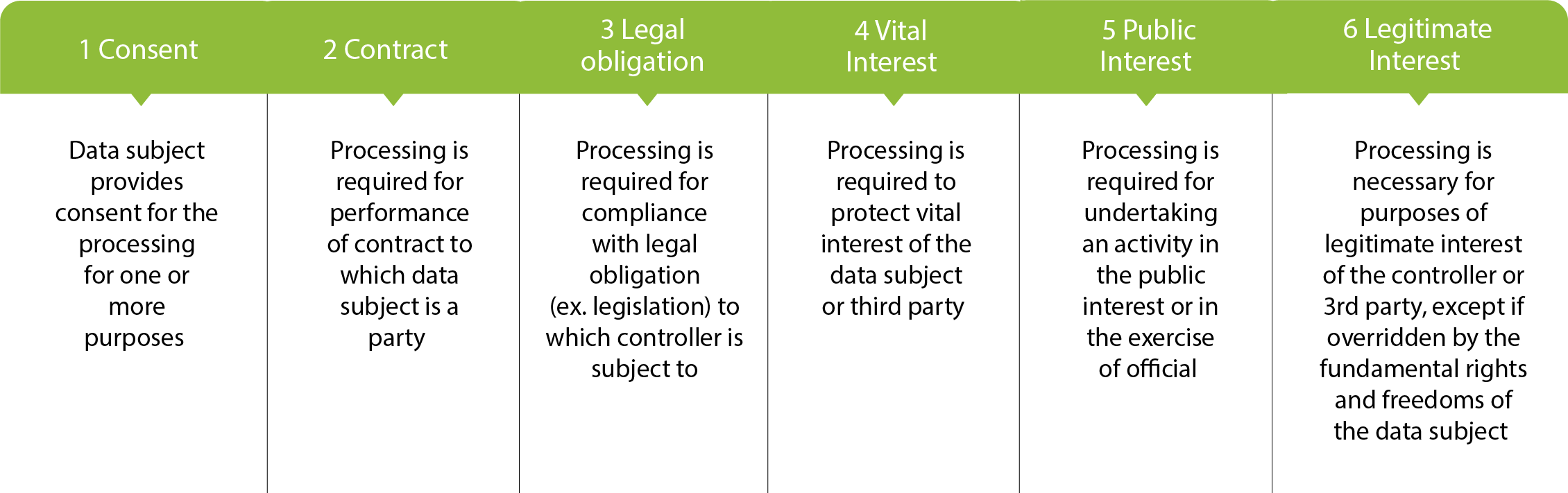
What is the use of ‘Legitimate Interest’?
At inception of the GDPR saga, the ‘star’ basis of lawful processing was the ‘Consent’, since it demonstrated, as never before, that the power lies in the hands of the data subject itself. In effect, using this basis, indeed provided absolute control of data subject to agree to processing and the purposes for it, as well as the right to withdraw such consent at any time. This ‘right to withdraw consent’, left controllers in a peculiar position, since such event would reverse many aspects in their operations and could affect their functioning considerably.
Here, we mostly focus on the private sector and the entities which businesses require data processing for multiple purposes. It became evident, that for aspects where the rest of the lawful basis could not be applied, the basis of ‘Legitimate Interest’ was to be closely examined for application. In particular, for the cases in which there were no explicit contracts regulating some relations with data subjects, or there was no concrete legislation, regulating processing as legal obligation, the basis of “Legitimate Interest’ was the solution.
The delicate aspect of this basis, that made operations to apply it a bit more complex, was that the GDPR did not provide distinct guidance on how to determine proper application of ‘Legitimate Interest’ or what constitutes ‘Legitimate Interest’ between various purposes for processing personal data and various businesses. Also, the GDPR did not provide direct parameters on how to measure and assess those aspects. Only two responsibilities were unambiguously prescribed in the Regulation concerning setting up proper ‘Legitimate Interest’ as lawful basis of processing:
- prohibition to override the fundamental rights and freedoms of the data subject;
- accountability of controller as principle generalis prescribed in Article 5 item 2.
We would derive here from the two above mentioned requirements and expand a practical breakdown to help set up a process for applying ‘Legitimate Interest’, as lawful basis of processing personal data in one organization.
As practice showed so far, ‘Legitimate Interest’ would be mostly beneficial to be applied for processing activities in some cases, within the areas of recruitment, marketing, sales, intragroup administrative transfers, or processing employee’s data which are not related with legal obligation or contract.
When to apply “Legitimate Interest”?
Out of the six lawful bases, the ‘Legitimate Interest’ biggest trait is that, it is the most flexible one, since it’s not interrelated with a particular purpose, thus may be applicable in wide range of situations. To be able to benefit from this flexibility and wield it to one’s advantage, the focus should be to properly document the process, in order to demonstrate that the Regulation’s principles prescribed with Article 5 are sufficiently applied.
Consider the following aspects on ‘When’ to apply this lawful basis:
- When the basis of ‘contract’ or ‘legal obligation’ cannot be applied, but the organization wants to secure long term or reoccurring processing
- When the organization can successfully assess that legitimate interest exists based on proper assessment process (see below)
- When vital interest of the data subject or third party, as well as fundamental rights and freedoms of the data subject are not endangered
- When there is genuine and reasonable expectation that the data subjects would not object such processing and the organization cannot, or does not want to give them upfront control, that can be withdrawn at any time (ex. consent)
- When there is no plan to include special categories of data in such processing, especially data of children, since that requires additional and more rigorous conditions, that may overburden the process, even though it is not explicitly prohibited
- When the organization is not an institution that exercises processing tasks in the capacity of public authority
How to implement ‘Legitimate Interest’?
One of the disadvantages you may consider for this lawful basis, is that it requires a bit more administration and operations in order to properly set up the process. It also requires consistency and continuance in applying the process steps for each new type/purpose of processing, depending on the respective organization’s activities and needs. However, mastering this process will unmistakably provide an advantage to strengthen compliance with the Regulation overall and achieve greater confidence with data subjects, partners and authorities.
Guiding aspects on ‘How’ to do it:
- Train and educate your staff on the subject and emphasize that their continuous contribution to this process is essential for its success (it really is!)
- See ‘When’ to use it, since this lawful basis cannot be applied for all processing activities
- Use it for specific purposes that have distinct material effect and avoid unclear generic business purposes and simplification
- Undertake ‘Legitimate Interest Assessment’ aka LIA (see below)
- Apply all steps for each new purpose within the organization’s operations

What is Legitimate Interest Assessment and its steps?
LIA is a specific risk assessment to determine and document the ‘Legitimate interest’ as possible lawful basis that could be applied, for a particular purpose of personal data processing activity.
It serves to demonstrate compliance with the Regulation and application of its principles, including accountability.
LIA is done by the staff and team who would be actively processing for a certain particular purpose within the organization’s unit or department, or area of operations. The monitoring and audit of the process is usually done by the organization’s Data Protection Officer (DPO), or other responsible person for ensuring compliance with data protection legislation within the organization.
LIA basics consist of three parts: Purpose Test, Necessity Test and Balance Test. Most common and efficient way to conduct the tests, is through a query of questions and answers, that aim to determine the validity of the undertaking. It is essential that the questions need to be answered in clear, unambiguous and above all, truthful manner, as the only way to achieve efficiency of the process and true compliance demonstration.
Such queries may include:
-
Purpose Test (determines if there is indeed legitimacy behind the processing)
- What is the objective of the processing?
- What are the benefits of the processing and who benefits?
- Is the processing ethical and moral? Is it legal?
- What is the impact if processing is not made?
-
Necessity Test (determines if there is basic inevitable need for the processing)
- Can you achieve the same result without processing personal data?
- Are there other less intrusive methods to achieve the same result?
- Is the processing proportionate to the achievement?
-
Balance Test (determines if the processing based on ‘Legitimate interest’ does not override the fundamental rights and freedoms of the data subject)
- What is the relation with the organization and the data subject?
- How will the data subject be impacted by the processing?
- Is the processing high risk to data subjects’ rights and freedoms?
- Is it likely that the data subject will not object the processing?
- What personal data is part of the processing?
- What are the safeguards applied that will secure and lessen the impact of the processing?
If LIA results are not sufficient for a particular assessment of processing and determining lawfulness, an organization might need to undertake a detailed DPIA (Data Protection Impact Assessment).
In conclusion, an organization has to inform data subjects that the basis of ‘Legitimate Interest’ in certain processing activities is applied and elaborate when and how. The most practical way to do that is through its infrastructure of corporate policies, as well as public privacy policies.
28 January, 2022

Relationship of Importance: Stakeholder & Team Engagement
Relationship of Importance: Stakeholder & Team Engagement


Risto Ristov – Project Coordinator & Content Editor
When we talk about a project, we actually talk about an activity to create something unique. You may say that many of the projects are similar in many aspects these days, but each individual project is unique. Uniqueness does not come only in the perception of what the scope is, how the project is initiated, executed, or even delivered, but instead comes from the different characters of people, in this case, stakeholders and the entire team behind the project.
Though sometimes project managers overlook less obvious – yet critical – stakeholders, it is important to consider everyone that is vested in the project. This should be a relationship based on communication, transparency, engagement, and trust.
Effective Communication
Think about what it means to communicate. Do you think it would just be words going back both ways? No, it is a storm of opinions, information, ideas, trust, honesty. Therefore, it is important to realize that communication is not one-sided. It goes both ways, and it is full of stories, testimonies, ideas, arguments, experiences.
I have learned through the years that the best way to keep an effective communication with anyone that is vested into a project is to:
-
Be positive
Try to always enter a communication with a positive mindset. I do not think people like when there’s a negative atmosphere in the air during meetings, and even in formal or informal conversations. This does not mean that you should always be smiling like you are about to shoot a commercial but still, it is nice to have positive attitude as it is very noticeable. A positive attitude can even win you a deal or an argument.
-
Be an echo
You can become a better listener by just being an “active listener”. Active listening is when you repeat or echo a phrase said by those who you communicate with. That will show that you are engaged into the conversation, and it can help you to track the main points of the discussion. Do not expect to do this often, just occasionally would be fine.
-
Be authentic
This is the most important one. You just need to be you. Not a performer, not a pretender, not even a plastic you. Just you will be fine. You would learn that by just being you, you can build trust and engagement very easily, and this will allow people to be more open and share their ideas and thoughts, as well as concerns.
-
Be a listener
To be understood, you need to understand first, meaning you need to listen. I am not saying that listening will keep you from expressing your ideas or opinion but instead it will help you understand the other side, the different perspective. Once you understand other perspectives you will be in a better position to share your ideas or thoughts.
-
Be a mirror
One of the ways to connect with people is to mirror what they do. Most people do this naturally without even realizing they are doing it, but it can surely help to raise engagement. Like with echoing, you need to be careful not to overdo it and end up playing a game of see and do.

I can tell you from a personal experience that a successful relationship with stakeholders is down to skillfully striking a balance between all these ways meant to facilitate communication. On the project, I have always been myself, without any need to pretend or to figure out excuses that will not get me into trouble, but instead, being truthful, positive, and transparent.
There are a lot of tools that we use and that also give us the chance to put in practice any of the ways mentioned above during the various project cycles. We are currently using Microsoft Teams and Skype for an ongoing regular communication with each other. I know there are more tools out there and whichever you choose to work with will not matter if you do not practice some of the principles I mentioned above. No tools are a substitute for proper communication and good approach.
Transparency
Did you know that transparency is defined as “the quality of being done in an open way without secrets?”
In a study I have read (Kelton Global in a 2018 study), it is found that 87% of workers admitted that they want their company and people to be transparent. 80% of the respondents wanted to know more about the organization’s decision-making. And when you look this from a project perspective you would soon realize that it means a culture of open communication and visibility within stakeholders or a project team or even an entire organization. It is often the case of being honest with your stakeholders about the project and the team itself.
Lack of transparency can cause distrust among stakeholders or even resentment. Inadequate or poor communication is a major cause of project failures. Transparency is not a one-size-fit-all approach, as it differs from client to client or industry to industry.
From a personal experience I have learned that to increase transparency you need to make sure that people understand their tasks. Stakeholders or the project team needs to understand the ‘why’ not just the ‘what’.
On my project, I have communicated openly with my stakeholders and explained changes very thoroughly so that we may have an open communication. This did not happen overnight. It took months to get to a certain level but at the end it gave me an outcome of trust that I am sure every manager wants to build. I am also always open for any kind of feedback that comes from any of the stakeholders, since I am doing this with honesty, I too expect honesty and sometimes might even hear something I do not prefer but it is a step to learn and improve.
Project transparency needs to be supported with tools that make collaboration and communication easier. Since our teams are distributed, online tools are necessary. To provide visibility into the project pipeline, we use Azure DevOps Server or Team Foundation Server. Every team member including clients can see what the status of different tasks is, whether new bugs have occurred etc.
Transparency will allow to increase people’s engagement but will also help to eliminate productivity killers.
Engagement
Managers often depend on people to respond to the outputs and benefits that they deliver. People will only respond if they are engaged.
Engagement is critical. It is important that stakeholders understand why we exist, where do we want to go, and how we are going to get there. Furthermore, it is essential that stakeholders are aligned with and bought into the strategic direction of the company so that they can become advocates that can help achieving the mission and vision.

We may think that stakeholders can be made to respond positively to a project, but the truth is that managers frequently have no formal power of authority and therefore must rely on engagement to achieve the objectives. To bring up engagement, you need to understand people. Once you understand them, you will clearly see a path towards multiple options and ways you can use to increase engagement.
Each one of stakeholders is important and you must let them know. You need to make sure they feel that way. With that in mind, allow me to say that it will not be long until they become your brand ambassadors. In terms of the project team, make sure you do a lot of activities like team building, or team hangout, to keep the team engaged and motivated.
Trust
The only secret to retaining stakeholders is quite simple indeed. Maintain quality relationships that are built on mutual trust.
There are many ways to build trust and some of those include being reliable. You need to show everyone that is vested in the project that they can rely on you, in good or bad. Being transparent as a way of building trust is especially important. I am always open with my stakeholders and that proved to be highly effective in decision-making. Proactivity is a strong characteristic of building trust as you will not wait for the stakeholders to come to you but instead you will be reaching out. We are all busy and I know time is of the essence but being available for your stakeholders will let them feel valued.
Always remember that trust is a two-way street.

Conclusion
In the end, effective engagement with your stakeholders is all about situational leadership without losing sight of the big picture. This is the bottom line towards which all project managers must strive and something that managers must aspire towards.
Risto Ristov
Project Coordinator & Content Editor

Breast Cancer Awareness
Deconstructing the Fear of Breast Exams


Bisera Samardjieva
Talent Acquisition Intern
Busting the Fear of the Dreaded Breast Exams
Every year, we dedicate October to raising awareness on the effect of breast cancer, and what can be done to help tackle this disease, which affects millions of women around the world every year. The truth is, even with all the access to information, there are still a lot of misconceptions and myths regarding everything related to breast cancer and breast exams, and it’s understandable. They can be scary and nerve-wracking.
Are you plagued by the idea of getting a professional breast exam; the paralyzing fear of the results turning up positive always there?
You are not alone in that fear; the phenomenon is more commonly referred to as breast cancer screening anxiety and it is connected to various aspects of breast cancer screenings, which may include pain, invasive procedures, and the possibility of getting a false-positive result.
The Psychological Effects and What Could be Done
A study done by Lee et al., showed that most of the people had their anxiety triggered by unknown results of the screening. To add, a significant percentage of people were anxious about the procedure, specifically, a mammogram in the study, being painful.
However, the study also concluded that prior education on why mammograms are useful, as well as, the course of the procedure, helped in easing the anxiety of the patients. Being informed and educated on all the steps which you will be needed to go through helps in easing the uncertainty and the fear when stepping into a doctor’s office (Lee et al., 2016).
It’s crucial to acknowledge the exhibition of anxiety at the thought of undergoing a test that could serve life-altering news is normal in those circumstances. However, that anxiety should not stand in the way of patients getting a proper breast cancer screening.
First off, besides professional breast exams, conducted by a medical professional, the first step of prevention is conducting regular, monthly self-examinations. Aspects that are particularly important to remember are that those breast exams should not be done during your menstrual cycle since your breasts are tender and swollen, as well as more lumpy than usual; this can lead to unnecessary panic and distress.
It is best to conduct the self-examination a few days, or a week, after your menstrual cycle. Self-examinations not only help in the prevention of complications, but regular self-exams also aid in further familiarization with our bodies, which in turn makes it easier to catch slight differences in our breasts, whether that be puckering, swelling, redness, or lumps. All these need to be thereafter examined by a medical professional.
If you have felt a lump or noticed a change in your breast, it is important to not panic immediately. Statistics say that most, 80-85%, of breast lumps are benign, which means they are non-cancerous, especially in women under 40. However, the next step should always be going to a medical professional to get an opinion. The process usually requires consulting with your GP who will give you a referral to a breast specialist.
So, what happens after you get your appointment with the breast specialist? The good thing is, for women under 40, usually, an ultrasound is used instead of a mammogram, which makes the procedure entirely painless.


The Examination: Step by Step
Once you arrive for your appointment you will usually be questioned on the reason for your visit, if and how you have noticed any abnormalities in your breasts, as well as the date of your last menstrual cycle. Afterward, the doctor will first off do a manual breast exam; this can include you, the patient, either sitting or lying down on a bed. The doctor will examine all quadrants of the breast tissue, which means they will palpate all-around your breasts, as well as check the tissue under the arm. This is so they can check for any kinds of lumps or abnormalities.
Afterward, they will darken the room so they can perform an ultrasound. This is an entirely painless procedure in which you will only be lying down, while the doctor does everything else. After slathering some ultrasound gel over your chest, the doctor will carefully go over your breasts using the ultrasound probe. By doing this, your doctor will get visual images of your breast tissue and will be able to carefully examine the internal situation. If there are no abnormalities, the examination will end here and you will be sent on your way.
There is a chance, if the doctor discovers some type of lump, for you to need to undergo a biopsy. While there are several types of biopsies, all of them are virtually painless after the anaesthetic kicks in. Being told that you need to conduct a biopsy can be nerve-wracking and anxiety-inducing. However, keep in mind that the biopsy can give priceless information on the nature of the lump or tissue the doctor wants to examine. This way, there will be no doubts whether there should be a cause for further worry and tests.
Biopsy
The biopsy is usually done in the same room where the ultrasound took place; the abnormal breast will be sanitized and then numbed using a local anaesthetic. There are different ways to conduct a biopsy, depending on what kind of lump the doctor is examining; but don’t let that worry you. You won’t be able to feel a thing past the slight pinch of the initial needle! However, don’t be alarmed when there is slight bruising on your breast after the biopsy. This is due to the injection as well as the trauma done to the tissue by the biopsy procedure. This will go away in a few days. There may be some soreness once the anaesthetic wears off, but it’s not acute pain, do not worry!
Waiting for the biopsy results can be very anxiety-inducing. However, there are of course strategies you can do to stay on top of your anxiety and stress. Some of them include trying to reduce your anxiety by meditation or mindfulness, as well as seeking social support from family, partners, or friends. It’s always better to talk to someone about your worries than let them fester.
To add, try keeping busy during the waiting period. It’s easy to fall into a waiting rut, where you sit by the phone, anticipating the dreaded call. Stay on top of tasks you need to accomplish, do chores, read or take a walk, anything that will help keep your mind off the different scenarios it’s trying to take you through. And remember, more often than not, breast lumps are non-cancerous.
The Long Wait
However, even if the dreaded news arrive, remember that the earlier an illness is diagnosed the easier and more effective treatment will be. That’s why regular breast examinations are key when it comes to treating breast cancer!
Getting regular ultrasounds and/or mammograms will help doctors stay on top of even the subtlest changes in your breast tissue, which means treatment will be conducted much sooner.
Not only that but getting regular professional breast exams will help you keep your peace of mind; knowing that everything looks normal and well will help you feel less anxious about your health, as well as less anxious when going for your next appointment.
And, men, don’t forget that you also need to conduct regular examinations of your breast tissue. So, go and schedule that doctor’s appointment and protect those breasts!
Bisera Samardjieva
Talent Acquisition Intern

Caring For Employees Through a Screen

Caring For Employees Through a Screen with Frosina Zafirovska
How To Provide Proper Care in Extraordinary Times and Circumstances
As a psychologist and a People & Talent officer, I’ve spent many hours trying to figure out ways in which I can make the life of the employees within IT Labs easier, more fun, and get them to be the best version of themselves – learning, creating, and becoming better every day. There are all kinds of scenarios in my head that I prepared for, but a global pandemic was definitely not one.
This last month, we had our second health month at IT Labs, and it provided the People & Talent Department with much needed insight into what works and what doesn’t in these extraordinary circumstances – which is why I felt compelled to write this piece.
Activities, Activities, Activities
How do you develop an activity that will be beneficial to your employees – but through a screen? How do you even approach that?
Rethinking activities is the first thing that comes to mind, and why not? Contrasting times, different approaches, right? Well, the truth is, drastic changes are not needed, but moving on from some of the events and activities developed in the 90s – some of which are still present today – is one of them. When an activity doesn’t produce any engagement, and interest in your employees, scrap it, ASAP, otherwise you risk undermining all your efforts – once bad or bland things starts rolling out of the People & Talent departments, employees will lose interest in anything you have to offer them, and this will lead to alienation, distancing, and sooner rather than later people will not want to stay with your company anymore.

The solution? Don’t complicate things – in these times of isolation, do the things that will get people to feel connected with the world. Organize activities that will engage them with the world, and show them that they’re doing something worthy. Something that will make a change. At IT Labs, for example, we’re focused on projects and charities that make a difference in communities.
The reason why this kind of activities works is because it unites the whole bunch under one common cause – and a sense of unity creates a sense of belonging which goes a long way in countering the devastating effect the pandemic has on the everyday lives of your employees. No need for crazy, out-of-the-box ideas that might work – stick to the ones that will show your workers that their efforts inside the company can have a strong, positive effect on the world outside.

Old School Does The Trick Sometimes
Working remote comes with its own set of benefits, but also drawbacks – and as more people choose to work out of office, HR departments around the world will need to adjust their strategies. Does this mean throwing old plans in the bin and starting all over? Of course not, but a slight tweak and going back to basics might do the trick.
The core of the issue lies in the drawbacks that come with working remote: lack of community and team spirit, more distractions, lack of motivation, risk of burnout.
So how can we help ease these and ensure employees are at their best? By giving them the main thing that’s missing in their work – a human moment. Yes, as leaders of People & Talent departments it’s our duty to stay in touch with everyone and check in on them every now and then, but how do we make it in a way that makes a difference? By having an open, heart to heart conversation with every single person. Poke and prod, spend 15-20 minutes to talk about all matters work and life related, show interest in their life, and of course, provide support and assure them that you are here for them to talk about any subject and matter that bothers them – a pure human moment can do a world of good for anyone struggling with alienation, isolation, and the ‘new normal’.
The point is, we have an obligation to keep things professional, but that doesn’t mean we can’t lend a hand to anyone in need, especially in our work environment – it’s not our job, it’s our duty.
The Future of Employee Care & Satisfaction
About the future, there seem to be two opinions that circle – some say that the future is extremely near, and we would do well to prepare for it now, while others say that the future is now, and that what we do right now is the thing that matters.
Both are true, but in their own, unique way – yes, today is the tomorrow we didn’t expect for another 5 or 10 years, but at the same time it’s as if there’s more to what can be done, so we look ahead. Hybrid models of working will become the new normal, and with that, leaders of people departments will need to find a way to keep employees happy, fulfilled, satisfied, and secure. And in the end, whichever system you have deployed and available to your employees, keep the following in mind – you can invent new activities and ways to satisfy your employees, you can try the craziest, adrenaline-fueled stunts, but nothing will have the same long-lasting, deep effect as a pure human connection.
Conclusion
Circumstances can and will change, environments will change, people will change – but the one thing that shouldn’t change is our desire to be the best versions of ourselves, by enabling and motivating others to be the best themselves.
Frosina Zafirovska
Frosina Zafirovska
Chief People and Talent Officer

Jack of All Trades Or Specialists? The Future of IT Through The Lens of A BA

Jack of All Trades Or Specialists? The Future of IT Through The Lens of A BA
Erin Traeger
Business Analyst
There’s new tech, new ways of doing stuff, new platforms, new toys – but the debate regarding specializing or sticking to a jack-of-all-trades style is still ongoing. Now, before anyone gets excited, I’m not here to put it to bed – I’m here to add more oil to the fire.
Just kidding – I simply believe that the perspective is way too simplistic than the reality. Of course, there’s the need for both, and yes, sometimes techies, leaders, and tech leaders can do both, depending on the project. There is no such thing as one-size-fits-all in the world of technology.
As I’ve been in this line of work as a BA for more than a decade now, I also have experience as a Product and Project Manager, and I think it’s time I shared my two cents on the matter. I will not preach, nor give you a recipe for success – I’ll just write about what I’ve learned in the world of tech, regarding that title above.
No more, no less.


Delegating Responsibilities
Point for jacks. Delegating responsibilities is something that’s easier if you know what you’re getting yourself into as a team leader or a project manager. No, I’m not talking about just having some idea of how the project will go, with estimates and everything. I’m talking about having a good grasp on how much of an effort your team will need to put in to get the project over the line.
Specializing in a few technologies or programming languages is all fine, and yes, that experience and knowledge will surely help, but imagine a team leader who knows the core problems of a project and is able to assess them better.
As a BA, you don’t really have a lot of delegation to do, you’re in a way just running point, but as a product and project manager, it’s crucial.
Knowing How to Approach Problems
Approaching IT problems is all about perspectives, and the more diverse your skill set, the easier it will be to see the pain points of a project. This isn’t just about planning and execution; this is also about setting up the project in which your team can be not just effective, but also learn and connect.
I’ve learned things I never thought I’d have the chance to use, but you’d be amazed how something you consider irrelevant or impractical can actually be your rescue when facing complex problems.
Furthermore, this helps add another dimension to the way you’re leading teams, and helps with delegating! Sure, knowing the core of the matter and having a sense of it is always nice, but why not use this knowledge and put it to something like nurturing. You can measure out your approach – go with passive listening and guide your team with questions, or you can engage and guide by doing. The correct way? Take a look at your team, and you’ll know – what they need and how they work will give you the answer right away.
Working as a BA, product manager, and sometimes project manager, this can be achieved if one is ready to walk that thin line between having a front-row view of the project, and looking at it from the side – a mix of objectivity and subjectivity.
Leading By Example
Autonomy in teams is something that’s desired, of course, but teams have leaders for a reason, as sometimes they have to step in and guide when someone hits a snag.
There isn’t one way to do this, and the key to figuring out the core of the problem is balance – being decisive, but not dismissive.
Having your own MO is always nice – you know how things go, how they should be done, and you feel in control, right? But think of this – leading by example is not just about showing the best way something can be done, it’s about stirring debates, enabling team members to share ideas and engage in processes – which all can contribute to better product development and deployment.
Blindly following established processes can really spell doom for a project, and can actually hurt team dynamics and relationships.
See what works, don’t just decide before you listened and tried – adapt, improvise, overcome!
Flexibility
I know, I know, it’s something that’s talked about a lot. But I’m here to talk about the flexibility towards clients. Agile is a methodology that is applied to teams working on the project, but can it be applied to clients? Yes, and to a great extent.
Sometimes, behind a project you have one client, and sometimes there are multiple stakeholders. All this can present a challenge, as there are multiple ideas about how to conceptualize and execute the development process, and sometimes these can be conflicting. For this, specializing comes to the rescue.
Having something as a specialty can help you not just with understanding the project and envisaging it, but also help you convey your messages and recommendations to the client. Simple, short explanations that will help the client understand what you’re trying to achieve, and visualize your proposed changes and additions.
And at the core of this lies the relationship you form with your clients – sometimes you might click, at other times you’ll need to engage: ask questions, ask explanations – whatever it takes for you to get a better understanding where the client is coming from.
Mutual understanding lies at the heart of client satisfaction.
Conclusion
We have this idea that methods, concepts, and MOs should become simpler, more concrete, and more fixed in a way – and it’s time we worked on changing that and accepting the looming reality: flexibility in methods and approach is what will drive efficiency, innovation, and success in the world of technology.
My advice to all the BAs, project and product managers out there, and the ones aspiring to be that one day: stick to what you know, but don’t forget the following – anyone you meet knows something you don’t, and sometimes that knowledge can be the thing that makes a breakthrough in your projects!
Erin Traeger
Business Analyst

Innovation has its bread and butter in one concept – an idea

Innovation has its bread and butter in one concept – an idea.
Blagoj Kjupev
Blagoj Kjupev
CIO at IT Labs
Before the car was a car or the iPhone was an iPhone, it was an idea. So, everything manmade comes from the idea, which is based on a need or improvement, but yes – the idea is the foundation for anything related to innovation. But, the word idea to a lot of people sounds intimidating. Not in the sense that they cannot come up with one, but because of the socially applied pressure that only good ideas need to be heard – thus instantly placing their idea on hold. And the objective truth is that every idea is good at some point in time, the real question is if the time for that idea has come.
On ideas and all things related, we sat down with Blagoj Kjupev, our Chief Innovation Officer, and talked about ideas, how to spot a good one, how to unearth them, and why engaging your teams to voice ideas is important.
ITL: IT Labs has been in the tech industry since 2005. Where were you then – and where are you now as a company? Where is IT Labs positioned at the moment in the world of software development?
Blagoj: Since IT Labs’ beginning 15 years ago, we’ve been cooperating with companies and businesses from various industries, located around the world. We started off with smaller projects and smaller teams, but over time, we developed our portfolio in several sectors and areas, and this allowed us to grow and expand as a company. As we rose through the ranks, we quickly became the main driver in the digital transformation of our partners. Now, we offer wide-spectrum products and services: from advising and consulting on business strategies, all the way to managing a full software-development process and cycle, including maintenance and support.
After opening our first dev hub and establishing and got a foothold in the market, we proceeded with expanding in the Americas, Western and Eastern Europe, covering business centers in the USA, UK, and the Netherlands. We have just opened an office in Serbia, since we identified that it has a strong IT capacity and a very developed business culture that will help us diversify, grow, and develop as a company.
ITL: What kind of clients do you work with? What kind of services do you offer them?
Blagoj: We offer a wide array of services, from deploying business agility to defining business strategies. Specifically, services regarding business analysis, product architecture, development, testing, DevOps, and cloud strategy. These include security services, which come in handy for clients with partial or non-existent coverage in this area. Our experts analyze security systems and their structures, and develop client-specific strategies.
With tech development and changes in the market, the services we offer also diversified and expanded, so now, we also offer AI and data science-related services as well. We have a team of experts in data analysis, data science, and AI who can transform clients’ product revenues by optimizing data flows and data analysis. Thus, leading the client with data that serves their unique position in the market. What sets us apart from the competition is the fact that we don’t just offer technical services. We offer highly skilled and professional teams which have worked on big projects, their success was measurable and tangible, and have helped clients develop and grow. There’s no need for the client to waste time and energy in putting together and nurturing teams to carry out tasks in various departments. We do all this for them, and then some. Our teams of professionals are focused on exceeding the expectations of the client, and we achieve this by treating people as the most valuable asset. We can guarantee quality in delivery and efficiency for our clients.

ITL: What makes an idea a good one?
Blagoj: The person giving the idea and the people listening to that idea. That’s it, there must be a good match. An idea in itself cannot be good or bad. It’s the room that the idea is presented in, figuratively speaking of course. Somebody’s bad idea can be someone else’s spark into an amazing adventure ending with a very successful product or service. Think of anything produced and developed by humans. How much of that was a complete, producible idea in its inception? If I had to guess it’s in the 0.00 margins. This means that on each idea an additional work has to be conducted to have it fully developed and understood by investors and companions that will help in its development.
Ideas are an amalgamation of all our experiences, references to things we’ve seen, read, watched, listened to... When a problem is presented, our mind unconsciously goes through all of that and finds an approach to help us solve the problem. So, we all have ideas, every day. It’s just that most stay silent and undeveloped due to different reasons. Our focus during the incoming period will be to help our colleagues feel comfortable expressing and develop their ideas.
ITL: So, ideas need to be voiced more often. As the Chief Innovation Officer at IT Labs, how will you change that?
Blagoj: : After many discussions with my colleagues from the marketing and other departments, my expectations were confirmed that we have the manpower, know-how, and creativity in our teams to take ideas and turn them into real-life projects and products. We’ll further increase the number of activities that are taking place, to include brainstorming and open discussion events in which we’ll speak about solving already identified problems, existing solutions, new technological breakthroughs, and develop ideas that might turn into something amazing.


ITL: What is the potential of the engineers to generate ideas in areas where ITL is present?
Blagoj: I’d like to redefine the question a bit: we are not focused on collaboration with engineers only, but the focus is to engage all the employees in ITL, as they’re all welcome to participate and share. Ideas can come from any person, no matter their background or field of work, so there’s no one excluded. Moreover, in the beginning, we’ll be focused on collaboration internally in our company and soon we’ll open the possibility to collaborate with idea authors from everywhere. The local idea capital in geographical regions where we are present, I believe is not utilized properly and the initial goal will be to scratch below the surface using new approaches and reveal potential gems.
ITL: Okay, we all have ideas, right? How do you decide which ones are worthy of being considered? How do you separate the “hmmm, that might work” from the “that’s just crazy”?
Blagoj: Via open discussions and for some areas by having a guest who is great in specific areas of expertise which is touching the idea. Sometimes from one idea, there will be more ideas emerging, sometimes we’ll together with the author decide that the time is not right for that idea. Only through open discussions and brainstorming we can reach a common understanding of the real value of any idea and agree on next steps.
Blagoj Kjupev
Blagoj Kjupev
CIO at IT Labs

Achieving work-life balance: A Project Manager's Journey
Achieving work-life balance: A Project Manager's Journey

Zorica Redzic
Project Manager at IT Labs
With everyone around the world struggling to cope with the pandemic in the last year and a half, the talk about work-life balance – already a hot topic – turned from something we talked about, to a pressing issue.
The reason? Well, the lives we loved living were no longer an option. We had to adapt to the new normal, and in it, achieving work-life balance is something that can be the difference between living life to the best of our abilities and settling for something that is way below what we’re capable and deserve.
Like most, I’ve spent many hours figuring things out and finding my way around in these extraordinary circumstances, but something along the way just “clicked”. I was where I needed to be, and I was comfortable – work was getting done, and life was lived.
Just to put it out there – this is NOT a self-help article. I won’t tell you what to do, nor how to do it, as achieving work-life balance is different for everyone. This is just my two cents and my experience – a brief outlook on what has worked for me, Zorica Redzic, as a person and a project manager.
Let’s go.
On Reassessing Priorities
Dreaded, foreseeable, yet paramount – reassessing and resetting priorities. I, for one, dove head-first into this by pulling all the aces I had up my sleeves. Improvising left and right in all aspects of my work – from managing people to getting things done.
Did it work? Yes.
Was it the best way? Read the answer to the previous question.
While winging it has been a success for me, it doesn’t mean that it will be for anyone, nor should it be considered as a long-term solution. That’s why I set about reassessing priorities but from a laxer perspective. I started out by rooting them in general concepts, all captured in one simple personal motto that gave me both the freedom and energy to keep going – “there’s always work to be done, but don’t get stuck doing something that doesn’t fulfill you”.
I know, I know – it’s a cliche. But it works. I didn’t reevaluate my job position or the company I worked for – I did it with my tasks and day-to-day tasks. I simply focused more on the things I wanted to do, and treated it as a reward and an energy booster to do the things that were both time and energy-consuming.
This balance between the wants and the needs is the core of what I as a project manager found to be the golden ratio in my endeavors. In the bigger picture, this helps you establish a reward system – by you, for you – which can be a never-ending source of motivation.
The reason I talked about all this? The same thing applies to real-life situations. And this is not only something we need to do, it imposes itself as something we should definitely strive for, as focusing too much on the work part means leaving out the life part – and that’s a recipe for disaster. Rinse-repeat the same thing, and voila – a step closer to balance.


Finding Opportunities to Grow
The invisible pink elephant in the room – with the world at a standstill, how do I keep growing? How do I find the pockets of space, time, and energy to maintain my learning curve?
I didn’t just drown into all the material available on the web. Because learning opportunities don’t just come in the shape of courses, meetings, feedback sessions, webinars, and workshops – it’s about making the space for it.
Making the time and space to learn and develop as a project manager sounds impossible, right? But it isn’t. I set about delegating tasks and responsibilities to willing team members with the goal of enabling them to grow into their roles. I was then left with pockets of time and space in which I was free to do develop.
This was somewhat unexpected, but then it hit me – ‘you need to give in order to receive’ – an adage as old as time itself resonating in extraordinary times. This all led me to a simple conclusion – the circumstances have changed, but our values and principles need not. We still need to do what we’ve always been doing. It’s just the shape and this uncomfortable feeling around it all that somehow paints it all black.
Dear Project Managers, keep diving into your leadership and team-growing methods.
The Little Things That Make A Big Difference
As creatures of habit, any change to our everyday activities can be debilitating, and detrimental to our mental health and productivity. We all have our small morning or mid-day rituals, which whether we like it or not, play a big role in how we feel and how we go about our days.
I thought of my habits as being bound by certain processes and external circumstances, when in fact, I was bound by doing them. For example, getting up everyday and going through the whole work-prep was really important to me – washing up, working out, dressing up, breakfast, putting makeup, etc. – but is there a point to all these when you don’t go out and don’t have the chance to experience them in the same way as usual?
The answer is yes.
As a project manager, I figured sticking to my habits and going through my morning plan kept me at my best, and not just in terms of productivity, but also in leading. As someone responsible for the well-being of his team, leading by example is the way to go. No, I’m not talking about pretending everything is fine and ignoring all the problems – I’m talking about showing your team that when the going gets tough, putting in the work to maintain your ways and can be incredibly liberating and comforting.
A morning person or not, we all do certain things that give us that sense of stability, a certain way in which we start and go about our day, a ritual of sorts – and while it’s something we rarely pay attention to, it can do wonders in helping us be at our best selves day in, day out.
Managing on Video
Even with all the tips and tricks, the structure, the awareness, the leading, things will go sideways from time to time. Your team(s) will suffer from dips in motivation and creativity, and sometimes will struggle – and the same can happen to you.
And then, there’s the worst-case scenario – you’re having a rough day, and a member of your team is going through something as well. When I first got in this kind of situation, I was literally at loss for words – and action! I was unable to even comprehend what was happening, and had no idea how to resolve this. I didn’t have the person in front of me, that direct, tete-a-tete moment was lacking, and I was unable to even get out of my own difficult situations.
After winging it a few times I realized that the thing that will work time and time again is to have a purely human moment. Listen, reflect, share, offer support, and make the necessary steps you believe need to be taken to come to a resolution. And of course, assurance. Don’t forget that this void of activity is affecting everyone, and that sometimes team members just need to know that it’s okay for them to take a break and reflect.
Showing understanding is one thing, acting on it is the hard part – that’s what will help you keep your team happy, and bring solidity in these times of uncertainty.

Final Words
For anyone jumping into this article with the hope of learning a groundbreaking idea – I’m sorry. The internet is just filled with hundreds of thousands of pieces on how to stay productive, how to keep teams productive, how to stay happy, etc. – and this piece is not that.
Yes, our professional and personal lives changed drastically – but does this mean we have to change our values and what we do? No – we just need to change the way on how we do it.
So Project Managers and not-project managers, there’s no need to reinvent the wheel, or our lives for that matter. We already know what sticks, so it might be best to stick to what we know.
Zorica Redzic
Project Manager at IT Labs